前段时间看了 Andrew Ng 在红杉组织的AI Ascent 2024 主题活动中的演讲视频,今天正好在 DeepLearning.AI 官方也看到了相关内容,就索性翻译了一下。
我认为,今年 AI agent 的 workflows 将大大推动 AI 的进步,其影响甚至可能超过下一代基础模型的发展。这是一个不容忽视的趋势,我强烈建议所有 AI 领域的工作者都应该重视起来。
目前,我们主要是在零样本模式下使用大语言模型(LLM),即直接提示模型一步步生成最终输出,不进行任何修改。这好比让某人一气呵成地写完一篇文章,不允许回退修改,期望其能写出高质量的作品。尽管这样做颇具挑战,但大语言模型在这方面的表现出奇的好!
然而,通过采用 AI 代理的工作流程,我们可以让 LLM 多次迭代文档。例如,它可能会执行以下一系列步骤:
- 规划提纲。
- 确定是否需要进行网络搜索来收集更多信息。
- 撰写初稿。
- 复审初稿,寻找不合理的论点或无关的信息。
- 针对发现的问题修改草稿。
- 诸如此类的其他步骤。
这种迭代过程是大多数人类写作者撰写优质文本的关键。对于 AI 来说,采用这种迭代的工作流程比一次性完成整篇文章能带来更好的结果。
近期,Devin 的一次引人注目的演示在社交媒体上引发了广泛关注。我们团队一直紧密跟踪代码编写 AI 的发展。我们分析了多个研究团队的成果,重点关注算法在广泛使用的 HumanEval 编码基准上的表现。您可以在下方的图表中看到我们的发现。
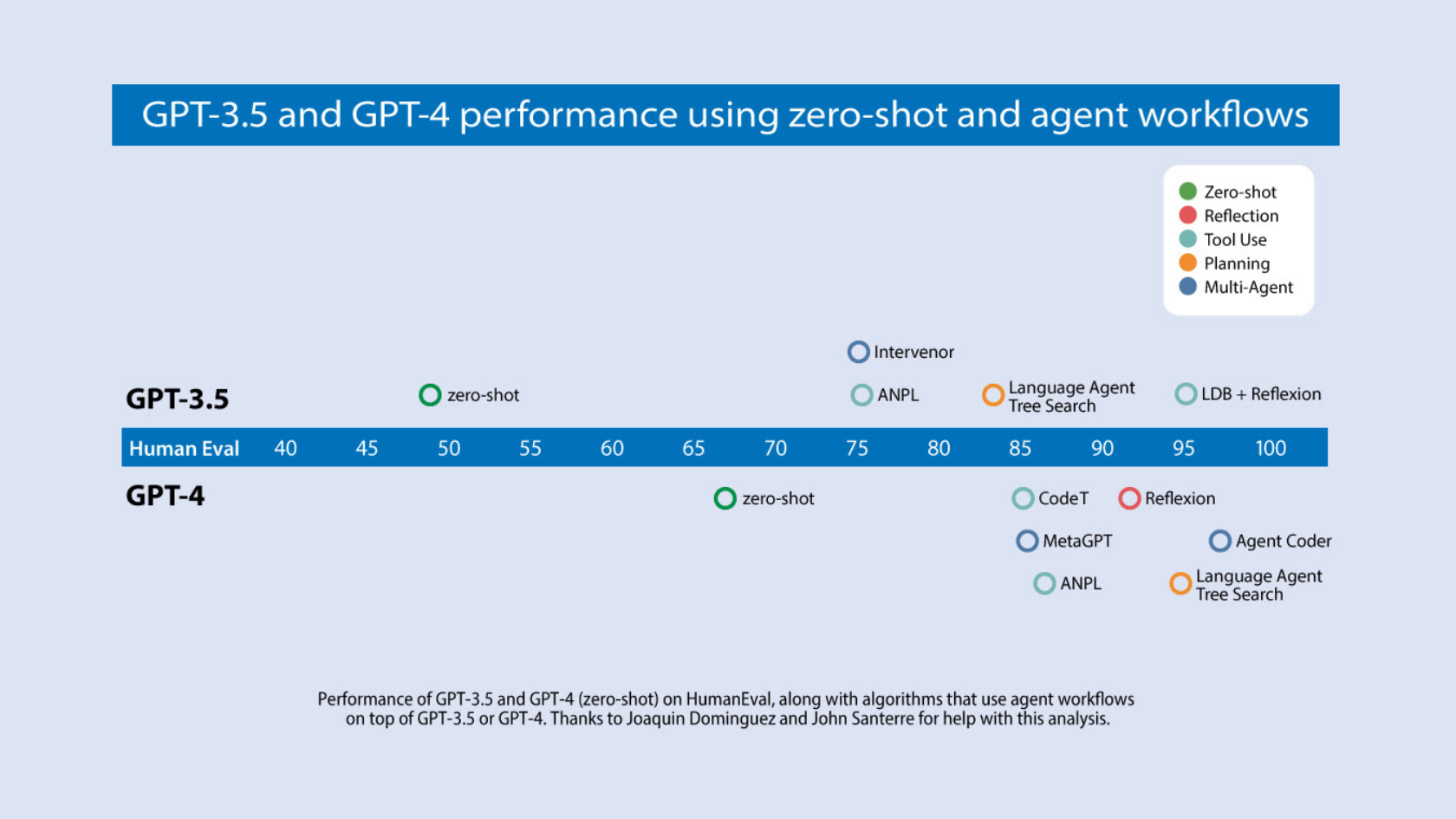
GPT-3.5 在零样本模式下的正确率为 48.1%,而 GPT-4 的表现更佳,达到了 67.0%。然而,从 GPT-3.5 到 GPT-4 的进步与采用迭代代理工作流程的提升相比则显得微不足道。实际上,在代理循环的加持下,GPT-3.5 的表现提升至高达 95.1%。
开源代理工具和代理相关的学术文献正迅速增加,这既是一个令人兴奋的时刻,也是一个令人困惑的时期。为了帮助大家更好地理解这项工作,我想分享一个框架,用于对构建代理的设计模式进行分类。我的团队 AI Fund 在许多应用中成功采用了这些模式,我希望它们对你也有帮助。
- 反思:LLM 审视自己的工作,并提出改进方案。
- 工具使用:LLM 被赋予工具,比如网络搜索、代码执行等,以帮助其收集信息、采取行动或处理数据。
- 规划:LLM 设计并执行一个多步骤计划来实现目标(比如,为一篇文章制定提纲,接着进行在线研究,然后撰写草稿等等)。
- 多代理合作:多个 AI 代理合作,分担任务,讨论和辩论观点,以提出比单一代理更好的解决方案。
反思
也许你曾这样体验过:你向 ChatGPT 、 Claude 或 Gemini 提出请求,结果不尽如人意。之后,你给出关键反馈,帮助模型优化答案,然后它给出了更好的回应。如果我们将提供关键反馈的步骤自动化,让模型能自我批评并优化输出呢?这正是“反思”模式的核心所在。
以编程任务为例,我们首先让LLM直接生成完成某个任务 X 的代码。接下来,我们引导它反思自己的输出,可能会这样询问:
这是针对任务 X 的代码:[之前生成的代码]
请仔细检查代码的正确性、风格和效率,并提出改善的建设性意见。
这样做有时能让 LLM 发现问题并提出有建设性的改进意见。接下来,我们可以将之前生成的代码及其建设性反馈作为上下文,引导 LLM 根据反馈重新编写代码,这可能会得到更好的结果。重复这一批评和重写的过程,可能会进一步提高输出质量。这种自我反思的过程让 LLM 在包括编码、写作和解答问题等多种任务上,能发现不足并进行自我优化。
我们还可以超越自我反思,给 LLM 提供工具来帮助评估其输出;例如,通过运行一些单元测试来检查代码是否能在测试用例上得到正确的结果,或者搜索网络以核实文本输出。然后,模型可以根据发现的错误进行反思,并提出改进方案。
此外,我们可以通过多代理框架实施反思。我发现创建两个不同功能的代理很有帮助,一个负责生成高质量输出,另一个负责对第一个代理的输出进行建设性的批评。这两个代理之间的互动可以导致更优的结果。
尽管反思是一种基本的代理工作流模式,但在实际应用中,我惊喜地发现它显著提升了效果。我希望你们在自己的项目中也能尝试应用它。如果你对反思这一概念感兴趣,以下是一些推荐阅读:
- 《自我精炼:自我反馈的迭代细化》, Madaan等人(2023年)
- 《反思:具有口头强化学习的语言代理》, Shinn等人(2023年)
- 《CRITIC: 大语言模型可以通过工具交互批评自我纠正》, Gou等人(2024年)
使用工具
在人工智能代理的工作流程中,让大语言模型(LLM)使用工具进行信息收集、行动执行或数据操作,已成为一种关键设计。你可能已经见识过能够进行网页搜索或执行代码的LLM系统。实际上,一些面向消费者的大型LLM系统已经集成了这些功能。但是,工具的使用远不止于此。
比如,当你向一个在线 LLM 聊天系统提问:“哪款咖啡机是评论者推荐的最佳选择?”它可能会执行网页搜索,并下载一个或多个网页来获取背景信息。开发者很早就意识到,仅仅依赖预训练的Transformer生成输出是不够的。为LLM配备网页搜索工具,可以极大地拓宽它的功能。借助这样的工具,LLM可以通过微调或者利用少量示例提示来生成特定格式的字符串,如 {tool: web-search, query: “coffee maker reviews”},来请求调用搜索引擎。(具体的字符串格式取决于实现方式。)随后,系统会搜索这类字符串,找到后调用网络搜索功能,并将结果反馈给LLM,作为进一步处理的上下文输入。
同样地,如果你问:“如果我以7%的年复合利率投资100美元,12年后能得到多少?”LLM可能不会直接尝试生成答案,因为直接计算不太可能得出正确结果。相反,它可能会使用代码执行工具来运行Python命令100 * (1+0.07)**12,以计算出准确答案。LLM可能会生成像这样的字符串:{tool: python-interpreter, code: “100 * (1+0.07)**12”}。
而如今,代理工作流中的工具使用已经发展得更加深入。开发者正在利用各种函数来搜索不同的信息源(如网络、维基百科、arXiv等),与各种生产力工具(比如发送电邮、读写日历条目等)进行交互,生成或解析图像等等。我们可以通过提供详细的功能描述来指引LLM,这可能包括函数的作用描述及其期望的参数详情。我们期待LLM能自动选择正确的函数来完成任务。
更进一步,现在有系统能让 LLM 访问数百个工具。在这种情况下,可能有太多的功能不能全部一次性纳入LLM的上下文中,因此你可能需要用到启发式方法,选取在当前处理步骤中最相关的功能子集。这种做法,如下引用的《Gorilla》论文所述,类似于在文本上下文太多时,检索增强生成(RAG)系统选择文本子集的方法。
在LLM的发展早期,比如在 LLaVa 、 GPT-4V 和 Gemini 这样的大型多模态模型普及之前,LLM 无法直接处理图像,计算机视觉社区因此做了大量工作。那时,LLM系统处理图像的唯一方法是通过调用特定功能,如进行物体识别等。自那以后,工具使用的做法迅速发展。GPT-4 去年中推出的函数调用功能,是向通用工具使用迈出的重要一步。自那以后,越来越多的LLM被开发出来,它们在工具使用方面也变得更加灵活。
如果你想深入了解工具使用,我推荐以下阅读:
- Patil等人(2023)的《Gorilla: 大语言模型与海量APIs连接》
- Yang等人(2023)的《MM-REACT: 通过提示ChatGPT进行多模态推理和行动》
- Gao等人(2024)的《通过抽象推理链高效使用工具》
工具使用和反思是我能在我的应用中可靠实现的两种设计模式——这两种能力都非常值得探索。在未来的信件中,我会介绍规划和多代理合作的设计模式。它们使 AI 代理能做更多事情,但技术还不成熟、可预测性较低——尽管非常令人兴奋。