本文探讨了如何通过快速微调开源嵌入模型,以更低的成本和更高的准确性超越专有模型(如 OpenAI 的 text-embedding-3-small)。文章首先介绍了微调的基本概念,然后通过实验展示了在简单问答任务中所需的微调数据量。作者强调,利用开源模型和可扩展的基础设施,初创企业可以在没有大量用户数据的情况下,快速启动并优化其模型,进而形成数据飞轮效应。
微调的重要性:
- 微调可以使模型更好地适应特定任务,提供比现成模型更好的性能。
- 数据飞轮的概念:用户数据的积累可以不断提升模型的表现,从而吸引更多用户,形成良性循环。
数据集和模型选择:
- 本文使用 Quora 数据集进行训练,该数据集包含标记为“相似”和“不同”的问题对,以训练模型识别文本相似性。
- 选择合适的基础模型是关键,作者推荐使用具有开放许可证的模型,这些模型的权重可以下载和修改。
基础设施和资源管理:
- 微调模型需要显著的计算资源,Modal 提供的自动扩展基础设施可以按需使用 GPU,降低成本。
- 作者建议设定明确的训练目标和资源限制,以优化训练过程。
实验结果:
- 实验表明,经过微调的 bge-base-en-v1.5 模型在识别文本相似性方面表现优于 OpenAI 的基线模型。
- 即使使用仅几百个样本,微调后的模型也能显著降低错误率,表明微调的有效性。
未来方向:
- 文章最后指出,下一步应将微调过程自动化,以便持续收集数据并迭代模型,从而实现系统的持续改进。
快速微调击败专有模型
只需要几个示例,微调后的开源嵌入模型就能以更低的成本提供比专有模型(如 OpenAI 的text-embedding-3-small)更高的准确性。本文将介绍如何使用 Modal 创建这样的模型。首先,我们会讲解微调的基础知识。然后,我们会讨论一个实验,研究在一个简单的问答应用中需要多少微调数据。
为什么要微调
开源模型让你起步
定制模型至关重要。这是 Netflix 不断推荐更好的电影和 Spotify 找到适合你每日播放列表新歌的原因。通过跟踪你是否看完选定的电影或是否跳过一首歌,这些公司积累了大量数据。他们利用这些数据改进内部的嵌入模型和推荐系统,从而提供更好的建议和用户体验。这甚至能吸引更多用户参与,进而积累更多数据,进一步改进模型,形成一个被称为数据飞轮的良性循环。
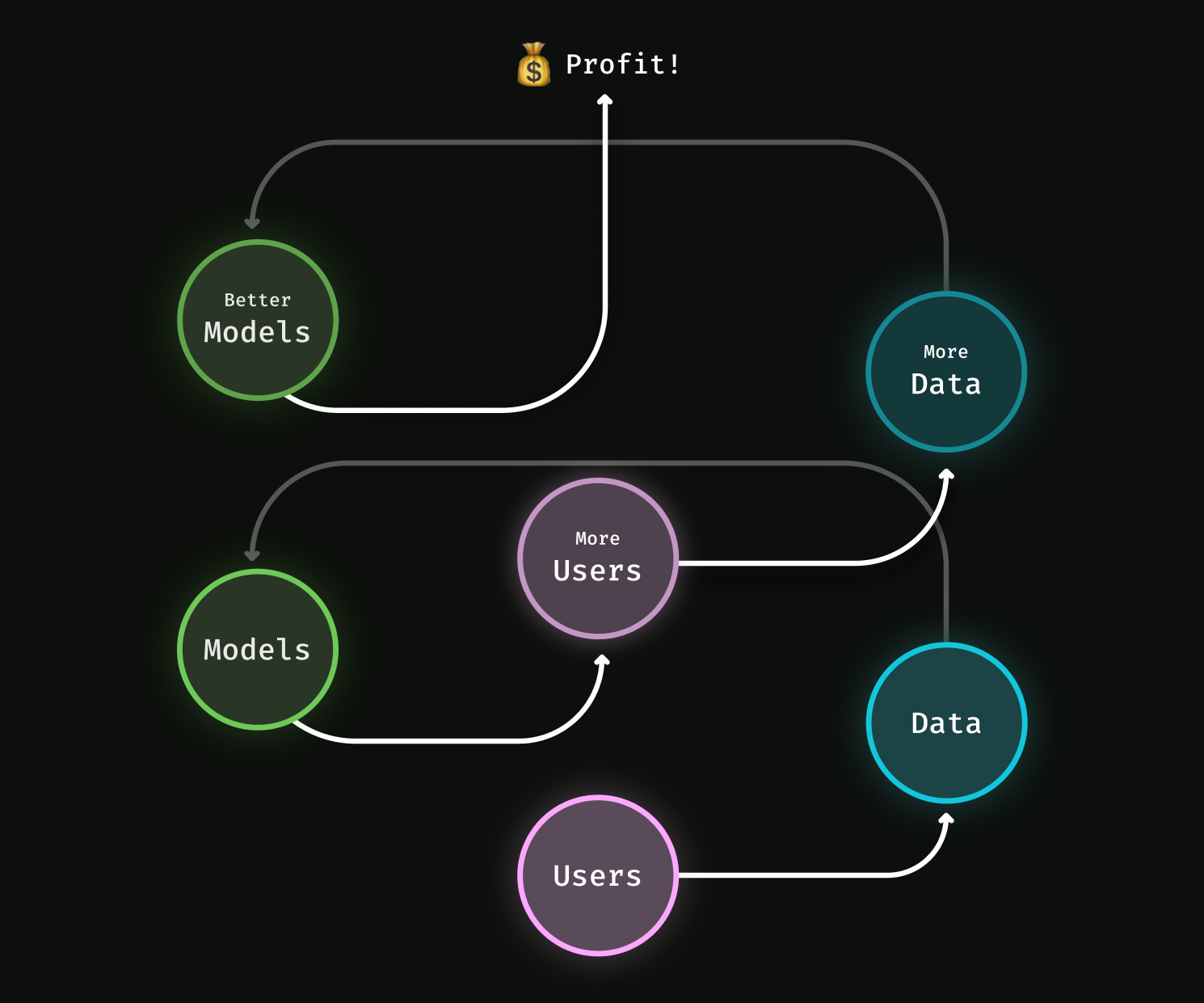
像 Netflix 和 Spotify 这样的顶尖机器学习公司利用数据飞轮从头创建了自己的模型,他们现在拥有大量数据。然而,当你刚开始一个新公司或项目时,你可能没有足够的数据。在 2010 年代,启动数据飞轮需要大量的创造力或资源投入。
但在 2020 年代,随着高性能通用预训练模型和宽松许可证的出现,启动数据飞轮变得大大简化。你可以从这些模型之一开始,这些模型经过大规模、多样化数据集训练,能够在你的任务中表现得相当不错。
在之前的博客文章中,我们展示了如何通过使用 Modal 的自动扩展基础设施在数百个 GPU 上部署现成模型,在不到 15 分钟内嵌入整个英文维基百科,证明了这一点。
微调启动数据飞轮
这些模型和运行它们的基础设施的可用性对于刚刚起步且还没有用户数据的组织来说是个好消息。但关键是要尽快转向一个定制模型,以提供比现成模型更好的性能。幸运的是,数据积累得很快:只需几十个用户每天与服务交互 3-4 次,几天内就能生成数百个数据点。
这些数据足以训练一个在样本数据集上击败 OpenAI 的text-embedding-3-small的模型。
我们用于创建嵌入的 Modal 上的同样可扩展、无服务器基础设施也可以用来定制模型,这个过程称为微调。最终结果是一个具有更高性能且显著降低运营成本的机器学习应用:启动你自己数据飞轮的第一步。
微调的操作:数据集、模型和基础设施
在微调模型时,有许多设计决策需要做出。我们在此回顾其中的一些。
找到或创建数据集
虽然机器学习的大部分讨论和研究都集中在模型上,但任何有经验的机器学习工程师都会告诉你,数据集才是最关键的部分。
嵌入模型通常在由成对项目组成的数据集上进行训练,其中一些对被标记为“相似”(如来自同一段落的句子),而一些对被标记为“不同”(如随机选择的两个句子)。同样的原理可以应用于比句子更长的文本——段落、页面、文档——或者应用于文本之外的事物——图像、歌曲、用户点击流——或者同时应用于多种模态——图像及其标题、歌曲及其歌词、用户点击流和购买的产品。
我们将使用Quora 数据集,其中包含 Quora 上帖子中的问题对,有些对被标记为重复。
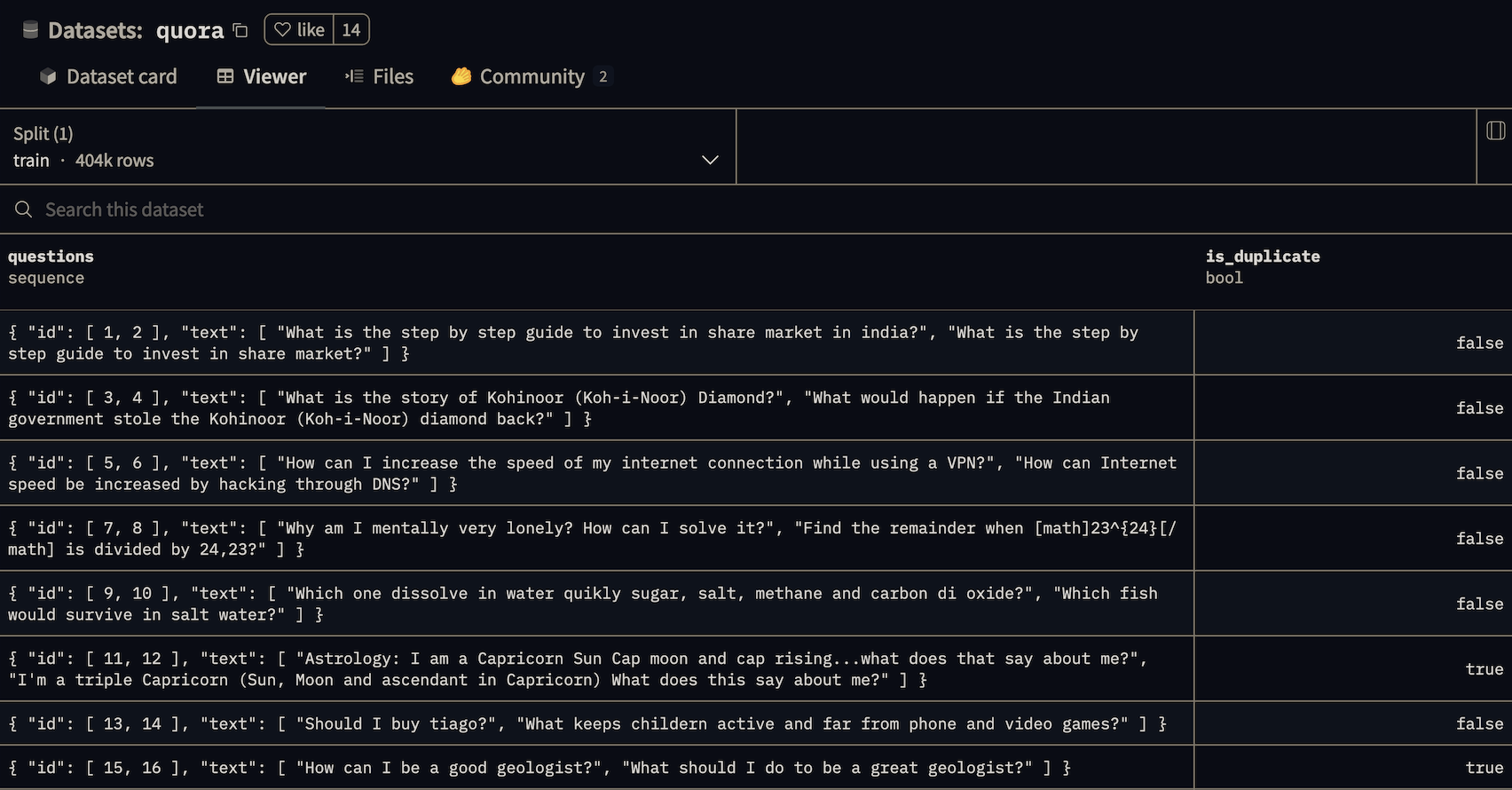
你可以在交互式查看器中查看数据集。其中一些问题对,如“Can I hack my Charter Motorolla DCX3400?”和“How do I hack Motorola DCX3400 for free internet?”,非常相似,但并不是重复的,这种情况被称为“困难负例”。
综合来看,我们在此训练的模型可能对基于检索增强生成 (RAG) 的聊天机器人有用。在基于嵌入的 RAG 中,必须在大量文本中搜索少量与用户查询“匹配”的段落,即可能包含答案的段落。这个数据集将训练模型对问题主题的细微差异非常敏感。在检索前或训练其他模型前,近重复项也可以被移除,这种技术称为“语义去重”。
选择基础模型
我们将在这里主要关注宽松许可证的、可获得权重的模型。这些模型具有可以下载和修改的权重,就像你下载和修改开源代码一样。因此,我们在此将它们称为“开源”模型,尽管没有开放源代码倡议认证的“开源”定义适用于模型。模型通常通过 Hugging Face 的基于 git LFS 的模型库中心发布,我们将从那里获取模型。
或者,我们可以使用 API 来微调专有模型,如某些嵌入 API 服务所提供的那样。除了成本方面的考虑,我们发现微调模型非常复杂且与用例密切相关,因此需要控制训练过程。
如何在可用模型之间进行选择?每个模型的训练方式和特定的用例是不同的。最重要的是,模型是在特定的模态或模态(文本、图像、音频、视频等)和特定的数据集上训练的。一旦你缩小到处理你的用例中的模态的模型范围,比较它们在公共基准上的性能,如MTEB。除了任务性能,还要查看模型在资源需求和吞吐量/延迟方面的表现,同样可以通过公共基准数据(硬件提供商如Lambda Labs是一个很好的资源)。
例如,嵌入维度,或模型输出嵌入中的条目数,是一个重要的考虑因素。较大的向量可以存储更多的信息,导致更好的任务性能,但随着我们随着时间的推移嵌入更多数据,成本也会显著增加(成本增长更像 RAM 而不是磁盘)。在微调时,我们可以调整这个维度。
获取训练基础设施
微调一个模型需要大量的计算资源。即使是后来可以在 CPU,甚至是客户端或边缘 CPU 上运行得令人满意的模型,也经常在 GPU 上进行训练,这样可以在容易并行化的工作负载(如训练)上实现高吞吐量。
对于一个典型的微调任务,我们需要 1 到 8 个服务器级别的 GPU。超过 8 个 GPU 通常需要将训练分布到多个节点上,由于连接限制,这大大增加了硬件成本和工程复杂性。
但现在服务器级别的 GPU 很稀缺,这意味着它们很昂贵,无论是购买还是租用,云提供商经常要求最低数量和时长的预订。但微调任务更像是开发工作流(间歇性、不可预测)而不是生产工作流(始终在线、流量可预测)。综合起来,这些现象导致了大规模的过度分配和过度支出,根据ClearML 和 AI 基础设施联盟的这项调查,组织报告的峰值利用率平均约为 60% ——非高峰时段甚至更低。
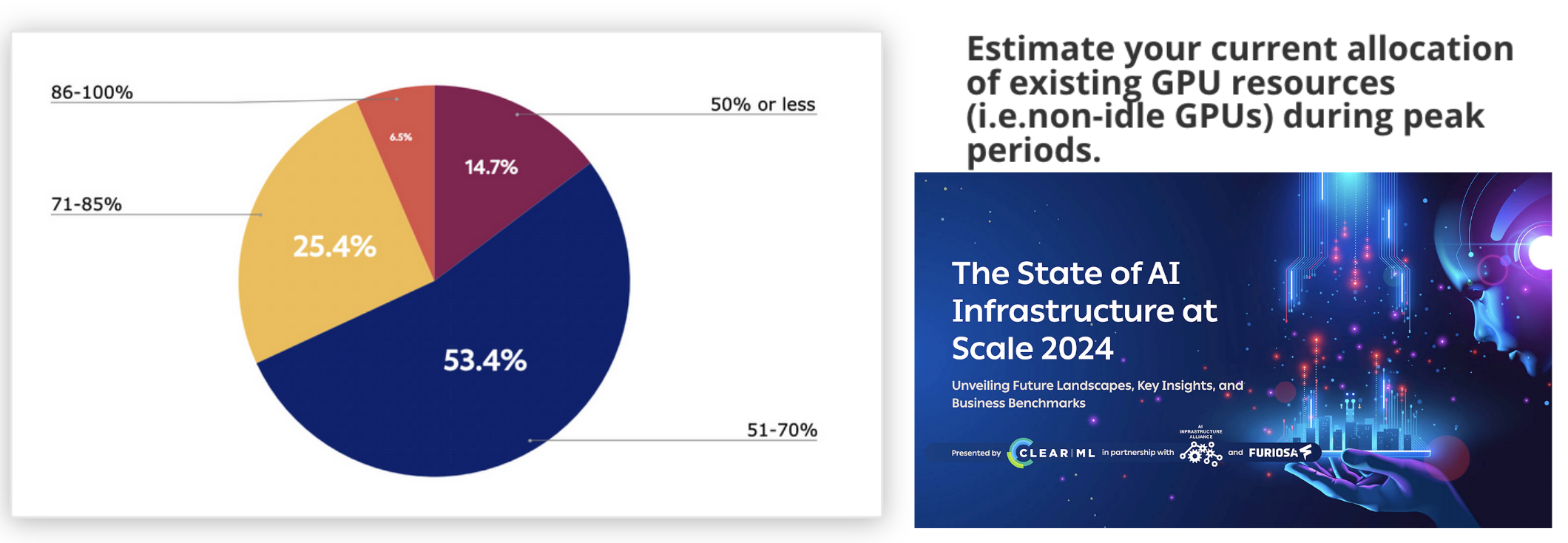
Modal 解决了这个问题:它提供自动扩展基础设施,包括 GPU,因此你只需为你使用的部分付费(也就是“无服务器”)。Modal 还提供了一种 Python 化的、基础设施即代码的接口,使数据科学家和机器学习研究人员能够拥有和控制他们的基础设施。
有了这些资源,我们需要确定如何范围化我们的模型训练过程。我们在训练上投入的时间和金钱越多,在超参数和数据调整上迭代越多,我们的任务性能就会越好,但收益递减。通常,我们建议要么在某些指标上训练到满意(例如,至少 90% 的准确率),要么选择几个满足的指标和一个最大化的指标(例如,召回率≥50%的情况下获得的最高准确率),然后设置资源和时间的硬限制。
对微调超参数进行网格搜索
确定如何训练一个全新的模型架构或一个全新的任务是一个研究项目,应相应地进行范围化。但微调更简单——我们可以使用预先存在的训练配方,如训练模型所用的配方(如果它是开源的)。但仍有实验的空间,包括在上面列出的一些考虑因素上。
我们选择了三个我们认为最重要的实验参数:我们应该训练哪个预训练模型,训练多少数据,以及输出维度是多少?因为这些实验参数决定了模型中的参数(权重和偏差)的值,所以它们被称为超参数。
探索超参数的最简单方法是定义每个超参数的一组可能值,然后检查所有组合——网格搜索。这是一种蛮力方法,但正如我们将在下文看到的,它是有效的且易于并行化的。
我们在 Wikipedia 嵌入示例中使用的原始bge-base-en-v1.5模型中添加了两个额外的模型,并尝试了两个不同的嵌入维度。对于每种配置,我们测试了不同的数据集大小,从一百个到超过十万个样本:
所有其他超参数都保持不变。
接下来,我们使用标准库模块itertools提供的product函数生成model、dataset_size和dense_out_features的所有可能组合,该函数创建一个迭代器,返回来自每个输入列表的所有元素组合(即笛卡尔product)。然后我们使用这些组合生成我们的模型微调过程的配置对象:
无论我们的微调过程是什么,它接受config并产生一些results字典。我们将其包装在一个用@app.function()装饰的函数中,使其可以在 Modal 的自动扩展基础设施上运行,如下面的伪代码。
从那里开始,扩展就像调用objective.map以并行运行实验一样简单。我们将其包装在一个用@app.local_entrypoint()装饰的函数中,这样我们就可以使用modal run从命令行启动实验。
我们的训练过程适合单个 GPU,每个实验并行运行,因此我们可以将其扩展到 Modal 允许的最大同时 GPU 工作者数量——截至撰写本文时为数千个。对于大型训练任务,这可能意味着在下周还是午餐后获得结果之间的区别。
用几百个示例打败专有模型
下图总结了我们的实验结果,显示了我们在 Quora 数据集上训练的模型的错误率(错误预测的比例)随微调期间使用的数据集示例数量的变化,每个模型都有一个图。为了进行比较,显示了 OpenAI 的text-embedding-3-small模型的性能。为了完整性,我们展示了我们测试的两个不同的嵌入维度,尽管我们没有观察到它们在其他超参数设置下的性能差异。
我们在这三种情况下看到了微调中常见的一些模式:
- 对于
jina-embeddings-v2-small-en模型,错误率高于基线,且从未下降。正如往常一样,不同的其他超参数设置可能会导致该模型的性能提高。这是你在超参数搜索中不想得到的结果,因为不清楚下一步该怎么做。 - 对于
all-mpnet-base-v2模型,错误率在只有 100 个示例后低于基线,但即使增加到三个数量级的示例,也没有观察到太大改进。 - 对于
bge-base-en-v1.5模型,错误率起初高于基线模型,但随着更多数据的加入迅速改善,在 200 个示例时显著超越基线,并且在 100,000 个示例时仍在改进。
回顾这些结果,我们会继续使用微调后的bge-base-en-v1.5模型,尤其是如果我们期望未来能够通过数据飞轮收集更多数据的话。我们很可能会选择 256 维嵌入,因为它们比 512 维嵌入便宜且存储更省,而我们没有观察到使用更大嵌入的准确性提升。
你可能会反对说,相对于基线的改进在绝对值上很小——17% 的错误率对比 13% 的错误率。但相对来说,这是一个很大的区别:基线模型四分之一的错误被微调模型避免了。这种现象在错误率下降时变得更强:一个具有 99% 可靠性的系统可以在一个具有 95% 可靠性的系统不可接受的情况下使用,尽管差异的绝对值看起来很小。
下一步
在本文中,我们展示了如何微调一个开源嵌入模型,以在一个简单的问答任务上击败一个专有模型。我们还讨论了微调模型时的考虑因素以及如何使用 Modal 对超参数进行网格搜索。我们展示了即使只有几百个示例,我们也能获得比专有模型更好的性能。
展望未来,微调的下一步将是将此过程运营化,以便我们可以收集更多数据并对模型进行迭代。通过全面自动化,我们甚至可以将模型变成一个不断改进的系统,由我们收集的额外数据驱动。
远远超过模型,这些将数据转换为用户有用特性的管道和过程是机器学习团队的输出。使用开源模型和无服务器基础设施,构建它们比以往任何时候都更容易。