本文探讨了在 AI 时代重新定义聊天机器人设计的必要性。随着 GPT 和 Gemini 等生成式 AI 平台的兴起,聊天机器人变得更加智能和人性化,但其设计不仅仅关乎技术能力,而是需要从用户体验出发,创造更自然、个性化和易于访问的互动体验。作者分享了自己在设计 AI 驱动聊天机器人过程中的经验,强调了视觉设计、语音定制、文本呈现、交互模式等方面的重要性,并提出了如何通过迭代设计来满足用户不断变化的需求。
- 视觉设计:从抽象到个性化
- 抽象与具体的设计选择:GPT、Gemini 等聊天机器人通常采用抽象图标,而更专用的产品可能会使用更具体的角色头像。但过于人性化的设计可能引发“恐怖谷”效应。
- 用户自定义选项:允许用户在抽象和具体设计之间选择,可以提升个性化体验,同时为设计决策提供数据支持。
- 语音定制:语调、风格与口音
- 语调与上下文匹配:利用 ElevenLabs 等工具,聊天机器人可以根据上下文动态调整语调,如道歉时柔和,庆祝时热情。
- 非语言沟通的重要性:根据 55/38/7 法则,38% 的沟通来自语音语调,55% 来自非语言线索,因此语音风格需与情感和语境匹配。
- 口音的多样性:通过模拟区域性口音(如英国的 Geordie 或 Brummie),可以增强文化亲近感和用户参与度。
- 文本呈现:信息长度与用户体验
- 信息长度的平衡:根据不同的产品目标(如简洁回答或叙事型互动),调整文本长度和风格。
- 文本显示方式:GPT 的打字机式呈现增加动态感,但可能让用户感到紧张;Gemini 的预加载动画则更平滑。
- 认知负荷管理与 UI 简化
- 界面清晰度:通过隐藏旧消息(如 Pi.ai 的做法),减少视觉干扰,帮助用户专注于当前对话。
- 调整响应节奏:通过滑块控制语速和停顿时间,满足听力障碍者、非母语用户及高压场景中的需求。
- 交互模式与语音输入
- 三种交互模式:包括语音对语音、按住说话和录音模式。其中,按住说话和录音模式在当前技术条件下更可靠。
- 语音交互改进:最新的 GPT 语音助手支持中断和调整聆听时间,显著提升语音对话的流畅性。
- 设计过程的迭代性
- 无一刀切方案:不同场景下,聊天机器人可能需要人性化或机械化的风格。
- 迭代设计:通过设计、测试和学习的循环,不断优化产品以适应用户需求。
- 未来方向与技术潜力
- 区域口音定制:目前尚未广泛实现,但未来可能会成为聊天机器人设计的趋势。
- 无缝语音对话:尽管技术尚未成熟,但完全自然的语音交互是未来的目标。
原文
从类人交互到语音定制和可访问性,学习如何创建更智能、更以用户为中心的聊天机器人。
人工智能 (AI) 的兴起已经改变了我们对产品设计和开发的看法。像GPT和Gemini这样的平台使得创建具有前所未有的复杂性的聊天机器人成为可能,从而使尖端技术更接近日常应用。但这不仅仅是关于工具或功能——而是关于我们如何对待设计本身的转变。
对于设计师来说,人工智能的引入标志着 新篇章的开始,这要求我们重新思考传统流程并采用全新的方法。构建人工智能驱动的产品远非即插即用的过程;它需要仔细关注用户体验,更深入地了解用户行为,并致力于打造超越功能的解决方案。借助人工智能,我们有绝佳的机会与用户进行更个性化的联系,创建量身定制的体验,以满足他们独特的需求、偏好和限制。
在过去的一年中,我一直沉浸在设计一个人工智能驱动的聊天机器人中,在此过程中收集了宝贵的见解和经验。在本文中,我将分享一些关于如何使聊天机器人体验感觉更真实、自然和用户友好的想法——这些是人们在对话式人工智能中真正寻求的品质。
设计你的聊天机器人的外观
在可视化聊天机器人时,有几种思路。像GPT、Gemini或Google Assistant这样的无面孔聊天机器人通常用简单的插图或图标来表示——尤其是在文本模式下,它们的小头像尺寸需要清晰、可识别的图标。在语音模式下,这些聊天机器人有时会采用抽象的构成,例如GPT、Gemini或最近更新的Siri所看到的视觉风格。这种方法对于旨在集成到各种特定产品中的人工智能模型很常见。(顺便说一句,我是Siri新外观的粉丝!)
随着我们深入构建更专业化的产品,头像策略往往会发生转变。在这些情况下,看到聊天机器人由角色头像表示并不少见。虽然有些人可能觉得这种方法太字面化,但它可能非常有效,尤其是在客户服务等情况下。然而,这种策略存在一个潜在的陷阱:如果头像看起来非常像人类,但没有完全达到感觉真正像人类所需的逼真程度,它就有可能跨入“恐怖谷”。这正是头像感觉几乎像人类但又不够像人类的奇怪时刻,这会给用户带来尴尬或不适的体验。我将在以后的文章中进一步探讨这个问题。
选择正确的设计
如果您不确定应该采用哪种方法,请考虑允许用户在设置中自定义聊天机器人的外观。提供一些不同的选项,包括抽象和字面的表示,并让用户选择他们的偏好。这种方法不仅可以个性化体验,还可以提供有价值的见解——通过分析结果数据,您可以识别趋势并做出更明智的设计决策。
定制语音:音调和风格
随着像 ElevenLabs 这样的产品的进步,我们现在拥有强大的工具来微调聊天机器人语音响应的音调和风格。设计师可以决定是否希望聊天机器人以中性、通用的音调响应,采用更柔和、耳语的风格,甚至根据特定上下文动态调整其音调和语调。
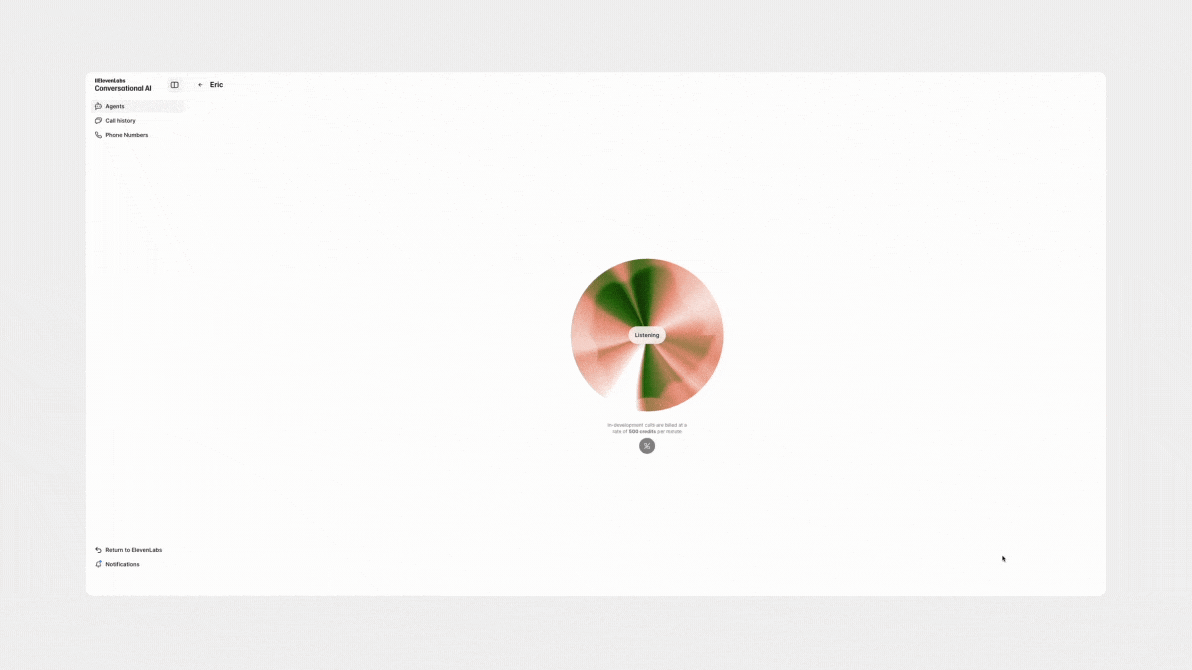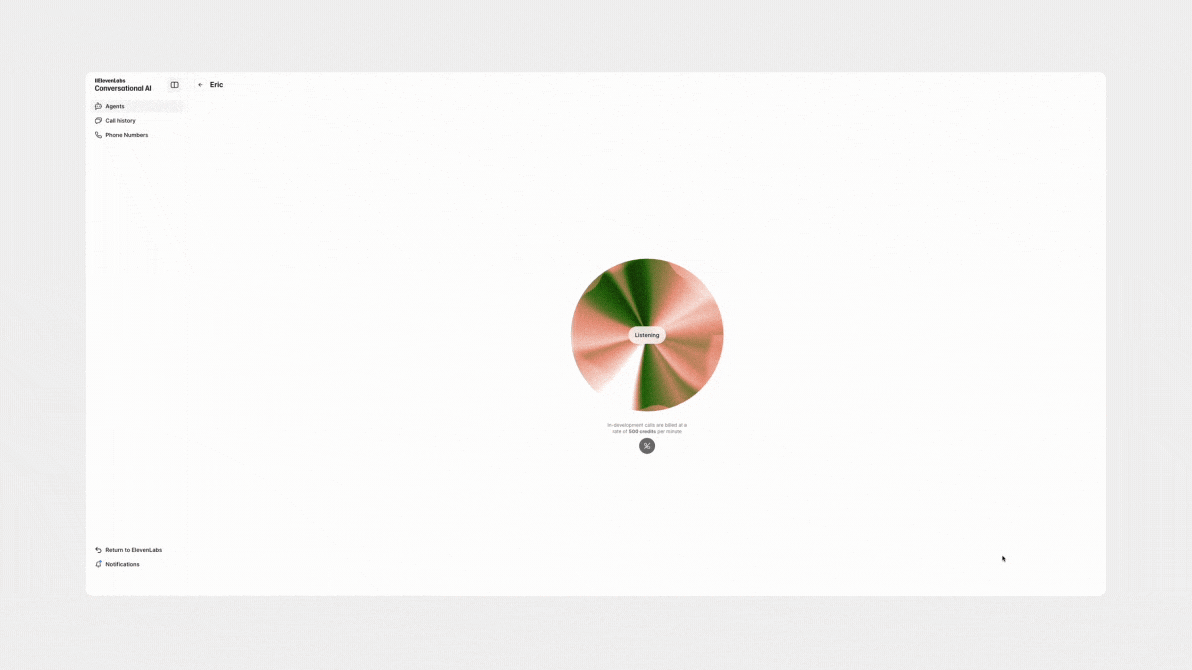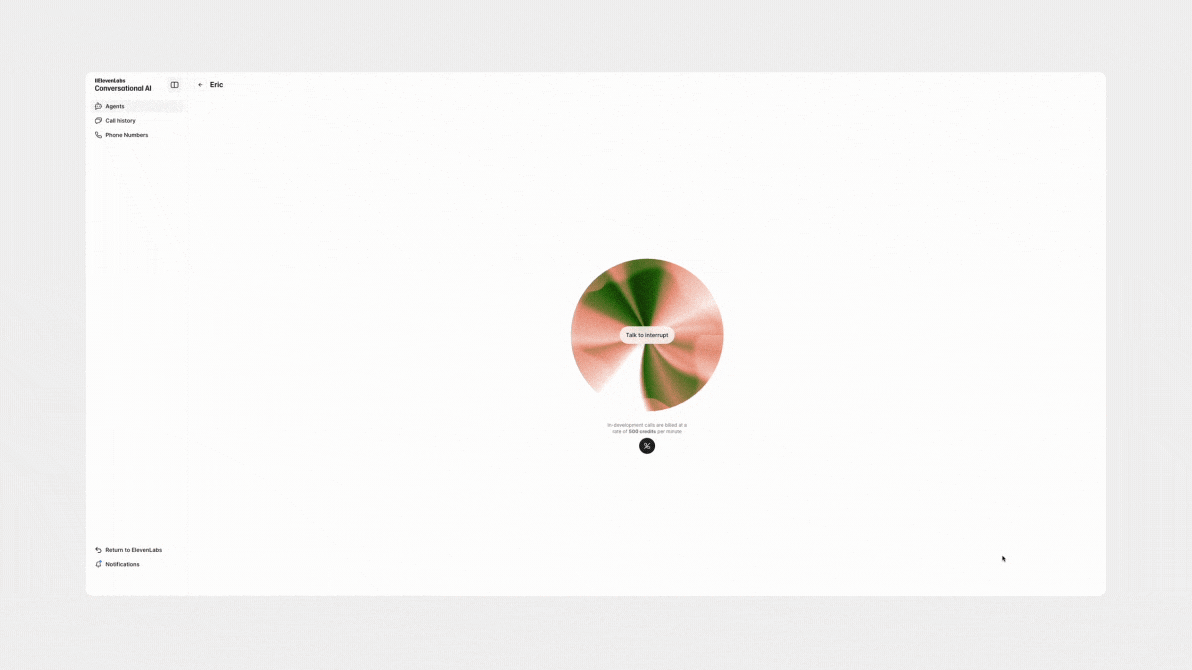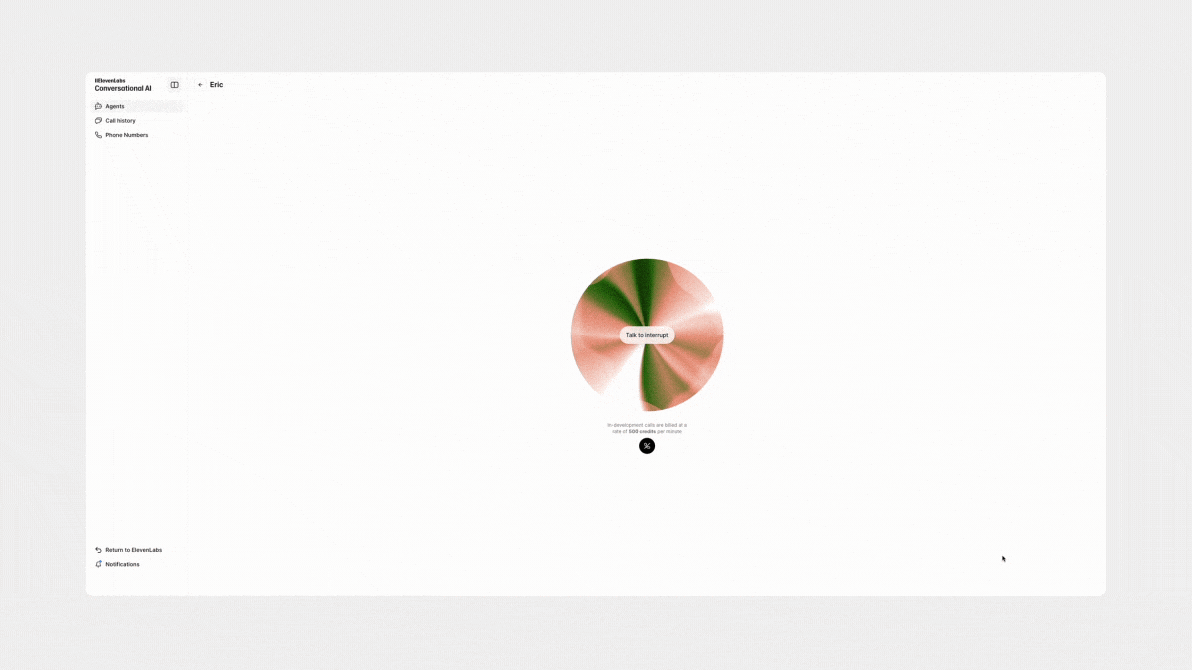
为什么这种程度的定制如此重要?有两个原因。首先,在现实生活中,我们说话很少是线性的。 人类是情感生物,而情境几乎总是会影响我们的交流。 例如,我们道歉时使用的语气与庆祝时使用的语气截然不同。为了使体验感觉更真实(并可能提高用户参与度——尽管有一个警告,我将在本文末尾详细说明),至关重要的是要使聊天机器人的说话风格与话语的含义和对话的背景相一致。
良好的沟通不仅仅是文字本身。根据 55/38/7 公式,只有 7% 的沟通是通过文字传达的。重要的 38% 来自声音的音调,而 55% 来自非语言线索 (nonverbal cues)。 这使得聊天机器人以一种感觉像人类和情感的方式做出回应至关重要。 这不仅仅意味着使语气与情境相匹配;它还要求聊天机器人在更深层次、更情感的层面上解释用户的输入,以确保真正的自然互动。
口音的作用
聊天机器人说话风格的另一个重要方面是它的口音。对于英语国家以外的用户来说,通常会有一种“标准”的英国口音的看法,有时——尽管越来越少——与公认发音 (RP) 相关联。然而,在英国,有近 40 种不同的地区口音,每种口音都有其独特的特征和身份,展示了英语口语的真正多样性。
ChatGPT语音模式中最令人惊讶和有趣的更新之一是它采用口音的能力。但这并不仅仅是为你的助手选择一种口音,这已经是一个常见的功能。 你现在可以要求助手用混合口音说话,例如在爱尔兰生活多年的波兰人的口音。 GPT在这方面处理得非常好,它将强烈的东欧发音与典型的爱尔兰英语的独特节奏和语调相结合,从而产生真实且非常有趣的互动。
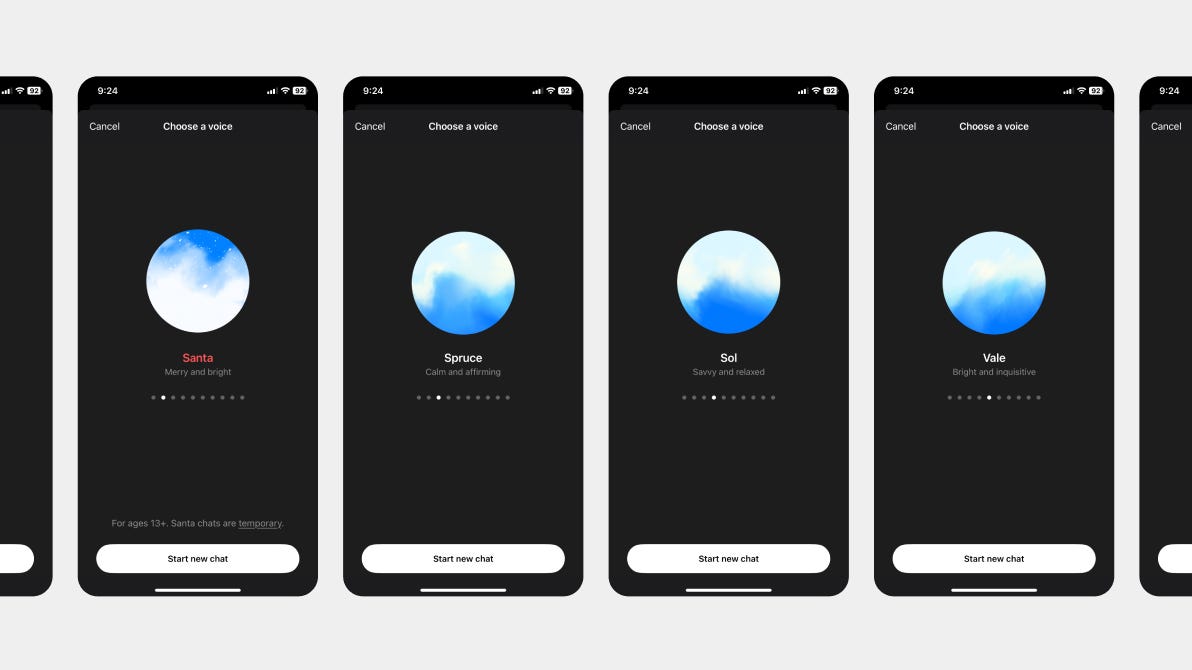
现在,假设你正在为英国不同地区设计一个客户服务聊天机器人。你的聊天机器人可以采用每个地区的当地口音,而不是提供一种通用的语音,从而为用户创造更相关和量身定制的体验。例如,纽卡斯尔的聊天机器人可以使用乔迪口音,而伯明翰的聊天机器人可能会采用伯明翰风格。这种程度的定制不仅会增强用户参与度,还会增加文化熟悉感,使互动感觉更加个人化和真实。
目前,没有一个可用的模型提供广泛的地区口音(这很不幸),但GPT确实包含有限的英语口音选择。随着该领域正在进行的实验,地区口音定制的未来看起来很有希望。
文本显示:平衡消息长度和用户体验
在聊天机器人消息长度方面,像GPT和Gemini这样的平台通常旨在平衡简洁性和深度。默认情况下,这些模型优先考虑简洁的响应,同时确保它们完全解决用户的查询。例如,简单的问题通常会导致平均约 20-50 个单词的答案。
然而,并非所有聊天机器人都需要遵循此公式。例如,一个讲故事的聊天机器人可能需要更长、更引人入胜的叙述来娱乐用户,其目标不仅仅是提供信息。
为什么这很重要?
将消息风格与产品的用途和对话的背景相一致至关重要。同时,过长的段落可能会让人感到不知所措,尤其是在UI没有设计为有效处理它们的情况下。周到的文本显示策略和交互在确保UI和UX保持一致的流畅用户体验方面发挥着至关重要的作用。
看看像GPT、Claude、Gemini和Grok这样流行的人工智能模型,我们可以观察到向用户显示信息的方式存在显著差异:
- GPT和Claude以类似打字机的方式呈现文本,其中单词的出现就像实时键入一样。虽然这增加了一些动态效果,但对于那些对视觉刺激或时间压力更敏感的用户来说,这可能会让他们感到紧张。
- Gemini采用不同的方法,在生成响应时显示一个闪烁的预加载器,这会让人感觉更有预期感,也不那么突兀。

- Grok 和 Pi.ai (基于Claude开发) 以更微妙和精致的展示方式脱颖而出。它们的文本显示流畅且令人愉悦,尤其是在生成的内容很长时,体验会特别舒适。

管理认知负荷
聊天机器人设计的另一个关键方面是通过减少视觉混乱和保持专注来管理认知负荷 (cognitive load)。例如,像Pi.ai这样的平台会在生成新响应时将较旧的响应移出视图。这种方法使界面保持整洁,并允许用户专注于最相关和最新的信息,而不会被聊天历史记录的混乱所淹没。
调整响应速度
语音聊天机器人中较少探索的模式之一是提供设置来调整响应速度。虽然类似的工具通常被屏幕阅读器用户使用,但它们在语音聊天机器人的背景下仍然是一种新奇事物。
现在,想象一下两个简单的滑块: 一个控制整体响应速度(聊天机器人说话的速度),另一个调整句子或段落之间的停顿。
这种解决方案既简单又非常强大,但它是在人工智能聊天机器人中尚未完全探索的领域。(如果您遇到提供类似功能的聊天机器人,请在评论中告诉我!)
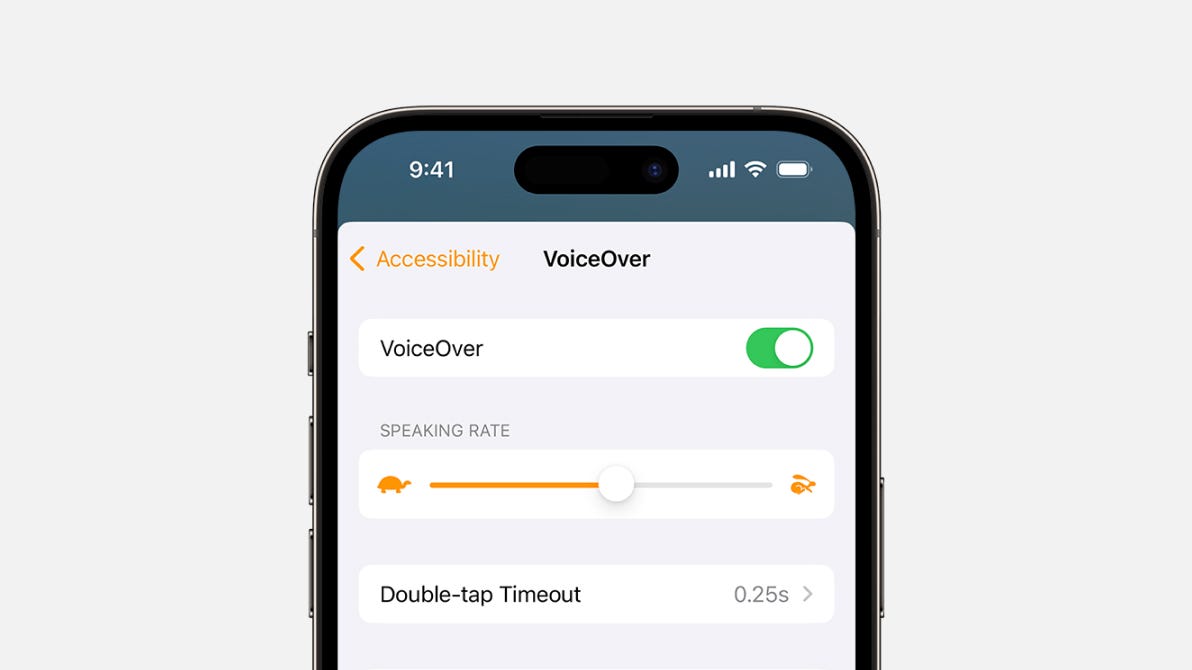
这种定制对于以下情况特别有帮助:
- 有听力障碍的用户需要更慢、更清晰的响应。
- 非母语人士,通常会从较慢的语速和较长的停顿中获益以进行理解。
- 有认知挑战的用户,更慎重的节奏有助于理解。
- 高压环境,其中较慢、较冷静的反应有助于减少焦虑(例如,心理健康或危机支持聊天机器人)。
集成此功能不仅可以提高可访问性,还可以创建更个性化和用户友好的体验。这是一个小的补充,但具有巨大的影响潜力。
其他对话动态与UI模式
在人与聊天机器人互动方面,目前有三种主要的UI模式:
- 语音到语音模式: 这是最自然和免提的选择,用户无需与设备进行物理交互即可进行通信。
- 按住说话模式: 用户按下并按住麦克风按钮即可与聊天机器人通话。
- 录音模式: 在大多数消息传递应用程序中都可以找到的熟悉模式,用户录制消息并将其发送给聊天机器人(或某人)进行处理。
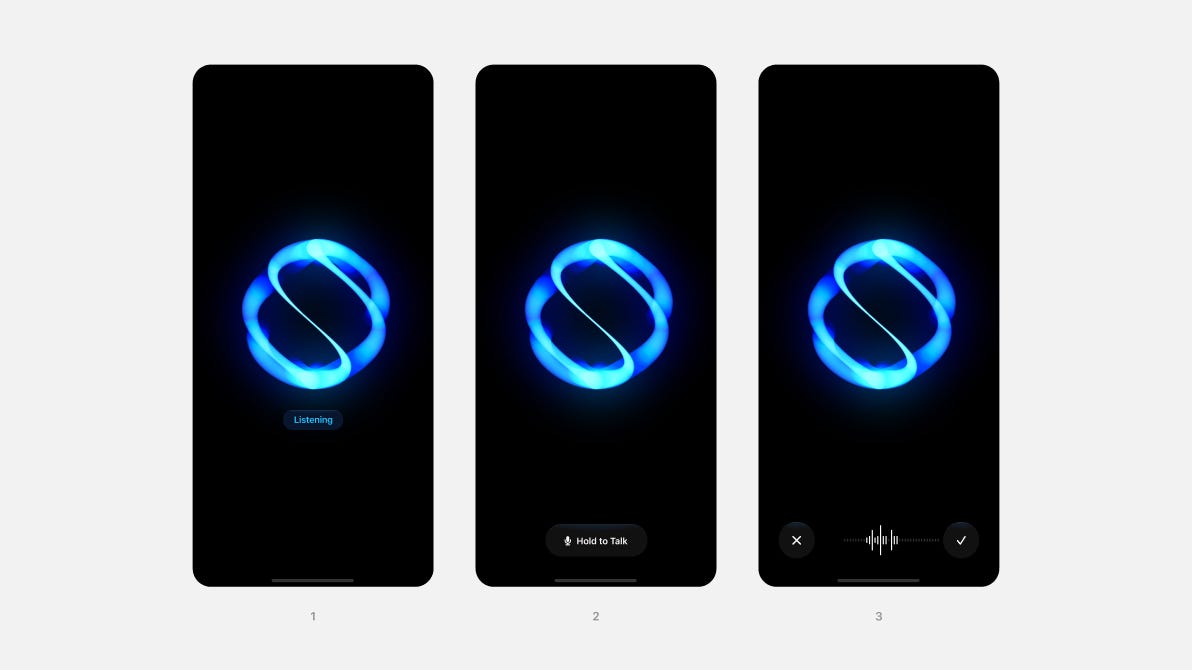
从沟通的角度来看,免提的语音到语音互动感觉最自然。然而,即使使用像ChatGPT这样的高级模型,它也带来了重大的用户体验挑战。 一个值得注意的问题是,聊天机器人仍然难以准确检测到用户何时说完话。
增强语音交互
在最新版本的GPT语音聊天机器人中,如果用户在句子中间停顿一下来整理思路,仍然会出现助手过早介入的偶然情况。虽然这会中断对话的流程,但GPT提供了一些显着改善体验的功能:
- 可中断性: 用户可以在助手响应过程中中断它。它会立即停止说话并恢复收听,允许用户无缝继续。
- 可调整的收听时间: 用户可以要求助手为他们的响应留出更多时间。此功能有助于确保思考时的停顿不会导致中断,从而实现更流畅的对话流程。
这些功能使最新版本的GPT成为目前最先进的语音聊天助手之一,展示了在解决语音到语音互动中常见挑战方面的显着进展。
可靠的语音输入方法
如果您正在设计聊天机器人界面,尤其是语音交互界面,那么承认这些挑战非常重要。在当前的技术阶段,最可靠的输入方法仍然是:
- 按住说话按钮: 一种简单而熟悉的方法,可最大程度地减少检测用户何时说完话的错误。
- 录音模式: 一种实用且广泛接受的异步语音输入解决方案。
虽然免提的语音到语音体验正在迅速改进,但它尚未臻于完美。目前,使用更受控制的交互模式(如按住说话或录音模式)进行设计将提供更安全、更一致的用户体验。最终,随着技术的发展,语音到语音的交互可能会变得无缝——但我们还没有完全达到那个水平。
总结
以上提到的所有观点都不应被视为设计过程的最终建议。 由于我们仍处于机器人时代的早期阶段——而聊天机器人本质上是一种机器人形式——我们无法完全预测用户将如何适应它们。一些聊天机器人可能以更自然、类人化的语气表现出色,而另一些聊天机器人则可能以僵硬的机器人方式表现更好。
当我们探索UX/UI设计的新篇章时,很明显,没有通用的公式或一刀切的解决方案。要创建高性能的聊天机器人,关键在于遵循迭代的过程:设计、测试、学习和重复。只有通过这个循环,我们才能改进和适应,以满足用户不断变化的需求和偏好。
我建议查阅的参考资料:
- 人工智能:60年来的第一个新UI范例 作者:Jakob Nielsen
- 什么是聊天机器人设计? 由 IBM.com 提供
- 构建面向客户的人工智能聊天机器人的艺术 由 Phaneendra Kumar Namala 提供
- 开始使用对话式UI和聊天机器人的最佳链接 作者:Caio Braga
- 声音的力量:声音如何塑造我们的情感和互动 作者:MillianSpeaks | 声音心理学
- 为人工智能设计:超越聊天机器人 作者:Ridhima Gupta
- 模仿你的口音的聊天机器人——并使用俚语 由Mark Sellman 为《星期日泰晤士报》撰写
- 认知负荷 (cognitive load) 和UI设计:简化界面以增强用户体验 作者:Jakub Wojciechowski
- 数字可访问性:了解屏幕阅读器的交互 作者:客户体验 Prudential
- 迭代设计:如何优化产品设计流程 作者:Vladimir Pavlov
- Web可访问性提示:给人们足够的时间 由互联网可访问性局提供