2025 年 Google I/O 大会首日以 “从研究到现实(From research to reality)” 为主题,重点聚焦 AI 生态。第一天发布了大量的 AI 相关的强的不得了的功能,让人目不暇接,可以说是脚踢 OpenAI,吊打 Claude 和 Perplexity 这一帮 AI 新秀了,老大哥的技术底蕴还是够强。话不多说,让我们快看一些到底发布了哪些内容吧。
Gemini 2.5 模型更新
Gemini 2.5 Pro 已成为编码和学习领域的领先模型,而 2.5 Flash 则在效率和速度方面得到显著优化。此次更新引入了多项新能力,包括实验性的高级推理模式 Deep Think 、原生的音频输出、计算机使用功能以及增强的安全防护。
Gemini 2.5 Pro 性能提升:
- 在 WebDev Arena 编码排行榜上以 ELO 分数 1415 排名第一。
- 在 LMArena 的所有排行榜上均表现出色,评估结果显示人类偏好度高。
- 拥有 1 百万- token 上下文窗口,在长上下文和视频理解方面达到领先水平。
- 整合 LearnLM 后,成为学习领域的领先模型,在教育专家评估中优于其他模型。
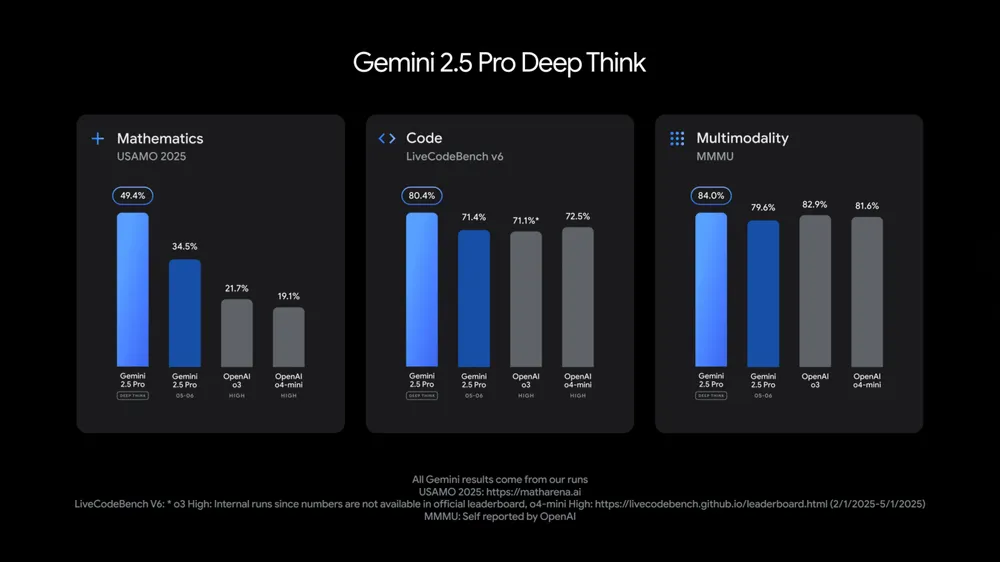
Deep Think (2.5 Pro 的实验性模式):
- 一种增强推理模式,通过考虑多个假设来回应。
- 在 2025 USAMO (数学基准)上获得高分。
- 在 LiveCodeBench (竞赛级编码基准)上领先。
- 在 MMMU (多模态推理)上得分 84.0 %。
- 将首先通过 Gemini API 提供给可信测试者进行安全评估。
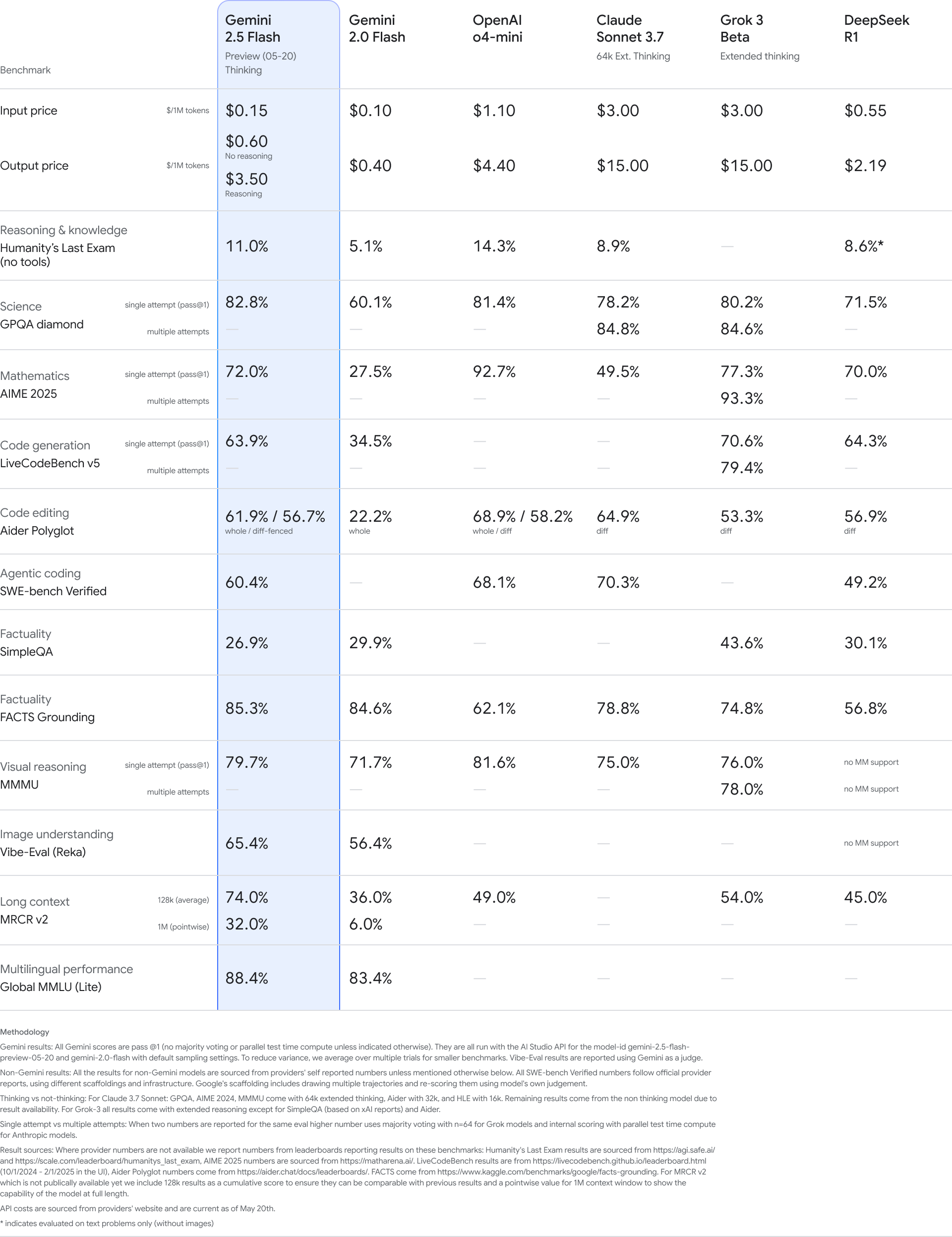
Gemini 2.5 Flash 改进(0520版本):
- 定位为最高效的工作模型,注重速度和低成本。
- 在推理、多模态、代码和长上下文等关键基准上均有提升。
- 效率更高,评估显示使用 20 - 30 % 更少的 tokens 。
- 已在 Google AI Studio 、 Vertex AI 和 Gemini app 中提供预览,预计 6 月初全面上市。
Gemini 2.5 新功能:
原生音频输出和 Live API :
- Live API 引入了音视频输入和原生音频输出对话的预览版,支持更自然、富有表现力的对话体验。
- 允许用户控制模型的语调、口音和说话风格,并支持工具使用。
- 早期功能包括: Affective Dialogue (情感检测)、 Proactive Audio (忽略背景对话并适时回应)和 Thinking in the Live API (利用思维能力处理复杂任务)。
- 2.5 Pro 和 2.5 Flash 新增文本转语音预览,首次支持多说话人(双语音)。
- 文本转语音功能富有表现力,能捕捉细微差别(如耳语),支持超过 24 种语言。
计算机使用( Project Mariner ):
- 其能力已整合到 Gemini API 和 Vertex AI 中。
- Automation Anywhere 、 UiPath 等公司正在探索其潜力,计划于今年夏天更广泛地推出给开发者。
- 显著增强了对间接提示注入(恶意指令嵌入到模型检索数据中)等安全威胁的防护。
- Gemini 2.5 成为迄今为止最安全的模型系列。
增强的开发者体验:
思维摘要(Thought summaries):
- 2.5 Pro 和 Flash 将在 Gemini API 和 Vertex AI 中提供思维摘要。
- 将模型的原始思考过程整理成清晰的格式,包含标题、关键细节和模型动作(如工具使用),便于理解和调试。
思考预算(Thinking budgets):
- 此功能已扩展到 2.5 Pro ( 2.5 Flash 已有)。
- 允许开发者控制模型在回应前用于思考的 tokens 数量,或关闭思考能力,以平衡延迟和成本。
- 带有预算功能的 Gemini 2.5 Pro 将在未来几周内全面上市。
MCP 支持:
- Gemini API 中增加了对 Model Context Protocol ( MCP ) 定义的原生 SDK 支持,以便更轻松地集成开源工具。
- 正在探索部署 MCP 服务器和其他托管工具,以简化代理应用程序的构建。
生成式媒体与创意工具革新
Veo 3 与 Flow:开启AI电影制作新时代
Veo 3 是谷歌最新的视频生成模型,可生成带有音频的视频片段(例如街头的汽车噪音、鸟鸣、人物对话等),大幅超越之前的 Veo 2。如 Google DeepMind 首席执行官德 Demis Hassabis 所说:我们正在“走出视频生成的无声时代”。这个是目前为止最为强大的视频生成模型,OpenAI 的 Sora 自去年首秀依赖风光不再啊。另外有一点值得说,现在在 Google lead 视频生成项目的人之前是 OpenAI Sora 的头,离开的原因估计是资源分配的问题,OpenAI 把核心力量投入到了模型智能上面了,才有了现在的 O 系列的模型,而Google 这边管够,人才给、GPU 也给,这效果就来了。
Veo 3 在理解复杂场景和同步唇形方面表现优异,只要简单的故事提示,就能生成连贯的片段。另外,Veo 2 也升级了新功能,包括“参考驱动视频”模式(可提供参考图像控制角色、场景、风格)、精细摄影机控制(平移、旋转、缩放等)、画布扩展(支持从竖屏扩展到横屏)及对象增删(可添加/删除视频中物体)等。这些工具目前已在 Flow 中开放给创作者体验,并将逐步推向 Vertex AI API 。
与 Veo 3一同发布的“Flow”功能,是一个AI驱动的电影制作工具,它集剧本编写、摄影和剪辑功能于一身,极大地简化了视频创作流程。Flow 能帮助故事创作者将想法转化为电影场景,无需高昂的制作成本或复杂的专业技能。用户可以输入“一个侦探在下雨的东京小巷里追逐小偷”这样的提示,Veo 3 就会将其生动呈现,并配以逼真的声音和电影般的灯光效果。Flow 还允许用户灵活调整摄像机角度、缩放、切换视角,并通过添加镜头和重新混合元素来构建复杂场景,同时智能地保持内容的一致性,确保故事的连贯性 。
Veo 3 已在美国的 Google AI Ultra 订阅用户中提供,Flow 则面向 Google AI Pro 和 Ultra 用户推出,未来将扩展到更多国家,让更多创作者有机会体验这项革命性工具。
Imagen 4:提升图像生成质量与细节
在图像生成方面,谷歌推出了Imagen 4,在速度和精度上兼顾提升:它在细节表现(如织物纹理、水滴、动物毛发)和多种风格(写实或抽象)上都更清晰,支持多种比例和最高 2K 分辨率,输出海报、贺卡、漫画等更易读写文字 。Imagen 4 即日可在 Gemini App、Whisk、Vertex AI 以及 Google Slides/Vids/Docs 等 Workspace 应用中使用 。谷歌还将很快推出 Imagen 4 的高效版,速度相比 Imagen 3 提升高达 10 倍,极大加速创意迭代。
Veo 3、Imagen 4 和 Lyria 2 生成的内容将继续使用 SynthID 水印,
Lyria 2:音乐创作工具
音乐创作工具方面,则有基于 Lyria 2 的“音乐 AI 沙箱”对创作者开放,YouTube Shorts 和 Vertex AI 用户可使用;实时音乐生成模型 Lyria RealTime 也通过 API 和 AI Studio 对外开放。
Google 的自我革命:AI Mode
自去年 I/O 大会推出以来,AI Overviews 已成为过去十年中最成功的 Search 发布之一。它促使人们提出更复杂、更长和多模态的问题,并在美国和印度等主要市场推动了相关查询的使用量增加超过 10% 。 从今天起在美国全面推出 AI Mode,提供更高级的推理能力和多模态交互,并支持通过后续问题和链接进行更深入的探索。采用“query fan-out”技术,将问题分解为子主题并同时执行多项查询,以深入挖掘网络内容。率先集成 Gemini 的前沿能力,包括定制版的 Gemini 2.5 模型。
- Deep Search: AI Mode 中的深度研究功能,能够进行数百次搜索,整合不同信息,并在几分钟内生成专家级的、带有引用的报告,节省用户数小时的研究时间。
- Live capabilities (实时功能): 将 Project Astra 的实时能力引入 Search。用户可以通过摄像头与 Search 进行实时双向对话,获取视觉内容的解释和建议,并提供相关资源链接。此功能建立在每月超过 15 亿人使用的 Google Lens 基础上。
- Agentic capabilities (代理能力): 将 Project Mariner 的代理能力引入 AI Mode,帮助用户完成任务,如购买活动门票、预订餐厅和当地预约。它能分析数百个选项,处理实时定价和库存,并协助填写表格,与 Ticketmaster 、 StubHub 、 Resy 和 Vagaro 等公司合作。
- AI 购物伙伴: 结合 Gemini 模型和 Shopping Graph ,提供虚拟试穿(上传一张图片即可试穿数十亿件服装),并能通过新的代理结账功能,在价格合适时通过 Google Pay 代用户完成购买。
- Personal context (个人上下文): AI Mode 将根据用户的历史搜索提供个性化建议,并可选择连接其他 Google 应用(首先是 Gmail ),以获取更多个人上下文(例如,根据航班和酒店预订提供当地活动建议)。用户始终拥有数据连接的控制权。
- Custom charts and graphs (自定义图表): AI Mode 能够分析复杂数据集,并根据用户查询创建定制的交互式图表,最初将应用于体育和金融查询。
- 发布计划: AI Mode 从今天开始在美国全面推出。所有在 I/O 大会上展示的新功能将在未来几周和几个月内首先向 AI Mode 的 Labs 用户开放。
个性化体验
个性化方面,Gemini 模型将能够在用户授权下访问个人搜索历史、Gmail、Drive 等资料,实现更贴合个人情境的服务。如新的 Gmail 智能回复功能会用你过去的行程资料自动撰写建议回复信件,风格更接近本人。Google 表示这些个性化能力将在未来更广泛地应用于搜索、Gemini 等产品中。
Gemini App
Gemini App 推出一系列更新,这些更新涵盖了从视觉和视频生成到深度研究、创意创作和学习辅助等多个方面,并通过新的订阅计划提供更高级的功能和早期访问权限。
- Gemini Live 免费开放: 具备摄像头和屏幕共享功能,现已免费向所有 Android 和 iOS 用户开放。用户可以通过指向实物进行对话,平均对话时长是文本对话的 5 倍。未来将更深入地集成 Google Maps、Calendar、Tasks 和 Keep 等应用。
- 图像和视频生成模型:
- Imagen 4: 全新的图像生成模型,已内置于 Gemini 应用中,以高质量、更好的文本渲染和速度著称,所有用户均可使用。
- Veo 3: 全新的视频生成模型,全球首个原生支持音效、背景噪音和角色对话的模型,目前供美国地区的 Google AI Ultra 订阅者使用。
- Deep Research 增强: 用户现在可以将公共数据与自己的私人 PDF 和图像结合,生成定制化的研究报告。未来还将支持从 Google Drive 和 Gmail 中提取信息。
- Canvas 创作空间: Gemini 应用内的创意空间,结合 Gemini 2.5 模型,可创建交互式信息图、测验和 45 种语言的播客式 Audio Overviews。2.5 Pro 模型还能将复杂想法快速准确地转化为可运行的代码。
- Gemini 整合至 Chrome: 将开始向美国地区使用英语 Chrome 语言的 Windows 和 macOS 上的 Google AI Pro 和 Google AI Ultra 订阅者推出。初期版本可用于澄清网页信息或总结内容,未来将支持跨多标签页操作和网页导航。
- 交互式测验(Quiz): 已向全球所有 Gemini 用户推出,提供即时反馈和个性化后续测验。美国、巴西、印度尼西亚、日本和英国的大学生有资格免费获得一学年的 Google AI Pro 计划。
- 新订阅计划:
- Google AI Pro: 每月 $19.99 ,取代并扩展了 Gemini Advanced,包含 Flow、NotebookLM 等 AI 工具,并提供更高的速率限制。
- Google AI Ultra: 每月 $249.99 (首次用户前三个月可享 50 % 折扣),提供最高速率限制和实验性 AI 产品的早期访问权限。该计划的用户将获得最高级别的访问权限,包括 Veo 3 和即将推出的 2.5 Pro Deep Think 模式,以及早期访问 Agent Mode(一种能自动完成复杂多步骤任务的实验性功能)。目前仅在美国可用。
- 默认模型: 2.5 Flash 已成为新的默认模型,兼具高质量和闪电般的响应速度。
Project Astra:通用 AI 助手
Google 的愿景是构建一个“通用 AI 助手”,通过将 Gemini 扩展为能够理解和模拟世界的“世界模型”,并整合先进的代理能力,使其能像人类大脑一样进行规划和想象。这个 AI 助手将具备智能、上下文理解能力,并能在各种设备上代表用户规划和执行任务,最终目标是提高生产力、丰富生活,并推动科学进步。
世界模型:Google 正在将其多模态基础模型 Gemini 2.5 Pro 扩展为“世界模型”,使其能够通过理解和模拟世界来制定计划并想象新体验。这建立在 Google 在 Transformer 架构、AlphaGo 和 AlphaZero 等代理系统方面的开创性工作之上,并已在 Gemini 的世界知识、Veo 的直观物理理解以及 Gemini Robotics 的机器人控制能力中初见端倪。
实时能力:作为研究原型,Project Astra 探索了视频理解、屏幕共享和记忆等功能,并已逐步整合到 Gemini Live 中。目前已升级了更自然的语音输出、改进了记忆功能并增加了计算机控制。未来计划将这些能力引入 Gemini Live、Search、Live API 供开发者使用,以及眼镜等新形态产品中。安全和责任是此过程的核心考量。
Project Mariner 的多任务代理能力:这是一个探索人机交互的研究原型,最初应用于浏览器,旨在帮助用户处理多任务。Project Mariner 现在包含一个代理系统,能够同时完成多达十项不同的任务,例如信息查询、预订、购物和研究。更新后的 Project Mariner 已面向美国 Google AI Ultra 订阅者开放,并计划将更多计算机使用能力引入 Gemini API 和其他 Google 产品。
长远目标:通过这些创新工作,Google 致力于构建更个性化、主动和强大的 AI,以丰富人们的生活,加速科学进步,并开启一个发现和奇迹的新时代。
Project Mariner:代理模式
Google 正在积极推进代理(Agent)技术,将其定义为结合先进 AI 模型和工具、能代表用户执行操作的系统。核心进展包括将早期原型 Project Mariner 的计算机使用能力通过 Gemini API 提供给开发者,并构建一个更广泛的代理生态系统,包括 Agent2Agent Protocol 和对 Model Context Protocol ( MCP ) 的支持。此外,Google 正在将代理能力,特别是新的 Agent Mode,整合到 Chrome、Search 和 Gemini 应用中,以提升用户效率和企业价值。
- Project Mariner 的发展与开放: Project Mariner 是 Google 早期研究原型,专注于代理的计算机使用能力,使其能与网络交互并完成任务。自去年 12 月发布以来,它已新增多任务处理能力和“teach and repeat”方法(通过一次演示学习并应用于类似任务)。其计算机使用能力将通过 Gemini API 提供给开发者,目前 Automation Anywhere 和 UiPath 等受信任的测试者已开始使用,预计今年夏天将更广泛地开放。
- 代理生态系统与协议: 计算机使用能力是构建完整代理生态系统所需工具的一部分。该生态系统还包括 Agent2Agent Protocol(用于代理间通信)和 Anthropic 引入的 Model Context Protocol ( MCP )(允许代理访问其他服务)。目前,Gemini API 和 SDK 已与 MCP 工具兼容。
- 代理能力集成与 Agent Mode: Google 正将代理能力引入 Chrome、Search 和 Gemini 应用。其中,Gemini 应用中的新 Agent Mode 将显著提升用户效率。例如,在公寓搜索场景中,它能帮助用户在 Zillow 等网站上找到符合条件的房源,调整筛选条件,利用 MCP 访问房源信息,甚至安排看房。Gemini 应用的实验版 Agent Mode 即将向订阅用户推出,预计将为 Zillow 等公司带来新客户并提高转化率。
Google Beam:沉浸式视频通话
Google Beam 是一种新的 AI 优先视频通信平台,将 2D 视频流转换为逼真的 3D 体验,具备近乎完美的头部追踪(毫米级,60 帧/秒)。首批设备将与 HP 合作,于今年晚些时候提供给早期客户。
Google Beam 引入近乎实时的语音翻译功能,能匹配说话者的声音、语调和表情。英语和西班牙语的 Beta 版已向 Google AI Pro 和 Ultra 订阅者推出,更多语言将在未来几周内上线,并于今年提供给 Workspace 商业客户进行早期测试。
开发者相关
Gemini 模型与新模型发布
- Gemini 2.5 Flash Preview:推出新版本,在编码和复杂推理任务上表现更强,并针对速度和效率进行了优化。
- 透明度和控制:Gemini 2.5 模型现已提供 “Thought summaries”,并计划在 Gemini 2.5 Pro Preview 中引入 “thinking budgets”,以帮助开发者管理成本和控制模型行为。
- 可用性:Gemini 2.5 Flash 和 2.5 Pro 均在 Google AI Studio 和 Vertex AI 中提供 Preview 版本,Flash 预计 6 月初全面推出,Pro 随后。
- Gemma 3n:最新、快速高效的开放多模态模型,可在手机、笔记本电脑和平板电脑上运行,支持音频、文本、图像和视频。可在 Google AI Studio 和 Google AI Edge 预览。
- Gemini Diffusion:实验性文本模型,生成速度是现有最快模型的 5 倍,同时保持编码性能。
- Lyria RealTime:实验性交互式音乐生成模型,允许用户实时创建、控制和演奏音乐,通过 Gemini API 提供。
- Gemma 家族变体:
- MedGemma:专为医疗健康应用设计的开放多模态医疗文本和图像理解模型,已通过 Health AI Developer Foundations 提供。
- SignGemma:即将推出的开放模型,能将手语(主要为美国手语)翻译成口语文本。
提升 AI 构建效率的工具
- Colab:将升级为完全 agentic 的体验,能根据用户指令在 notebook 中执行操作、修复错误和转换代码。
- Gemini Code Assist:免费的 AI 编码助手(个人版)和代码审查 agent(GitHub 版)现已全面可用,由 Gemini 2.5 提供支持,未来将支持 2 million token 的上下文窗口。
- Firebase Studio:新的云端 AI 工作区,简化全栈 AI 应用开发,支持导入 Figma 设计并自动配置后端。
- Jules:异步编码 agent,已向所有人开放,可处理随机任务、积压的 bug、多任务,并能初步构建新功能,直接与 GitHub 协作。
- Stitch:新的 AI 驱动工具,通过自然语言描述或图像提示生成高质量 UI 设计和前端代码(桌面和移动),并支持会话式迭代和导出。
Gemini API 更新
- Google AI Studio 更新:支持使用 Gemini 2.5 模型和 Imagen、Veo 等生成式媒体模型,以及原生图像生成。Gemini 2.5 Pro 已集成到原生代码编辑器中。
- Native Audio Output & Live API:Gemini 2.5 Flash 模型(Preview)新增功能,包括主动视频、主动音频和情感对话。
- Native Audio Dialogue:Gemini 2.5 Flash 和 2.5 Pro 的文本转语音 (TTS) 功能预览,支持复杂单/多说话人语音输出,并可精确控制语音风格、口音和语速。
- Asynchronous Function Calling:允许在后台调用长时间运行的函数或工具,不阻塞主对话流。
- Computer Use API:允许开发者构建可浏览网页或使用其他软件工具的应用,已向 Trusted Testers 提供。
- URL Context:新的实验性工具,从 URL 获取完整页面上下文。
- Model Context Protocol (MCP):Gemini API 和 SDK 将支持 MCP,方便开发者使用各种开源工具。
Android XR 拓展
- 将 Gemini 引入手表、汽车仪表盘和电视。
- 构建 Android XR 平台,支持头戴设备和眼镜等多种 XR 设备形态。与 Samsung 和 Qualcomm 合作开发。
- 头戴设备: Samsung 的 Project Muhan 是首款 Android XR 设备,提供无限屏幕体验,用户可通过 Gemini 探索应用、在 XR 中“瞬移”到世界各地、查看视频和网站。将于今年晚些时候上市。
- 眼镜: 轻巧便携,内置摄像头、麦克风、扬声器和可选的镜片内显示屏,可与手机配合使用,实现免提 AI 互动。原型机已供受信任的测试者使用,开发者可于今年晚些时候开始开发。Gentle Monster 和 Warby Parker 将成为首批眼镜合作伙伴。
- 现场演示了眼镜的实时翻译、导航、信息查询和拍照功能。