2022年 11 月 30 日 ChatGPT 横空出世已经过去 3 年了,2023 年 OpenAI 再次给世界一震撼,重磅发布了 GPT-4,而2024 年 OpenAI 仍然一枝独秀,给 AI 的发展带来了两个新的方向,一个是视频生成,一个是推理范式,前者的代表是 Sora,后者的代表是 o1。时间来到 2025 年,OpenAI 终于不再一枝独秀,迎来众多挑战者,全球 AI 可以说是呈现百花齐放的状态,有 Google 和 Anthropic 等闭源模型的兴起,有 DeepSeek、Qwen、Kimi、GLM、Minimax、Mistral 等开源模型的觉醒,当然也有 Llama 4 开源模型的落寞。
本文将按照时间顺序带你一起回顾一下 2025 年 AI 圈每一个核心大事件、技术突破及社会影响。
DeepSeek R1 火爆全球

2024 年 12 月 6日,OpenAI 重磅发布 o1 系列推理模型,把大模型的发展从仅使用系统 1 思维(快速、自动、直观、容易出错)发展到系统 2 思维(缓慢、深思熟虑、有意识、可靠)。而就在 2025 年 1 月 20 日,中国 AI 创业公司 DeepSeek(深度求索)发布了其最新一代开源模型 DeepSeek R1,该模型也是一个推理模型,在基准测试中其表现与 OpenAI 的 o1 模型相当,但价格却显著低于 o1(大概是其 1/30)。这一事件迅速在全球科技界引发了海啸般的反应,被西方媒体和战略分析师称为 AI 领域的“斯普特尼克时刻”(Sputnik Moment)。R1 不仅在性能上紧追 OpenAI 的顶尖闭源模型,更重要的是,它打破了关于大模型训练成本的固有认知。
DeepSeek R1 的核心突破在于其极致的“推理-成本”效率比。在过去几年中,行业普遍遵循“Scaling Laws”(缩放定律),即通过指数级增加算力和数据量来换取性能提升。然而,R1 的技术报告显示,其训练成本仅为 600 万美元左右,而同期美国科技巨头(如 Google、OpenAI)训练同级别模型的成本往往高达 1 亿美元甚至 10 亿美元量级 。
DeepSeek R1 的成功主要得益于以下几点技术创新:
混合专家模型(MoE)的极致优化:通过改进的路由算法,大幅提升了参数激活的效率,使得模型在保持庞大参数规模的同时,推理计算量显著降低。
强化学习与思维链(CoT)的深度融合:DeepSeek 利用 DeepSeek V3 结合其他开源模型(如 Qwen、Llama)生成的 80 万条思维链数据进行强化学习微调,这种“蒸馏”策略极大地提升了模型的推理能力,而无需从头进行昂贵的预训练 。
MIT 协议的开源策略:完全开放的商用协议使得 R1 迅速成为全球开发者的首选基座。仅在发布后的一个月内,HuggingFace 上基于 DeepSeek R1 的衍生模型就超过了 90,000 个,这一数字甚至超过了 Meta 的 Llama 系列 。
DeepSeek R1 的发布一周后,DeepSeek 应用程序升至 App Store 排名第一,到目前为止 DeepSeek App 的日活在 2500 万左右。DeepSeek 是一个模型即应用的典型代表,没有花一分钱用于用户增长,全部来自于口碑和自传播,反观 Kimi、豆包、Qwen则不同,花了很多流量费来获得用户。DeepSeek 也让 Kimi 团队改变了投流的逻辑,转而把更多钱投到了模型研发以及开源上,后来 Minimax 和智谱也走上了开源之路,中国开源模型正式崛起,到 2025 年底 Minimax 开源的 M2.1、智谱开源的 GLM4.7以及 Kimi 的 K2 模型都曾登顶开源模型榜首。而字节的豆包在 DeepSeek 爆火之前妥妥的国内第一 AI Appp,结果却被 DeepSeek 截胡了,但他们在 2025 年仍然稳打稳打,除了跟进 OpenAI 的产品路线之外,也做了一些自己的产品创新,在2025 年底豆包宣布日活突破一个亿,也可以说可喜可贺,成为了国内的实至名归的国民级 AI 应用。
而西方国家也因 DeepSeek R1的效率产生了巨大的恐慌,芯片股一夜暴跌,Nvidia 的市值在数日内蒸发了约 5000 亿美元。市场的恐慌逻辑在于:如果 DeepSeek 证明了通过算法优化可以用极低的算力成本达到顶尖性能,那么全球对高端 GPU(如 H100/H200)的无止境需求可能会被重新评估,AI 泡沫论一度甚嚣尘上。但回过头看,这其实是典型的“杰文斯悖论”, DeepSeek R1 不是在缩减市场,而是在降低准入门槛,让更多人以更低的价格可以使用上顶尖的 AI 模型,AI token 消耗量反而变得更多了,而英伟达的 GPU 机器也卖得更多了。
“星际之门”(Stargate)计划:5000 亿美元的算力长城

在 DeepSeek 带来的冲击余波未平之际,2025 年 1 月 21 日,美国政府联合产业界正式宣布启动 “星际之门”(Stargate)计划 。这是一个由 OpenAI、SoftBank、Oracle、Arm、Microsoft 和 Nvidia 共同组成的超级合资项目,旨在未来四年内在美国本土投资 5000 亿美元,构建前所未有的 AI 基础设施 。
基础设施的物理化挑战 Stargate 计划的核心是一个总功耗高达 10 吉瓦(GW) 的超级数据中心集群,这一数字相当于数个中型国家的发电量总和 。
选址与能源:项目主要选址在得克萨斯州(Abilene)、俄亥俄州及中西部地区。为了满足巨大的电力需求,项目规划中包含了核能(SMRs)和大规模可再生能源的配套建设 。
资金结构:SoftBank 孙正义担任合资公司主席,负责资金统筹;OpenAI 负责技术运营;Oracle 负责物理数据中心的建设与云基础设施管理 。
执行阻力:尽管蓝图宏伟,但项目在 Q1 并非一帆风顺。Bloomberg 在 8 月曾报道称,由于市场不确定性和 AI 硬件估值波动,项目初期面临资金未完全到位的风险 。此外,密歇根州等地居民对数据中心的高能耗和水资源消耗表示了强烈抗议,导致部分审批流程受阻 。
OpenAI 的第二个 Agent 产品发布:DeepResearch

2025 年2 月 2 日,OpenAI 重磅发布大受办公人群喜欢的 Agent 产品:DeepResearch。
如果说 ChatGPT 改变了人们获取信息的方式,那么 DeepResearch 则试图彻底重塑知识工作者的生产流程。与之前的“聊天机器人”不同,DeepResearch 被定义为一个全自动的深度研究助手。用户不再需要进行多轮对话引导,只需给出一个模糊的高层指令(例如:“分析 2025 年东南亚光伏市场的竞争格局及政策风险”),DeepResearch 便会自主拆解任务。
它能够并行调用浏览器访问数百个网页,阅读长达数百页的 PDF 财报和法律文书,并通过内部的 o1 推理模型对由于信息源冲突导致的数据差异进行交叉验证,最终生成一份包含图表、引用来源及深度洞察的万字报告。这是 AI 第一次让初级分析师、律师助理和许多案头研究员感到了切实的职业恐慌。原本需要人类花费 3-5 天整理的信息,DeepResearch 仅需 10 分钟。
Anthropic 发布编码 Agent:Claude Code

2025 年 2 月 24 日,Anthropic 重磅发布 Claude Code,这是一个深度集成在终端(Terminal)的全栈研发 Agent,其核心能力在于对整个代码仓库(Repo)的全局理解力和自主行动力:
终端原生(CLI-First):Claude Code 可以直接在命令行运行。你只需要输入 claude code “修复这个 repo 里所有的类型错误,并为核心模块编写单元测试”,它就会自主运行测试、读取报错、修改代码、再次运行测试,直到所有 Test Case 通过。
架构级重构:凭借 Claude 系列超大的上下文窗口(Context Window),它可以一次性理解数百万行代码的复杂项目,并进行跨文件的重构,而不仅仅是修改单一函数。
自我修正:它不再需要人类充当“Debug 循环”的一环。它会自己写代码,自己跑代码,自己修 Bug。
从现在看,Claude Code 对 Cursor 带来了有不小的冲击,不少用户退订了 Cursor 的订阅,转到了 Claude Code 上来,据说 Claude Code 为 Anthropic 在 2025 年带来了 10 美金的营收。
另外,还有一个小插曲,Claude Code 的创建者 Boris Cherry 和产品负责人 Cat Wu 还曾中间短暂了离职了 Anthropic 并入职了 Cursor,短短几周时间就又回到了 Anthropic,也不知道中间发生了什么。
Manus


2025 年 3 月 5 日,一家在武汉的创业公司蝴蝶效应发布一款 Agent 产品: Manus,该产品能够调度不同的工具解决复杂问题,其在 GAIA 等基准测试中表现出 SOTA 的性能。该产品已经发布引发国内外的关注和讨论。国内很多媒体称之为 DeepSeek R1 之后的另一国运级别的创新,但它的创新不是底层模型创新,而是产品创新。如果你仔细研究过 Manus 这个产品,会发现其实它本质其实就是 OpenAI 的 DeepResearch,只是表现形式不同,做个不一定恰当的类比就是 DeepSeek R1 之于 OpenAI o1。今年 7 月份 Manus 团队总部离开武汉,搬去新加坡,收到国内一帮人的批评和指责,当时我还特意写了一篇文章来分析这家公司的底层逻辑:别只盯着 Manus “跑路”,它超前的产品认知更值得关注。
今年 12 月中旬,Manus 宣布年度经常性收入(ARR)已突破 1 亿美元(上线 8个月后)。另外,一些技术指标:
- 消耗总 token 量超过 147万亿 token
- 创建了超过 8000 万台虚拟计算机
就在我写这篇文章的早会上,Meta 以数十亿美元收购 Manus 的公司蝴蝶效应。这是 Meta 成立以来第三大收购,花费仅次于 WhatsApp 和 Scale AI。收购完成后,蝴蝶效应公司将保持独立运作,创始人肖弘出任 Meta 副总裁。这里我们也恭喜 Manus 团队成功上岸。

配图来自于今年7月 Manus 团队对谈YouTube 联创陈士骏。
左起依次为:季逸超(Manus 联合创始人、首席科学家)、肖弘(Manus 创始人兼 CEO)、陈士骏、张涛(Manus 联合创始人,产品负责人)
GPT-4o 原生图像生成因吉卜力画风火爆全球

OpenAI 发布 GPT-4o 原生图像生成功能,因其效果拔群,在推特上造成了病毒式的传播,一小时内 ChatGPT 新增 100 万用户,火爆程度堪比上一波的 DeepSeek R1 发布的盛况。
当时我也写了一篇 GPT-4o 的使用教程:GPT-4o 引爆全球吉卜力风格生图潮流!附10+玩法与教程。
Llama 4 的“落寞”:开源王者的尴尬处境

时间来到 2025 年4 月 5 日,备受期待的 Meta Llama 4 终于发布。然而,与其前作 Llama 3 发布时的全网狂欢不同,Llama 4 的登场显得有些“生不逢时”。
扎克伯格坚持了大模型“算力暴力美学”的路线。Llama 4 405B 及其更大版本的模型在各项基准测试中确实表现优异,甚至在某些多模态指标上超越了 GPT-4.5。但市场对此反应冷淡,原因主要归结于 DeepSeek R1 在年初引发的那场“效率地震”。
Llama 4 遭遇了几重困境:
架构的滞后性:在 DeepSeek R1 证明了 MoE(混合专家)架构结合极致优化的推理管道可以用极低的 VRAM(显存)运行高性能模型时,Llama 4 依然主要依赖庞大的稠密(Dense)架构。这导致 Llama 4 的部署成本极高,中小企业根本跑不动,而大企业则更倾向于自己蒸馏 DeepSeek 或使用闭源 API。
社区的分流:开源社区的热情已经转移。开发者们发现,基于 DeepSeek V3/R1 进行微调(Fine-tuning)的性价比远高于 Llama 4。HuggingFace 上,针对 Llama 4 的魔改模型数量增长缓慢,而 DeepSeek 生态却如日中天。
实测表现不如预期:虽然官方指标上 Llama 4 还可以,但网友使用后的实际表现落差却很大,有网友指出其操控了基准测试,结果就是让社区由热切期待到普遍失望的快速转变。
OpenAI 发布 o3 与 Codex CLI
2025年 4月16日,OpenAI 正式发布 o3 系列推理模型和开源编码 Agent Codex CLI。OpenAI o1(2024 年末)是 RLVR 模型的首次演示,o1 的核心创新是 Test-time Compute(测试时计算)。当你提问时,模型会强制暂停,展开一段漫长的思维链(Chain of Thought, CoT),尝试多种路径,自我纠错,然后给出答案。
但o3是一个明显的拐点,你能直观地感受到这种差异,RLVR 不仅被用来优化“下一个词”,还被用来优化“下一个动作”。另一个是它对 Tool Use(工具使用) 和 Environment Interaction(环境交互) 的掌控力。
有人说o3应该直接叫 GPT-5,因为 GPT-4到 o3 的能力提升和 GPT-3.5到 GPT-4的提升一样大。从现在看OpenAI 并没有这样做,而是选择把 o3.1 作为 GPT-5发布,结果可想而知。
开源模型 Qwen3 发布
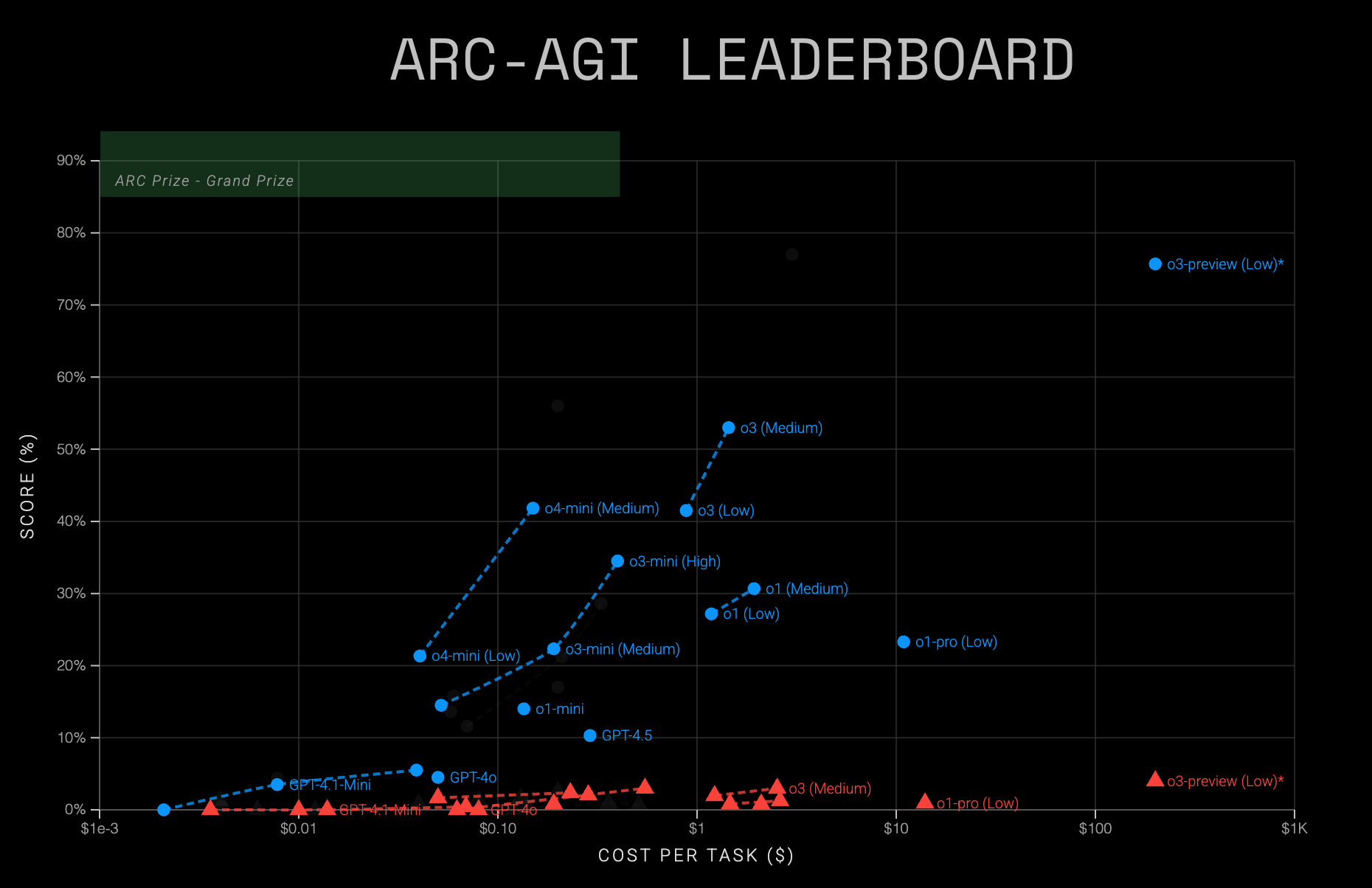
2025年 4月19 阿里巴巴千问团队开源 Qwen3 系列模型。继年初 DeepSeek R1拉近了开源与闭源模型的差距后,Qwen3 将这场战役推向了高潮。其旗舰模型 Qwen3-235B-A22B 在代码、数学、通用能力等基准测试中,展现出与 DeepSeek-R1、o1、o3-mini、Grok-3 及 Gemini-2.5-Pro 等顶级模型极具竞争力的结果。
OpenAI 云端 Agent 产品 Codex 发布
2025 年 5 月 16 日,OpenAI 推出全新 Codex,一款云端AI软件工程代理。基于codex-1,它能并行处理编码、修复Bug、提PR等任务,助开发者提升效率。
就像OpenAI 联合创始人,特斯拉前 AI 总监 Andrej Karpathy 在 2025 2025 LLM 年度回顾所说的那样:OpenAI 在这点上搞错了,他们将 codex / agent 的工作重点放在了从 ChatGPT 编排的云端容器部署上,而不是 localhost。虽然在云端运行的智能体集群感觉像是“AGI 的终局”,但我们生活在一个能力参差不齐的中间过渡期和缓慢起飞的世界中,因此将智能体直接运行在计算机上,与开发人员及其特定设置携手合作更有意义。Claude Code 掌握了正确的优先级顺序,并将其打包成一种美观、极简、引人注目的 CLI(命令行界面)形式,这改变了 AI 的样子——它不仅仅是一个像 Google 那样你去访问的网站,它是一个“活”在你电脑里的小精灵/幽灵。这是一种全新的、独特的与 AI 交互的范式。
从现在看,OpenAI 显然搞错了顺序,直到 2025 年 9 月份 GPT-5 发布的时候他们才开始频繁的迭代 Codex CLI,当然从结果上看还不错,现在 Codex CLI 和 Claude Code 以及 Cursor 成为程序员和长品经理最喜欢的三个工具。
谷歌发布 Veo3
2025年 5月20日,谷歌在Google I/O 2025大会上发布 视频生成模型Veo 3,它是全球第一个实现了音视频直出的视频生成模型,也就是说可生成带有音频的视频片段(例如街头的汽车噪音、鸟鸣、人物对话等)。就如 Google DeepMind 首席执行官德 Demis Hassabis 所说:我们正在“走出视频生成的无声时代”。
反观 OpenAI 的 Sora 自去年首秀以来风光不再,直到4个多月后 OpenAI 才发布 Sora 2,补齐该能力。另外有一点值得说,现在在 Google lead 视频生成项目的人之前是 OpenAI Sora 的头之一,离开的原因据说是 GPU 资源分配的问题,OpenAI 把核心力量投入到了模型智能上面,所以才有了现在的 O 系列的推理模型,而Google 这边管够,人才给、GPU 也给,这效果就来了。不仅仅如此,这也为后来的 Nanobanana 的爆火埋下的伏笔。
Google Genie 3:交互式世界模型的诞生
2025 年 8 月 4 日,Google DeepMind 发布了 Genie 3 。 Genie 3 不仅仅是一个视频生成模型,它是一个“交互式世界模型”(Interactive World Model)。
- 可控虚拟世界:用户不仅可以生成 3D 环境,还可以像玩游戏一样在其中进行实时交互(如驾驶、飞行)。
- AGI 的踏脚石:DeepMind 明确表示,Genie 3 的目标是训练 AI 智能体(Agents)在虚拟世界中学习物理规律和因果关系,从而最终迁移到现实世界。这是通往具身智能(Embodied AI)的关键一步 。
GPT-5:多模态推理的“博士级”表现
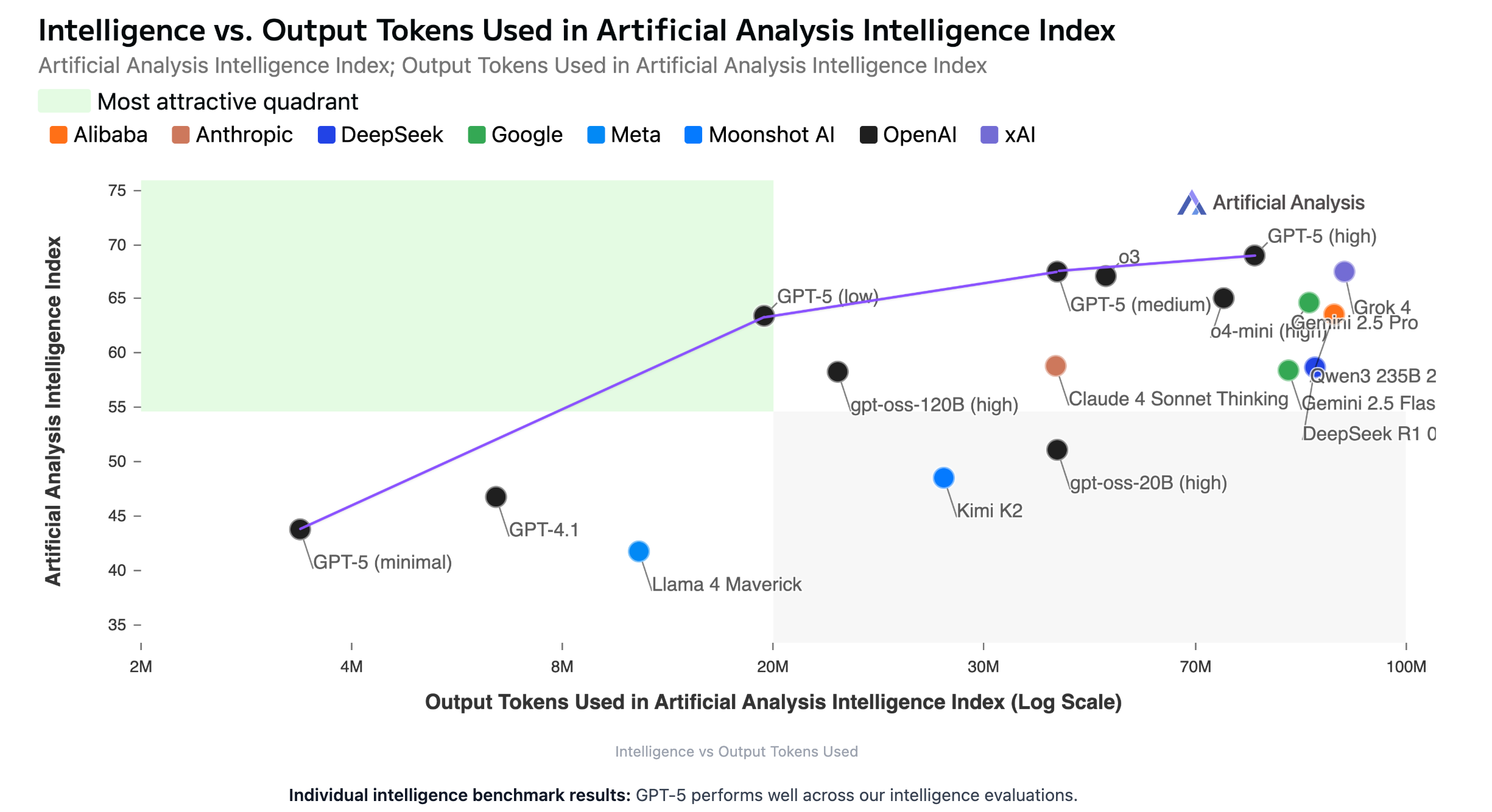
2025 年 8 月 8日,OpenAI 正式推出了备受期待的 GPT-5 。 核心能力有以下几个:
- GPT-5 在编码、数学、写作、健康和视觉感知等多个领域树立了新的标杆。
- GPT-5 本质是个路由模型,系统自动判断并选择最合适的模型,实现了速度(GPT-5-Instant)与深度思考(GPT-5-Thinking)的统一。
- GPT-5 在减少“幻觉”、遵循指令、减少谄媚方面取得了重大进展,使其在写作、编码和健康咨询等核心应用场景中变得更加有用和可靠。
谷歌 Nanobanana 图像模型发布

2025年 8月 26日,Google 发布图像生成模型 Gemini 2.5 Flash Image,又名 Nanobanana。该模型还在 LMArena 上测试时就引起了社区的极大关注和热捧,上线后基本霸榜图像编辑和生成模型的榜单了,特别是图像编辑领域更是大幅领先。
核心能力有以下几个: 1.图像一致性保持的能力非常强大。它可以将同一个角色放置在不同的环境中,在新场景中从多个角度展示单个产品,同时保留主体。 2. 基于自然语言描述的图像编辑。 3.融合了 Gemini 的世界知识。 4.它能理解和融合多个输入图像。
从这些核心能力可以看出它为什么火爆全球,OpenAI GPT-4o原生生图能力火爆全球是因为娱乐至死,而Google 的Nanobanana 的火爆显然是因为带来了生产力的巨大提升。
OpenAI 发布 Sora2
2025年10月1日OpenAI 发布Sora2,一开始仅上线美区 iOS端 APP,且是邀请制。上线3天后便登顶 AppStore榜首。Sora2 不是个纯粹的模型,而是一个产品。Veo3基本做到了10s左右视频生成能力的上限了,Sora 2很难做到远远领先,所以他们另辟蹊径搞了一个社交裂变的办法,让用户可以上传一段简短的视频/音频,将他们的肖像(外观+声音)插入到任何 Sora 生成的场景中。
有人说 Sora2是昙花一现,月留存仅有8%远远低于 TikTok,但内容的积累需要时间,如果你现在去 Sora2上看看,会发现它目前要比刚上线的时候丰富多了,你也能刷一会,甚至会倾向于用它来制作好玩的视频,然后发布到其他社交平台上。至于 Sora到底行不行别着急下结论,让子弹再飞一会。
Google 发布 Gemini 3 Pro
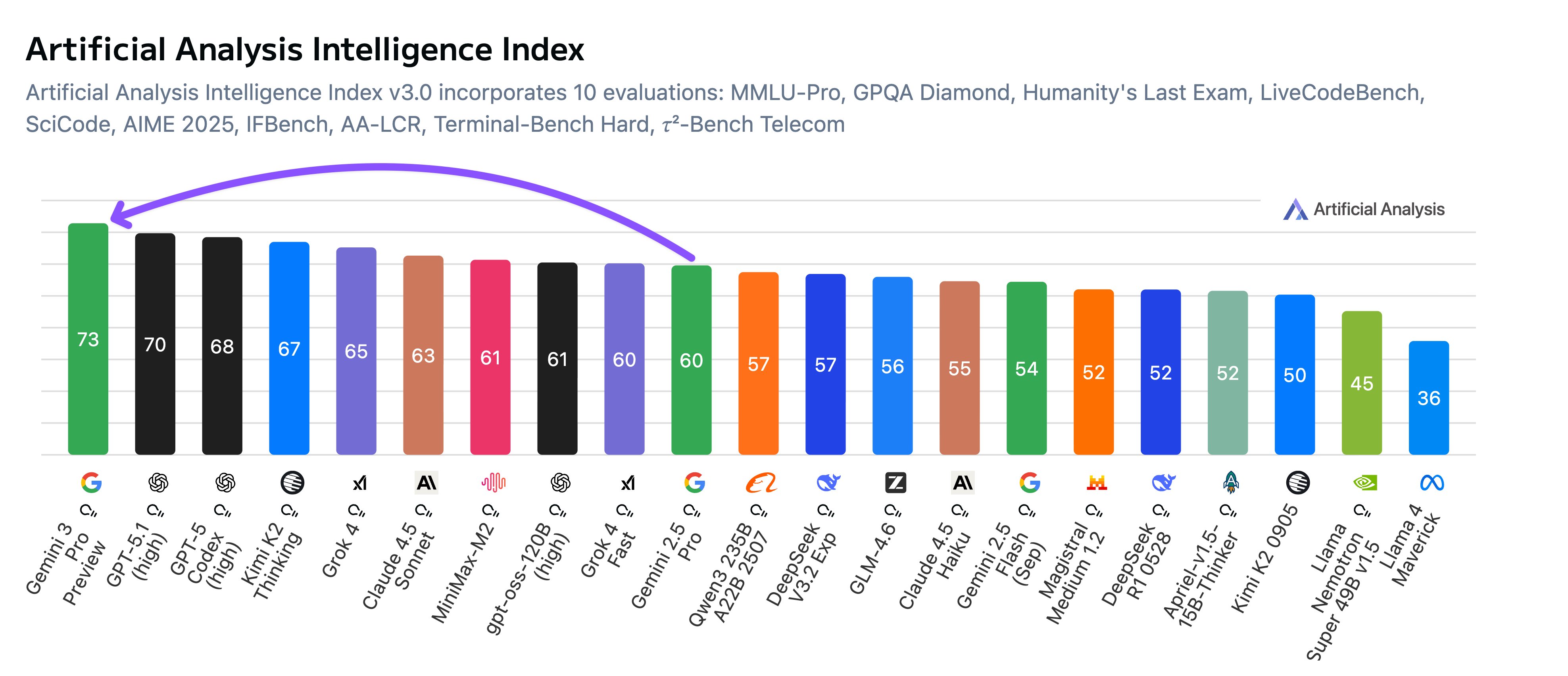
2025年 11月18号,谷歌正式发布全球最强模型 Gemini 3.0 Pro,它在所有主要的 AI 基准测试中都显著优于 2.5 Pro,且基本都处于榜首的位置,包括视觉能力、数学、编程、Agent、视频理解等等。但一个指标稍微弱于Claude Sonnet 4.5 (77.2%)和 GPT-5.1 (76.3%)就是 SWE-Bench Verified,这个指标上得分 76.2%,这个指标特别重要,特别是对 Vibe Coding。
Google 发布 Nanobanana Pro
2025年 11月 20日,谷歌发布 Nanobanana Pro。与注重速度和性价比的 Flash 版本不同,Pro 版本引入了“思考”能力、搜索(Search Grounding)以及高保真 4K 输出等高级功能。该模型的三大核心优势在于:
- 具备思考能力:能够理解和推理复杂的提示词。
- 搜索溯源(Search Grounding):利用 Google Search 获取实时数据以生成准确的图像。
- 高质量输出:支持高达 4K 分辨率的图像生成。

相对于 nanobanana ,这次 Pro的生图模型自带思考能力,对的,你没看错一个图像模型也具备了思考的能力,这是范式的进化。之前的生图模型都是在前面引入一个文本模型来优化用户输入的prompt以达到最佳的生图效果,而现在有了这个 Pro模型后 这种pipeline不需要了,一个独立的图像生成模型也能思考了。另外,这次还有一个给生产力带来极大提升的能力是图上的文字基本全能写对,写对办公人群简直是质的飞跃,制作PPT、漫画、绘本从未如此简单。
当然,成本差异也比较大,nanobanana一张图大概2毛钱,而 nanobanana Pro 一张图要接近1块钱,接近4-5倍的价格。反观国内,豆包生图基本是目前 TOP1的水平,但距离nanobanana Pro的差距之前3-6个月的差距。
最后
以上就是 2025 年 发布的 对整个 AI 行业影响深远的大事件。如果你想要对 2025 年的所有的核心事件(包括一些细节,比如 OpenAI 的产品功能、Anthropic 的发布、开源模型的发布等等)进行速览,我也整理了一张图供你查看,你也可以直接去这个我一直维护的 AI 大事件追踪网站进行查看。今天是 2025 年最后一天班,也提前祝大家元旦快乐,在 2026 年更健康、更从容、更有收获。
