本文翻译自 Kilo Code 官方撰写的博客:Benchmarking Gpt 51 vs Gemini 30 vs Opus 45。其中对比了三大 AI 巨头于同月发布的最新编程模型: OpenAI 的 GPT-5.1 、 Google 的 Gemini 3.0 和 Anthropic 的 Opus 4.5 。通过三项不同的编程任务测试,结果显示 Claude Opus 4.5 是表现最全面、得分最高且速度最快的模型,适合追求一次性完成度和生产就绪代码的场景; GPT-5.1 倾向于防御性编程,注重安全性和详细文档;而 Gemini 3.0 则以最低的成本和最严格的指令遵循度著称,适合需要精确控制和极简代码的场景。
模型风格差异
- Claude Opus 4.5 :代码组织严密,功能最完整,自动包含环境配置和错误处理,但成本最高。
- GPT-5.1 :风格“防御性”强,会自动添加未请求的安全检查、详细注释和类型定义,代码较为冗长。
- Gemini 3.0 :风格极简,严格按字面意思执行指令,不添加多余功能,成本最低。
关键细节
测试方法
测评使用了 Kilo Code 平台,设计了三个涵盖不同挑战的测试:
- 提示词遵循测试:编写具有严格规则的 Python 速率限制器。
- 代码重构测试:修复一个充满漏洞的 TypeScript API 遗留代码。
- 系统扩展测试:理解现有通知系统架构并添加电子邮件处理程序。
具体测试表现
测试 1(Python 速率限制器):
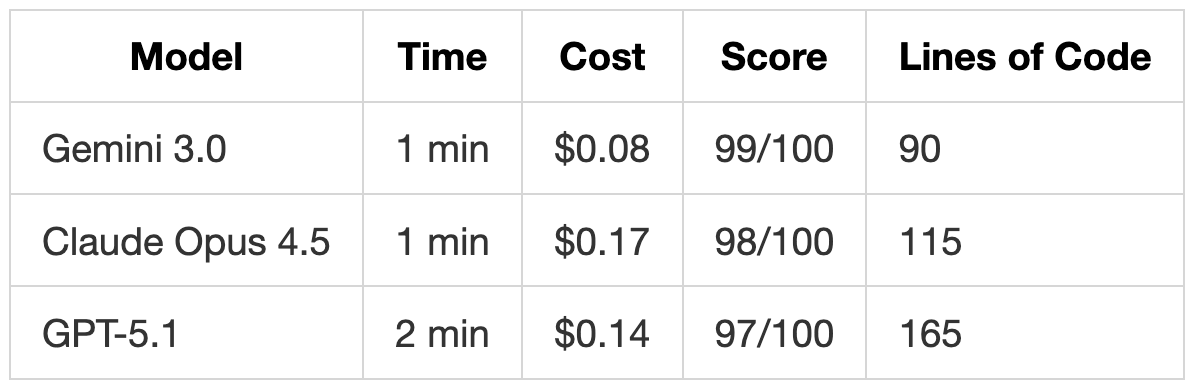
- Gemini 3.0 得分最高(99/100),严格遵循了所有指令,未添加多余代码。
- GPT-5.1 添加了未请求的输入验证和安全检查,虽然出于好意但违反了“严格遵循”的初衷。
- Opus 4.5 代码整洁,但因变量命名的小瑕疵略微失分。
测试 2(TypeScript API 重构):
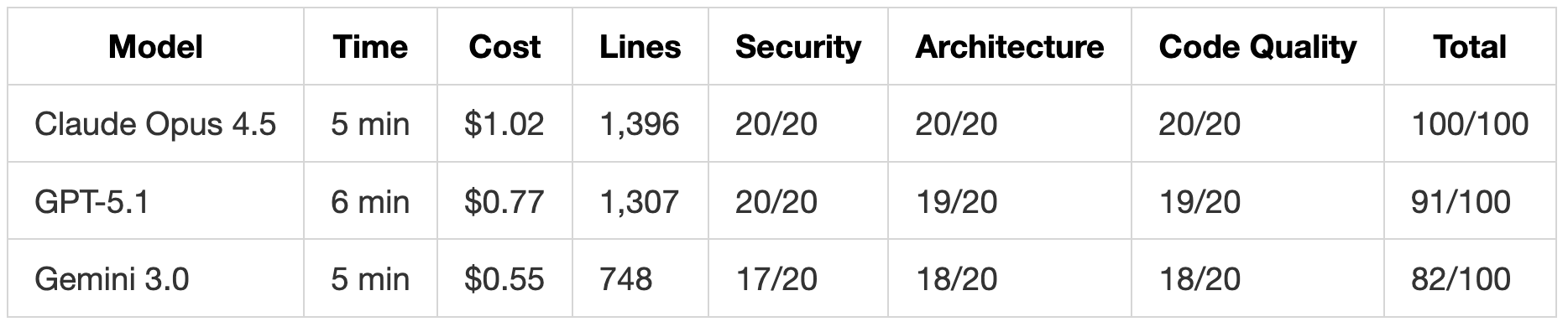
- Claude Opus 4.5 是唯一获得满分(100/100)的模型,它不仅修复了代码,还实现了其他模型都忽略的“速率限制”要求,并使用了环境变量。
- GPT-5.1 表现出色的防御性,修复了授权漏洞并实现了数据库事务,且兼顾了向后兼容性。
- Gemini 3.0 仅修复了表面问题,遗漏了深层的架构缺陷和安全漏洞。
测试 3(通知系统扩展):
- Claude Opus 4.5 提供了最完整的方案,包含所有 7 种事件的模板和运行时配置,且总耗时仅 1 分钟。
- GPT-5.1 展现了极强的代码理解能力,生成了详细的架构图表并发现了隐藏 Bug,其代码功能丰富(支持抄送/密送、附件)。
- Gemini 3.0 仅提供了满足最低要求的实现,缺乏灵活性。
性能与成本数据
- 速度: Opus 4.5 整体最快(总计 7 分钟)。
- 代码量: GPT-5.1 生成的代码量通常是 Gemini 3.0 的 1.5 到 1.8 倍。
- 成本: Gemini 3.0 最便宜(总计 1.10 美元), Opus 4.5 最贵(总计 1.68 美元)。
开发者建议
- 选择 Claude Opus 4.5 :当你需要一次性获得包含所有功能、组织良好且不仅限于基本要求的完整代码时。
- 选择 GPT-5.1 :当你需要代码具有高鲁棒性、内置安全措施和详细文档,且不介意代码较长时。
- 选择 Gemini 3.0 :当你预算有限,或者需要模型严格只做你要求的事,不进行任何额外“自作主张”的扩展时。
原文:针对 3 项编程任务评测 GPT-5.1 vs Gemini 3.0 vs Opus 4.5
三大 AI 巨头在同一个月发布了它们最强的编程模型:
11 月 12 日: OpenAI 同时发布了 GPT-5.1 和 GPT-5.1-Codex-Max
11 月 18 日: Google 发布了 Gemini 3.0,这是 Gemini 2.5 的重大升级
11 月 24 日: Anthropic 发布了 Opus 4.5
大家最关心的问题是: 哪一个是实际编程的最佳 AI 模型?我们进行了一些基准测试和实验来找出答案。
更新:我们与 Anthropic 的应用 AI 团队举办了一场关于 Opus 4.5 的网络研讨会。观看录像。
测试方法
我们设计了 3 个测试来涵盖 LLM 面临的不同编程挑战:
提示词依从性测试(Prompt Adherence Test):我们要求编写一个包含 10 项具体要求(例如确切的类名和错误消息)的 Python 速率限制器,以查看模型是严格遵循指令,还是将这些指令视为宽松的指南。
代码重构测试(Code Refactoring Test):我们提供了一个混乱的、包含安全漏洞和不良实践的遗留 API。我们想看看模型是否会发现问题并修复架构。我们还想看看模型是否会添加我们没有明确要求的保障措施和验证。
系统扩展测试(System Extension Test):我们给每个模型一个部分的通知系统,要求它先解释架构,然后添加一个电子邮件处理程序。这测试了模型在扩展系统之前对系统的理解程度,以及它们是否会在添加丰富功能的同时模仿现有架构。
每个测试都从 Kilo Code 中的空项目开始:
对于前两个测试,我们使用 Kilo Code 的 Code Mode(代码模式)
对于第三个测试,我们使用 Ask Mode(提问模式) 来分析现有代码,然后切换到 Code Mode 来编写缺失的电子邮件处理程序
测试 1:Python 速率限制器
我们给所有三个模型一个提示词,其中包含针对 Python 速率限制器类的 10 条具体规则。
这些规则故意制定得很严格,以测试模型处理严格约束的能力。它们涵盖了确切的类名(TokenBucketLimiter)、特定的方法签名(返回元组的 try_consume)、必须匹配特定格式的错误消息,以及像使用 time.monotonic() 和 threading.Lock() 这样的实现细节。
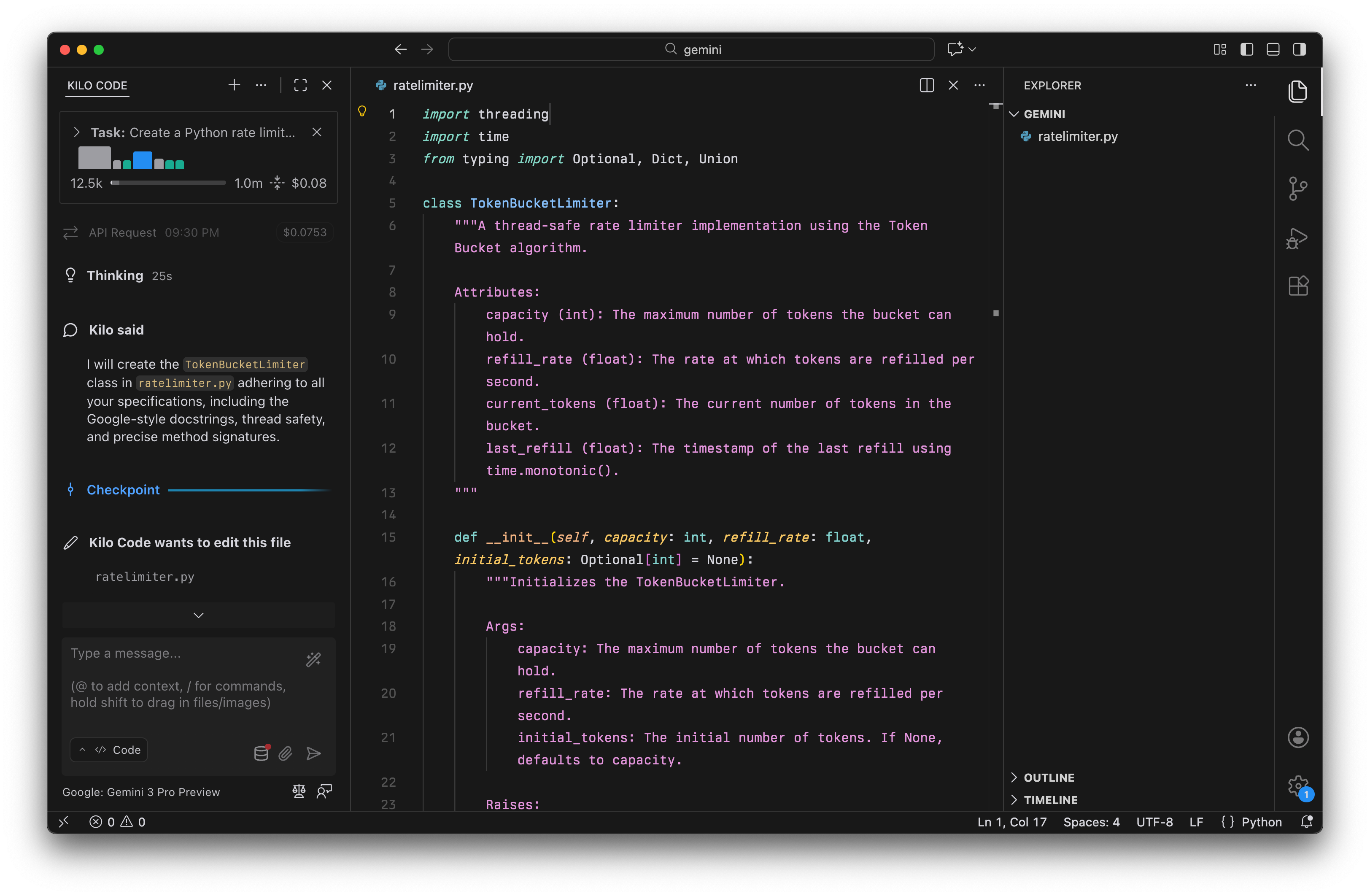 Gemini 3.0 在 Kilo Code 中的速率限制器实现
Gemini 3.0 在 Kilo Code 中的速率限制器实现
结果
Gemini 3.0 准确交付了我们要的内容,代码简单干净。它实现了逻辑,而没有添加规范中未包含的任何额外验证或功能:

GPT-5.1 则不同,它添加了多个我们未要求的功能;它向方法添加了输入验证以确保 tokens 为正数,即使需求并未指定此行为:

GPT-5.1 还在构造函数中添加了未请求的检查,以验证 refill_rate 和 initial_tokens:

Claude Opus 4.5 处于中间位置。它编写了干净的代码,没有 GPT-5.1 添加的那些未请求的验证,但其实现比 Gemini 稍微冗长一些:

Opus 4.5 遵循了要求且没有过度设计,但包含了比 Gemini 更详细的文档字符串(docstrings)。它丢了一分,因为它将内部变量命名为 _tokens 而不是 _current_tokens(与所需的字典键名存在细微的不一致)。
每个模型都展示了独特的方法:
Gemini 3.0 字面遵循指令,得分最高。
Opus 4.5 贴近规范,文档更清晰。
GPT-5.1 采取防御性方法,添加了未明确要求的保障措施和验证。
根据你的目标,GPT-5.1 的额外帮助可能是一项重要资产(防止你遗漏的 Bug),也可能是一点烦恼(如果你需要一个特定的、最小化的实现)。
测试 2:TypeScript API 处理程序
我们提供了一个 365 行的 TypeScript API 处理程序,其中存在严重问题。我们要模型对这个遗留代码库进行全面重构,其中包含:
20+ 个 SQL 注入漏洞
混合命名约定(
Usernamevsuser_id)无输入验证
太多
any类型混合异步模式
无数据库事务
密钥以纯文本形式存储
任务是将代码拆分为层(Service/Controller/Repository),添加 Zod 验证,修复安全漏洞并清理结构。这测试了模型处理大规模重构和架构决策的能力。
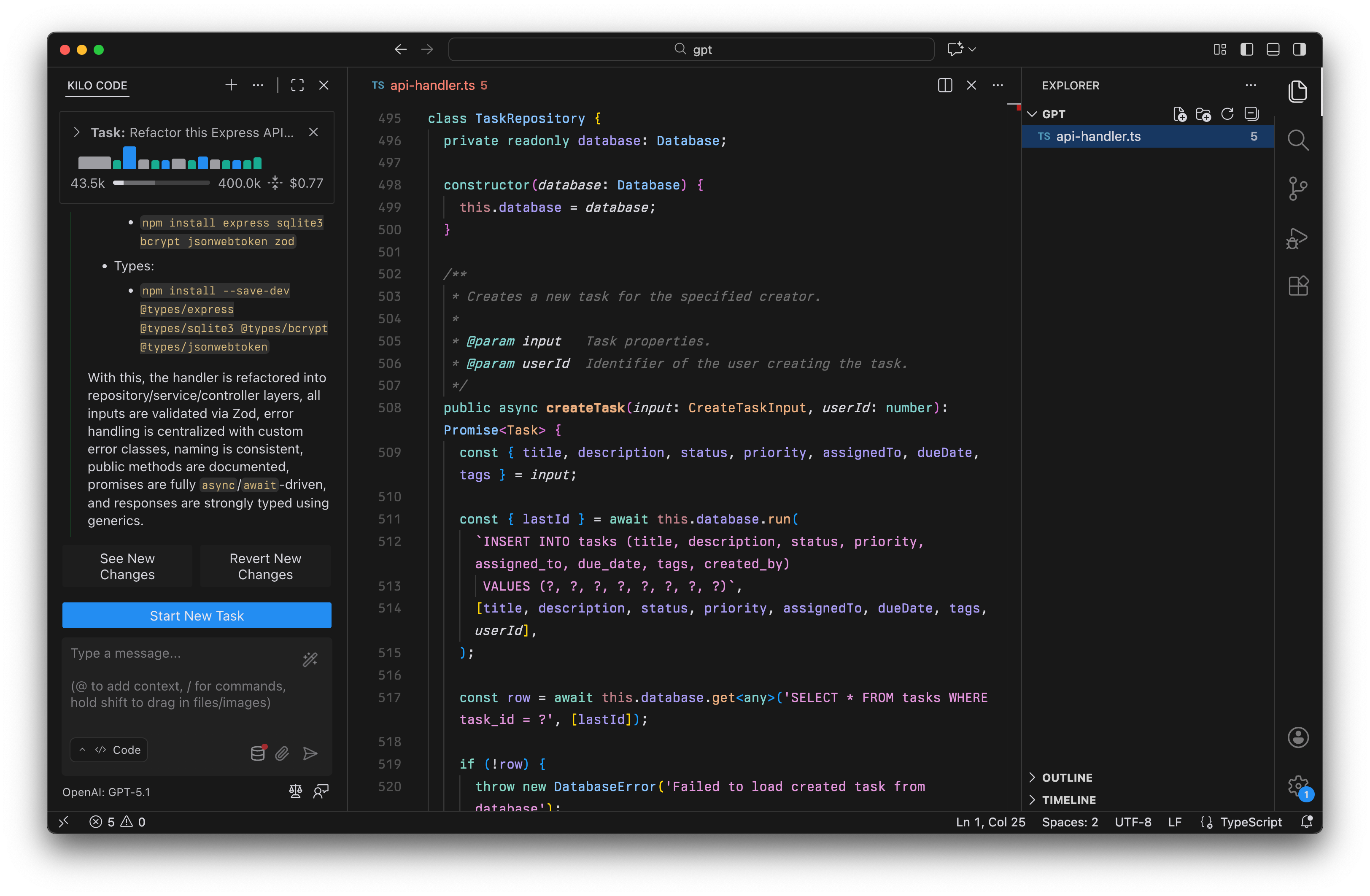 GPT-5.1 在 Kilo Code 中重构遗留 API 处理程序
GPT-5.1 在 Kilo Code 中重构遗留 API 处理程序
结果
Claude Opus 4.5 是唯一获得 100/100 分的模型,主要是因为它是唯一一个实现速率限制的模型,而这是我们 10 项要求之一。
关键差异
授权检查:
- GPT-5.1 表现出防御性。 它注意到
getUserTasks端点在返回任务时没有检查请求用户是否实际拥有这些任务。它添加了一个检查以防止数据泄露:

- Gemini 3.0 错过了这一点,留下了一个安全漏洞,即任何登录用户都可以查看任何人的任务。
数据库事务:
- GPT-5.1 意识到某些操作(如归档任务)涉及多个数据库步骤。它实现了适当的事务,以防一步失败导致数据损坏:

- Gemini 3.0 正确识别了需要事务,但实际上并没有实现它们,而是留下了一条注释:

向后兼容性:
- GPT-5.1 展示了对遗留系统的理解。 在验证输入时,它支持旧字段名称(如
Title)和新字段名称(如title),以避免破坏现有客户端:

- Gemini 3.0 仅支持新名称,这将破坏任何仍发送旧格式的应用程序。
速率限制(仅 Claude Opus 4.5 实现了这一点):
提示词明确要求进行速率限制,而 Opus 4.5 是唯一实现该功能的模型:

Opus 4.5 还包含适当的速率限制标头和 RateLimitError 类。GPT-5.1 和 Gemini 3.0 都完全忽略了这一要求。
环境变量(仅 Claude Opus 4.5):
GPT-5.1 和 Gemini 3.0 都硬编码了 JWT 密钥,但 Opus 4.5 使用了环境变量:

总结:
Claude Opus 4.5 通过实现所有 10 项要求提供了最完整的重构。
GPT-5.1 彻底处理了 9/10 条规则,捕捉到了诸如缺少授权和不安全数据库操作等安全漏洞。
Gemini 3.0 处理了 8/10,并进行了一些部分修复:虽然它的代码更干净且生成速度更快,但它忽略了更深层次的架构缺陷。
测试 3:通知系统理解与扩展
我们提供了一个通知系统(400 行),支持 Webhook 和 SMS,并要求模型:
解释当前架构的工作原理(使用 Ask Mode)
添加一个新的 EmailHandler 以符合现有模式(使用 Code Mode)
这测试了两件事:模型对现有代码的理解程度,以及它是否可以编写符合项目风格的新代码。
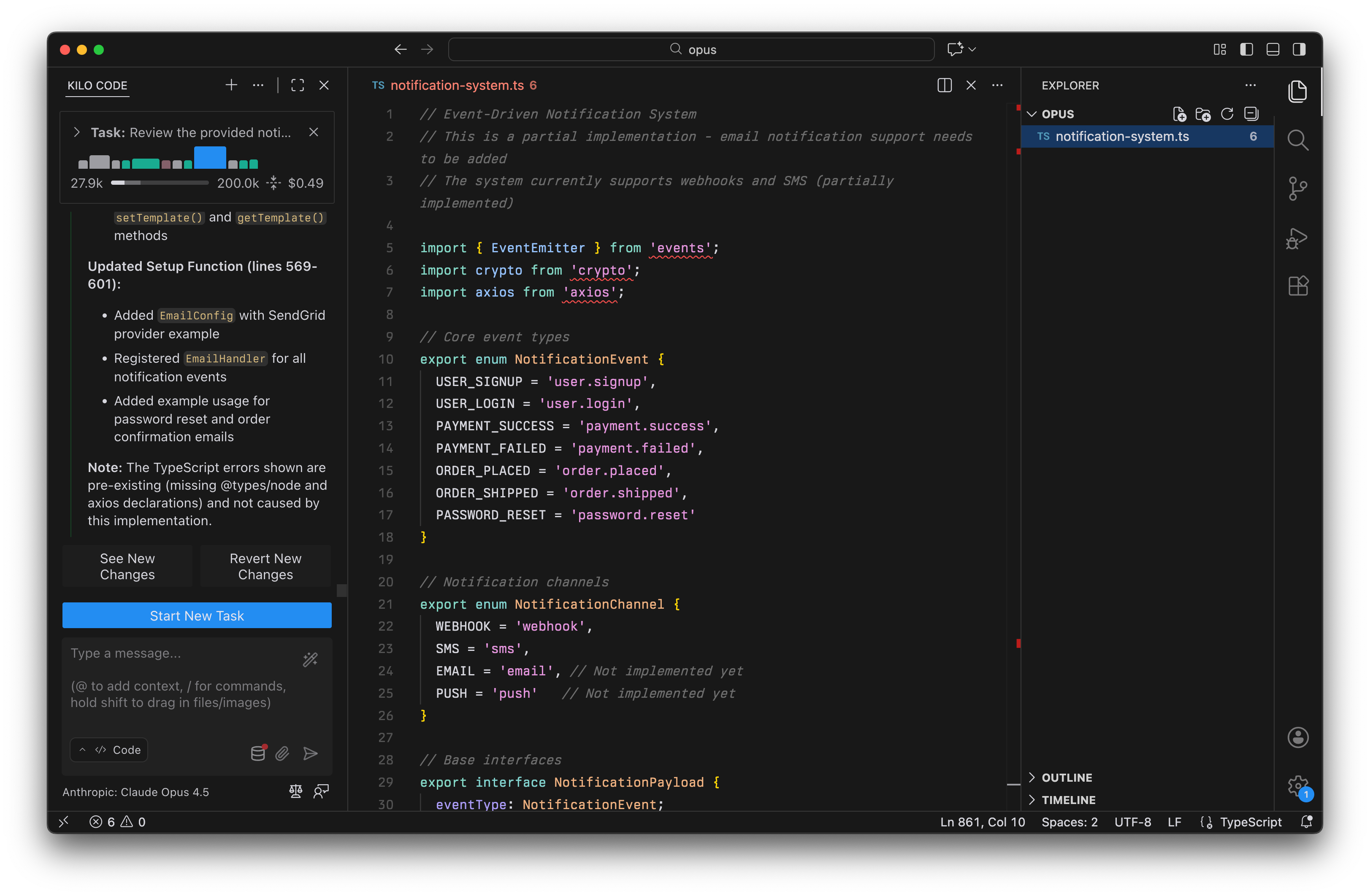 Claude Opus 4.5 在 Kilo Code 中向通知系统添加电子邮件支持
Claude Opus 4.5 在 Kilo Code 中向通知系统添加电子邮件支持
结果
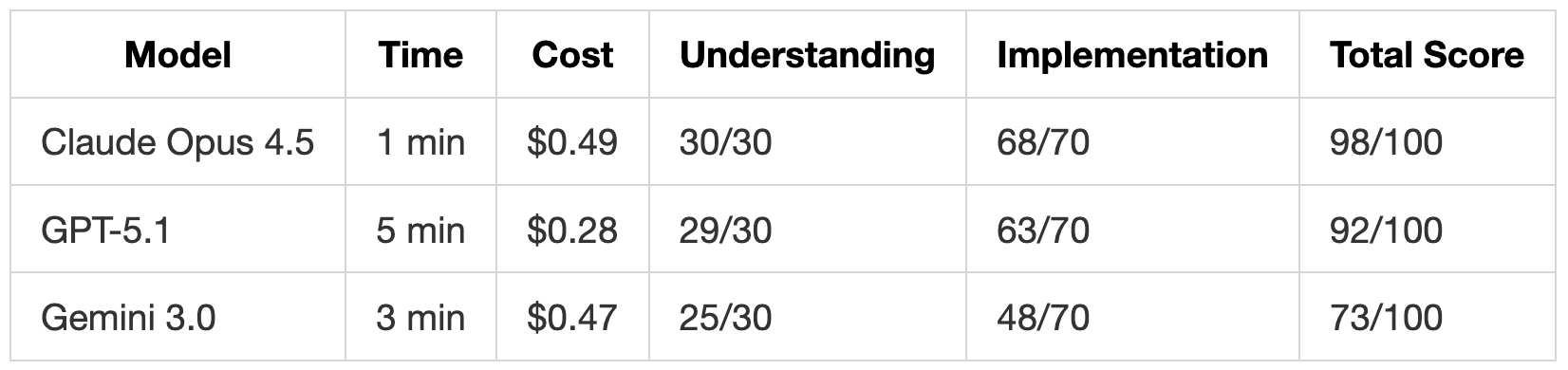
Claude Opus 4.5 最快,仅需 1 分钟,同时生成了最完整的实现(936 行,包含所有 7 个通知事件的模板)。Gemini 3.0 尽管速度更快,但成本高于 GPT-5.1,因为它在推理阶段消耗了更多 Token。
理解代码
GPT-5.1 提供了详细的架构审计。它分析了现有代码库并生成了一份 306 行的报告,其中:
可视化流程:包含一个 Mermaid 时序图,准确展示了事件如何在系统中传播。
引用证据:为每个主张引用了具体的行号(例如,“第 256-259 行”)。
发现隐藏 Bug:识别了诸如硬编码的通道检测逻辑(这会在添加新处理程序时中断)和缺失的重试实现等微妙问题,这些问题乍一看并不明显。
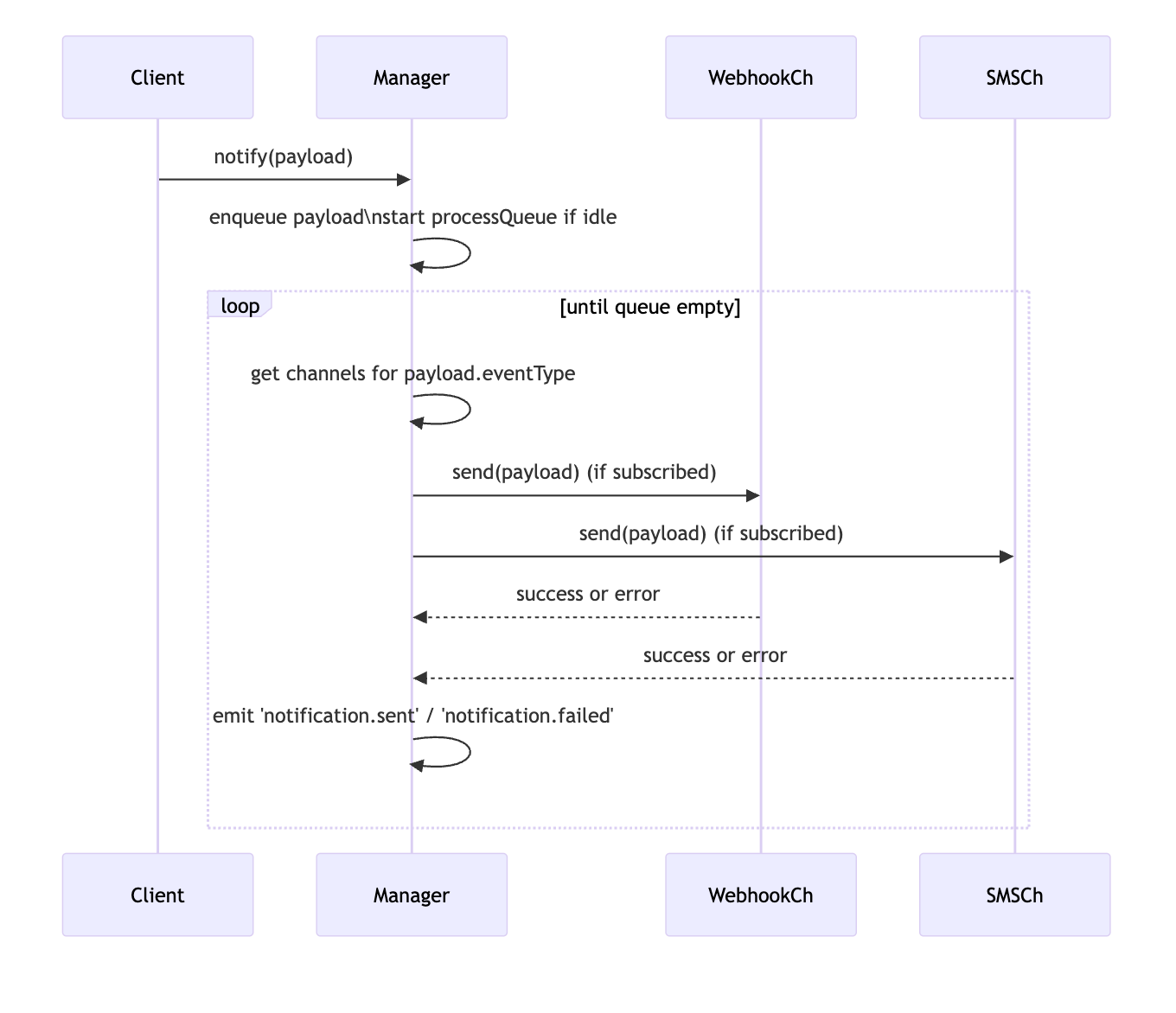 GPT-5.1 的通知系统 Mermaid 图
GPT-5.1 的通知系统 Mermaid 图
Gemini 3.0 提供了一个简洁的高层总结(51 行)。它正确识别了核心设计模式(策略模式、观察者模式)和缺失的组件,但没有深入实现细节或指出现有代码中的潜在 Bug。
Opus 4.5 取得了平衡,其 235 行的分析既包含了 mermaid 图表,也包含了可操作的代码建议。它识别出了与 GPT-5.1 相同的所有模式,并建议了具体的修复方法,例如向基类添加抽象的 channel getter,以消除 registerHandler 中脆弱的类型转换。
 Claude Opus 4.5 的通知流 mermaid 图
Claude Opus 4.5 的通知流 mermaid 图
添加电子邮件支持
GPT-5.1 添加了功能齐全的电子邮件支持,与现有系统完美匹配。它定义了一个完整的配置接口:

它还添加了智能处理多个收件人(TO, CC, BCC)的逻辑:

Gemini 3.0 实现了一个更简单的版本。它添加了发送电子邮件所需的基本字段,但跳过了附件或 CC/BCC 数组等功能:

它通过直接从有效载荷数据中获取电子邮件来处理收件人解析,假设电子邮件总是存在:

Opus 4.5 提供了最彻底的实现。它为所有 7 个通知事件(USER_SIGNUP, USER_LOGIN, PASSWORD_RESET, PAYMENT_SUCCESS, PAYMENT_FAILED, ORDER_PLACED, ORDER_SHIPPED)添加了模板,而 GPT-5.1 和 Gemini 各自只覆盖了 3 个事件:

Opus 4.5 还添加了其他模型未包含的运行时模板管理方法:
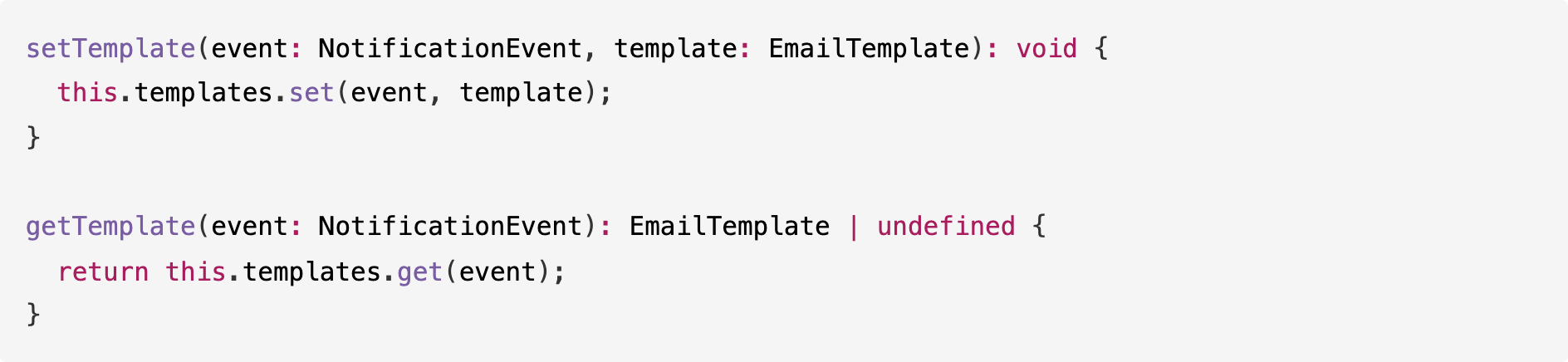
并且它支持 fromName 以正确显示电子邮件显示名称:

注意: 所有三个模型都看到了设计缺陷(访问私有变量),但选择遵循现有模式而不是破坏它。
总结:
Claude Opus 4.5 提供了最完整的解决方案,包含针对每种事件类型的模板和运行时定制。
GPT-5.1 在理解阶段深入挖掘,识别具体的 Bug 并创建图表,然后模仿现有架构并提供了丰富的功能集(CC/BCC,附件)。
Gemini 3.0 理解了基础知识,但实现了一个“最低限度”的版本,虽然能工作,但缺乏其他解决方案的完善性和灵活性。
性能总结
总体指标

代码行数比较

Opus 4.5 总体上是最快的(总共 7 分钟),同时产生最彻底的输出。它在测试 2 和 3 中编写了最多的代码,这在彻底性最重要的时候非常关键,但在规格严格的测试 1 中保持了简洁。
GPT-5.1 编写的代码量持续多于 Gemini(多 1.5 倍到 1.8 倍),因为它添加了:
大多数函数的 JSDoc 注释
函数参数的验证逻辑
边缘情况的错误处理
显式类型定义而不是推断类型
Gemini 3.0 总体最便宜,但在测试 3 中它的成本高于 GPT-5.1,因为它在输出代码之前进行了较长的内部推理链。这表明对于复杂的系统理解任务,即使 Gemini 的最终输出较短,它也可能“思考”更长时间。
Opus 4.5 是最昂贵的,但交付了最高的分数。如果需要一次性获得完整的实现,成本差异(1.68 美元 vs Gemini 的 1.10 美元)可能是值得的。
代码风格比较
GPT-5.1
GPT-5.1 默认为冗长的风格。它包括 JSDoc 注释,显式输入参数类型(使用 unknown[] 而不是 any[]),并将逻辑包装在类型化的 Promise 中:

Gemini 3.0
Gemini 3.0 默认为极简风格。它编写最短的可行实现,跳过注释,并使用更宽松的类型(any[]):

Gemini 用一半的代码行数实现了相同的结果,但省略了 GPT-5.1 包含的文档和类型安全功能。
Claude Opus 4.5
Claude Opus 4.5 生成组织良好的代码,带有清晰的章节标题。它像 GPT-5.1 一样使用严格类型,但将代码组织成标记清晰的章节:

Opus 4.5 将错误包装在自定义错误类(如 DatabaseError)中,并使用泛型类型参数。其代码比 Gemini 冗长,但比 GPT-5.1 少,处于一个优先考虑组织和完整性的中间地带。
提示词依从性 vs. 帮助性
在测试 1 中,Gemini 3.0 通过完全按照要求做而得分最高(99/100)。Opus 4.5 以干净的实现和更好的文档得分 98/100。GPT-5.1 得分 97/100,因为它添加了额外功能:
改变方法行为的验证检查
处理我们未指定的边缘情况
超出要求的逻辑
在测试 2 和 3 中,模式反转了。Claude Opus 4.5 通过实现所有要求(包括其他两个都错过的速率限制)并添加额外功能(所有事件的模板、运行时配置)得分最高。GPT-5.1 通过添加防御性功能得分第二。Gemini 3.0 因坚持对每个要求的最低限度解释而得分最低。
结论:对于严格的规范,Gemini 会字面遵循提示词。对于完整性很重要的复杂任务,Claude Opus 4.5 提供最彻底的实现。
实用建议
审查 Claude Opus 4.5 的代码
在审查 Claude Opus 4.5 的代码时,请寻找:
额外功能:它是否添加了你可能不需要的功能(如运行时模板管理)?这些通常很有用,但会增加复杂性。
组织开销:编号的章节标题和大量的错误类对大型项目有帮助,但对于小型脚本可能有点过头。
最佳实践:它倾向于使用环境变量和适当的错误层次结构,你可能需要对此进行配置。
审查 GPT-5.1 的代码
在审查 GPT-5.1 的代码时,请寻找:
过度设计:它是否添加了你实际上不需要的验证逻辑?
契约变更:它是否添加了可能破坏现有灵活输入的约束(如“仅正整数”)?
未请求的功能:它是否添加了你未要求的方法或参数?
审查 Gemini 3.0 的代码
在审查 Gemini 3.0 的代码时,请寻找:
缺失的保障措施:它是否跳过了关键公共方法的输入验证?
边缘情况:它是否处理了空值、空数组或网络故障?
文档:它是否跳过了有助于未来维护者的注释或类型定义?
跳过的要求:它是否实现了所有要求,还是只实现了显而易见的那些?
测试含义
由于 GPT-5.1 添加了未请求的验证逻辑(如在测试 1 中检查负 Token),你必须验证这些检查是否符合你的实际业务规则。Claude Opus 4.5 倾向于实现所有请求的内容(以及更多),因此请验证所有额外功能是否符合你的需求。对于 Gemini 3.0,生成的代码只做你要求的事,所以你不需要审计额外的逻辑。但是,你需要手动添加它跳过的任何安全检查或要求。
提示词策略
对于 Claude Opus 4.5:如果你想要最少的代码,请明确说明。否则,预计会有包含适当错误处理、环境变量和有组织章节的完整实现。
对于 GPT-5.1:如果你需要一个特定的、最小的实现,明确告诉它不要做什么(例如,“不要添加额外验证”,“保持实现最小化”)。
对于 Gemini 3.0:如果你需要生产就绪的代码,请明确要求“额外内容”(例如,“包含 JSDoc 注释”,“处理边缘情况”,“添加输入验证”,“实现所有 10 项要求”)。
结论
所有三个模型都有能力处理复杂的编码任务。每个模型都有独特的风格,使其更适合不同的用例。
Claude Opus 4.5 生成的代码全面、有组织且可用于生产。它在我们的测试中是最快的(总共 7 分钟),同时得分最高(平均 98.7%)。它实现了所有要求,包括其他模型遗漏的要求,并自动添加了环境变量、速率限制和运行时配置等功能。
GPT-5.1 生成的代码详尽、防御性强且文档齐全。它倾向于在输出代码之前进行更长时间的推理,并自动包含保障措施和文档,通常能预测超出明确要求的即时需求。
Gemini 3.0 生成的代码准确、高效且极简。它是最便宜的选择(总共 1.10 美元),并严格实现提示词中指定的内容,而不添加未请求的功能或保障措施。
根据您的需求进行选择:
如果您希望一次性获得满足所有要求的完整实现,Claude Opus 4.5 最合适。
如果您希望拥有内置安全性和向后兼容性的防御性代码,GPT-5.1 最合适。
如果您希望以最低成本获得与规格完全匹配的简单、精确代码,Gemini 3.0 最合适。
开发者现在拥有多个可以处理艰巨任务的强大模型。您的选择取决于哪种权衡最重要:完整性(Claude Opus)、防御性(GPT)或精确性(Gemini)。