最近很多朋友都咨询我怎么在自己的电脑上部署 deepseek r1,我很好奇为啥大家都要在自己 PC 上部署模型,而不是直接使用 DeepSeek 官网提供的网页或 app 版本,有的人告诉我是因为好奇,有的人是为了蹭一蹭热点,有的人说是为了显得牛逼,有的人说 DeepSeek 官网不稳定等等,反正各有各的原因。但我觉得对于个人而言,如果不是因为隐私或机密数据不能对外共享,其实使用本地部署的模型意义不大,而本地PC 能部署的模型参数很小,只有 1.5B、7B、8B、14B、32B、70B 这几个蒸馏版本,能力和满血版 deepseek-r1 671B 的模型能力相差甚远。但鉴于这些朋友不是从事 AI 相关工作,我都会给每个人科普一下以上这些信息,并列出 DeepSeek-R1 论文中给的各个模型的对比评测结果,最后给出一些本地部署蒸馏的小模型的指南。在这里我也把整理的内容分享给大家,有需要可自取。
评测结果
满血版的 deepseek-r1 671B 的模型评测结果
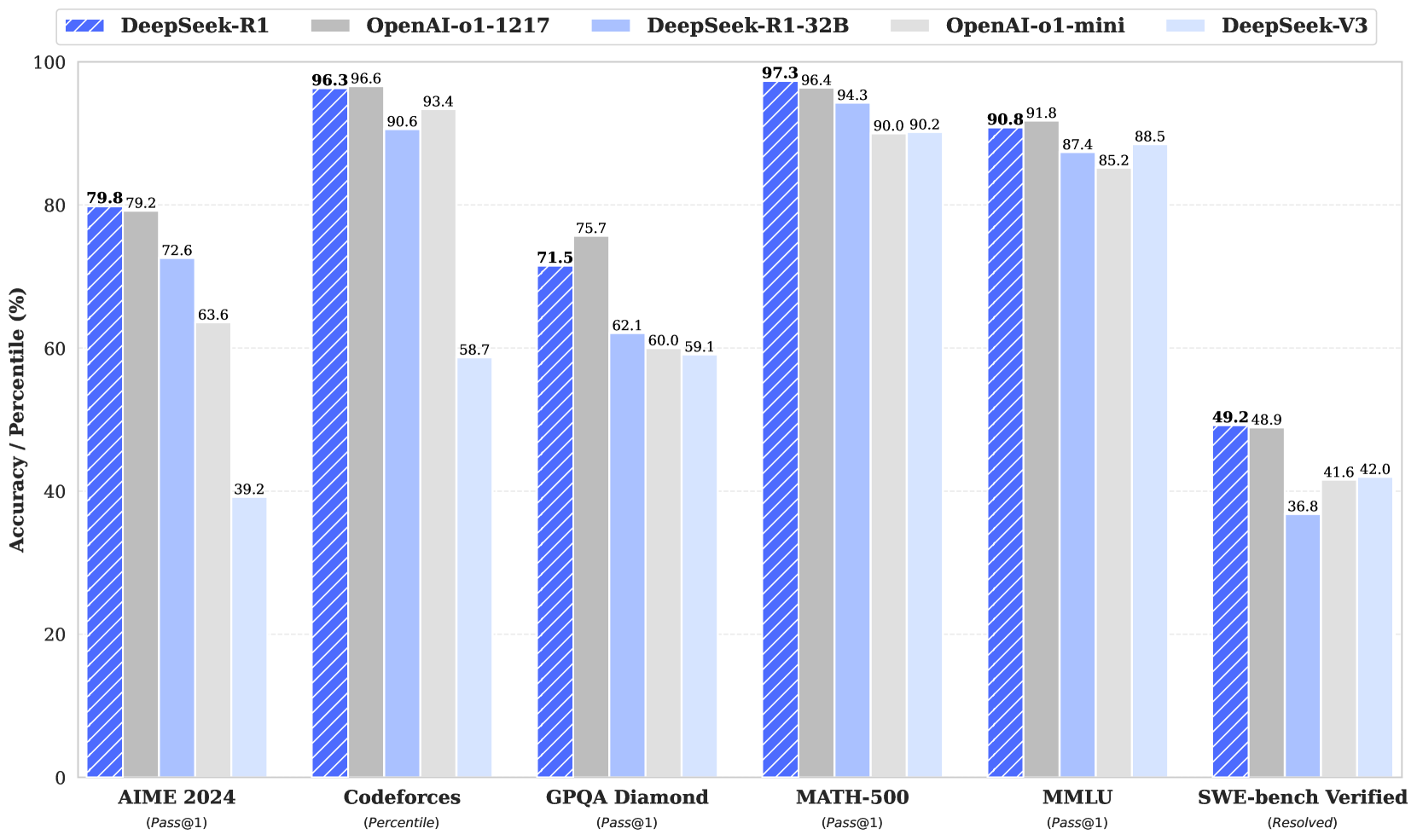
从上面结果可以看出来,DeepSeek-R1 的能力水平和 OpenAI 的 openai-o1-1217 版本能力相当,甚至有些评测集上要更好。这里我也解释一下上面横轴上的不同评测集的含义:
- AIME 测试集
2024 是指 2024 年的美国数学邀请赛(American Invitational Mathematics Examination),这是一项针对高中生的数学竞赛,旨在选拔优秀学生进入更高级别的数学竞赛。在人工智能领域,AIME 2024 的试题被用作评估大型语言模型(LLM)数学推理能力的基准数据集。另外,AIME(美国数学邀请赛)共有15道填空题,答案为0到999之间的整数。题目难度呈递增趋势,前5题相对简单,难度与AMC10/12相近,后10题难度逐渐增加,考察学生的数学综合应用和计算能力。
- Codeforces 评测集
Codeforces是一个知名的在线编程竞赛平台,汇集了大量高质量的编程题目和用户提交的解决方案。由于其题目多样性和挑战性,研究人员常将 Codeforces 的题目用作评估大型语言模型(LLM)编程和推理能力的基准数据集。
- GPQA Diamond 评测集
GPQA Diamond 是一个专门设计用于评估大型语言模型(LLM)在需要深度推理和领域专业知识问题上的能力的基准数据集。该数据集由纽约大学、CohereAI 和 Anthropic 的研究人员联合发布,旨在衡量模型在需要深度推理和领域专业知识问题上的能力。GPQA Diamond 数据集包含 198 道高难度的问答题,主要涵盖物理、化学、生物学和经济学等 STEM 领域。所有问题及其答案都经过领域专家的验证,确保准确性和完整性。这些问题设计为对抗性构建,防止模型依赖表面模式或记忆,强调深度理解和多步骤推理能力。在评估中,模型需要生成准确且完整的答案,主要评估指标为准确率。GPQA Diamond 为研究人员提供了一个具有挑战性的基准,用于评估和改进大型语言模型在复杂推理任务中的表现。
- MATH-500 评测集
MATH-500 是一个包含 500 道数学题目的评测集,旨在全面考察大型语言模型(LLM)的数学解题能力。该评测集涵盖了多种数学主题,设计用于评估模型在数学推理和问题解决方面的表现。
- MMLU 评测集
MMLU(Massive Multitask Language Understanding)是一个大规模多任务语言理解的基准测试数据集,专门用于评估大型语言模型在不同知识领域下的理解和推理能力。该数据集由大约1.6万道多项选择题组成,覆盖了57个学科,涉及数学、历史、计算机科学、法律、医学等多个领域,从基础知识到专业知识均有考察。它设计为零样本或少样本(few-shot)测试,旨在衡量模型在预训练阶段学到的广泛世界知识和问题解决能力。
MMLU 自 2020 年由 Dan Hendrycks 及其团队发布以来,就成为衡量大模型性能的重要指标之一。由于题目涵盖面广、难度层次丰富,它能够揭示模型在多任务、多领域知识上的盲点,因此被广泛应用于如Open LLM Leaderboard、HELM等多个评测平台上。简单来说,MMLU 就是一个通过大量多选题来综合评估大语言模型“通才”能力的工具。
- SWE-bench Verified 评测集
SWE-bench Verified 是 OpenAI 推出的一个经过人工验证的基准测试数据集,旨在更准确地评估大型语言模型(LLM)在解决现实世界软件工程问题方面的能力。该数据集是对原始 SWE-bench 的改进版本。原始的 SWE-bench 从 12 个流行的 Python 仓库中收集了 2294 对 Issue 和 Pull Request,用于评估模型解决实际软件问题的能力。然而,原始版本存在一些局限性,例如单元测试过于具体、问题描述不明确以及开发环境设置困难等,这可能导致对模型能力的低估。为了解决这些问题,OpenAI 与专业软件开发人员合作,对 SWE-bench 测试集中的每个样本进行了人工筛选,确保其具有适当范围的单元测试和明确的问题描述。 最终,发布了包含 500 个经过验证样本的 SWE-bench Verified 数据集。 
用满血版 deepseek-r1 蒸馏出的其他小模型的评测结果
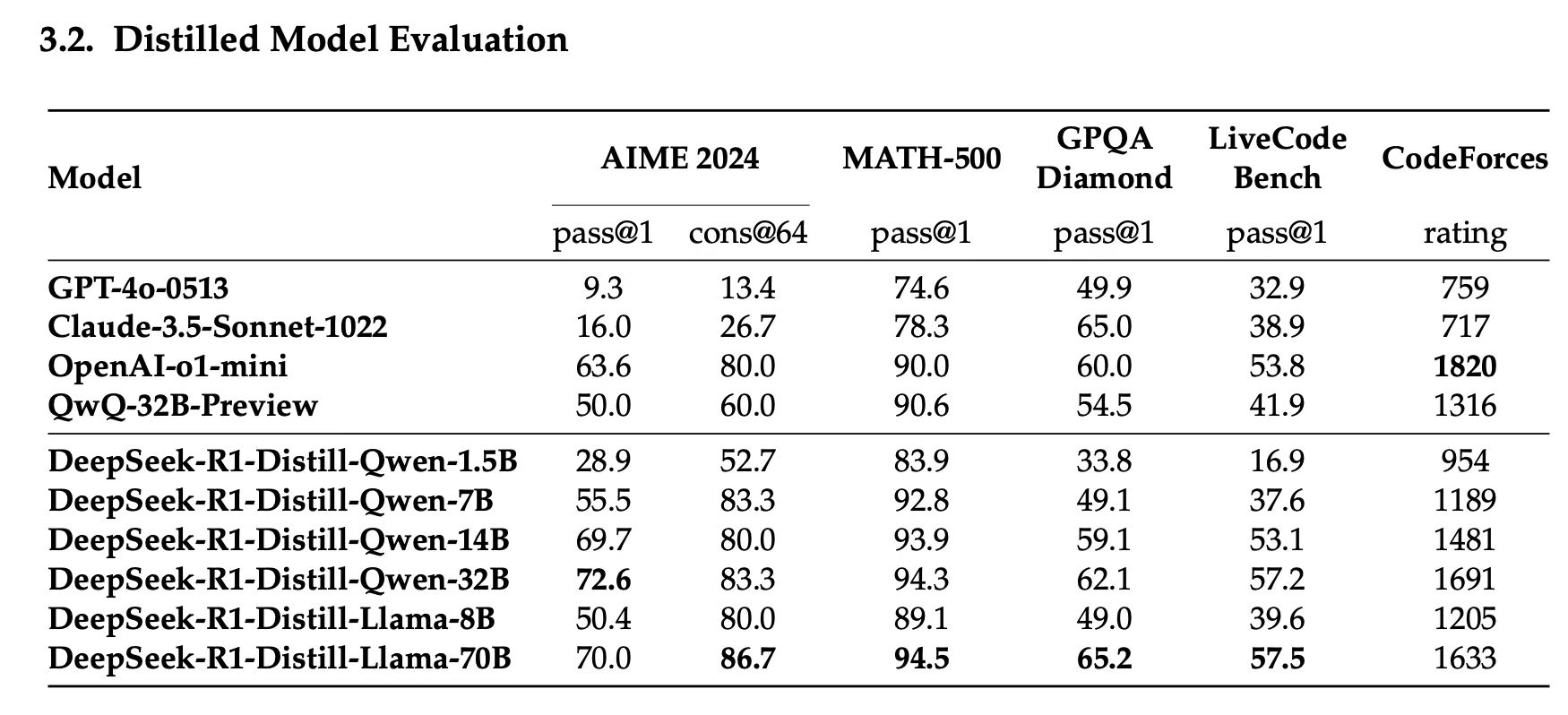
从上面结果可以看出来,蒸馏版模型的基座模型是阿里的千问和 Meta 的 Llama,DeepSeek 通过 r1 蒸馏出了五个小模型,分别是:DeepSeek-R1-Distill-Qwen-1.5B、DeepSeek-R1-Distill-Qwen-7B、DeepSeek-R1-Distill-Qwen-14B、DeepSeek-R1-Distill-Qwen-32B、DeepSeek-R1-Distill-Llama-8B、DeepSeek-R1-Distill-Llama-70B 。这些模型能力和满血版的 deepseek-r1 671B 相差甚远,但大多数超过了 gpt-4o 和 claude 3.5 sonnet 的能力,有的基本可以和 openai-o1-mini 水平相近。但考虑到大家的日常使用用途,我还是建议大家直接用 DeepSeek 官网或 app 版本即可,毕竟是满血版的 r1 模型其能力更强,重要的可以联网,并且可以免费无限量使用,虽然短期内由于用户量太大,官网或 app 版本会不稳定,但预计 1 周左右即可彻底解决,说白了还是因为用户量太大导致卡不够用了,但国内外很多云厂商都支持了,国产的卡也支持了。
为何无法在普通 PC 上部署“满血版” 671B 参数 deepseek-r1 模型?
部署 DeepSeek R1 “满血版” 671B 模型,需要构建一个高端服务器集群环境:
- CPU:64 核或更多的服务器级处理器
- 内存:至少 512GB RAM
- 存储:高速 NVMe SSD,300GB 以上(建议预留更大空间)
- GPU:多卡并行(例如 8× A100/H100 或等效配置,总显存 ≥350GB)
- 网络:高速互联(200 Gbps 级别),以支持分布式任务
- 电源与散热:工业级电源和冷却系统
这种配置主要适用于科研机构、国家级项目或大型企业数据中心,对于一般用户和中小企业来说,通常更推荐使用蒸馏版或量化版模型,以降低硬件门槛。
蒸馏版模型在本地 PC 上部署与硬件要求
| 模型名称 | CPU | 内存 | 存储空间 | 显卡要求 | 适用场景 |
|---|---|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | 4 核 (Intel/AMD) | 8GB+ | ≥3GB | 纯 CPU 可行;GPU ≥4GB(GTX 1650) | 低资源设备、实时文本生成、嵌入式或物联网 |
| DeepSeek-R1-Distill-Qwen-7B | 8 核 | 16GB+ | ≥8GB | GPU ≥8GB(RTX 3060, RTX 3070) | 本地开发、测试、中等复杂度 NLP 任务 |
| DeepSeek-R1-Distill-Qwen-14B | 12 核 | 32GB+ | ≥15GB | GPU ≥16GB(RTX 3080, RTX 4090) | 企业级任务,长文本理解、报告生成、代码推理 |
| DeepSeek-R1-Distill-Qwen-32B | 16 核 (Ryzen 9 / i9) | 64GB+ | ≥30GB | GPU ≥24GB(RTX 3090, A100, 多卡并行) | 高精度任务,如医疗、法律咨询、多模态任务 |
| DeepSeek-R1-Distill-Llama-8B | 8 核 | 16GB+ | 4-6GB | GPU ≥8GB(RTX 3060 Ti, RTX 3070) | 低资源占用,适用于响应速度要求较高的任务 |
| DeepSeek-R1-Distill-Llama-70B | 32 核 (多路 Xeon/EPYC) | 128GB+ | ≥70GB | 2×A100 80GB 或 4×RTX 4090,需 NVLink/InfiniBand | 高复杂度任务,如金融预测、大规模数据分析 |
关键配置说明
显存优化策略
- 量化技术:优先选择 4-bit/8-bit量化模型(如GGUF格式),显存需求可降低至原大小的1/4~1/2。
- 多GPU并行:70B参数模型需通过 Tensor并行 或 流水线并行 拆分至多卡(如4×24GB显存的RTX 4090)。
- 显存交换:使用
vLLM或DeepSpeed框架,允许显存不足时借用内存(速度下降约30%)。
CPU模式注意事项
- 内存要求:模型加载需占用内存 ≈ 参数量 × 2字节(FP32)。例如,32B模型需约64GB内存(FP32未量化)。
- 速度瓶颈:纯CPU推理速度较慢(如7B模型生成100词需约2分钟),建议启用多线程(设置
OMP_NUM_THREADS)。
如何部署?
使用 Ollama(适合新手)本地部署
ollama pull deepseek-r1:1.5b
- 用以下命令运行模型,进入交互式窗口进行问答
ollama run deepseek-r1:1.5b
或者单次运行以下命令进行测试
ollama run deepseek-r1:1.5b "你好,介绍一下自己"
云端部署
阿里云、火山云、腾讯云、华为云、微软 Azure 等云厂商都支持了 deepseek-r1 671B 满血版的部署与在线使用,大家可自行选择,我通过火山云的后台用了 deepseek-r1 满血版,体验还可以。
DeepSeek r1 系列模型列表
DeepSeek-R1 模型列表
| Model | #Total Params | #Activated Params | Context Length | Download |
|---|---|---|---|---|
| DeepSeek-R1-Zero | 671B | 37B | 128K | 🤗 HuggingFace |
| DeepSeek-R1 | 671B | 37B | 128K | 🤗 HuggingFace |
DeepSeek-R1 蒸馏模型列表
| Model | Base Model | Download |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Math-7B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct | 🤗 HuggingFace |