DeepSeek 正式开源 DeepSeek-V3.1:迈向 Agent 时代的第一步!
DeepSeek-V3.1 是一个混合推理模型,一个模型支持两种模式:思考(Think)与非思考(Non-Think)。
PS:Qwen 团队发布 Qwen3-235B-A22B-Instruct-2507 时已经踩过这个坑了,可能后续 DeepSeek 团队后续也得放弃这种混合模式的方案。这种混合思考模型虽然既有 instruct 模型的快思考,也有 Thinking 模型的深度思考,但无法达到垂类模型的最佳质量,所以 Qwen 团队放弃了具有混合思考模式的 Qwen3-235B-A22B 的继续迭代。
DeepSeek-V3.1 的两大特点:
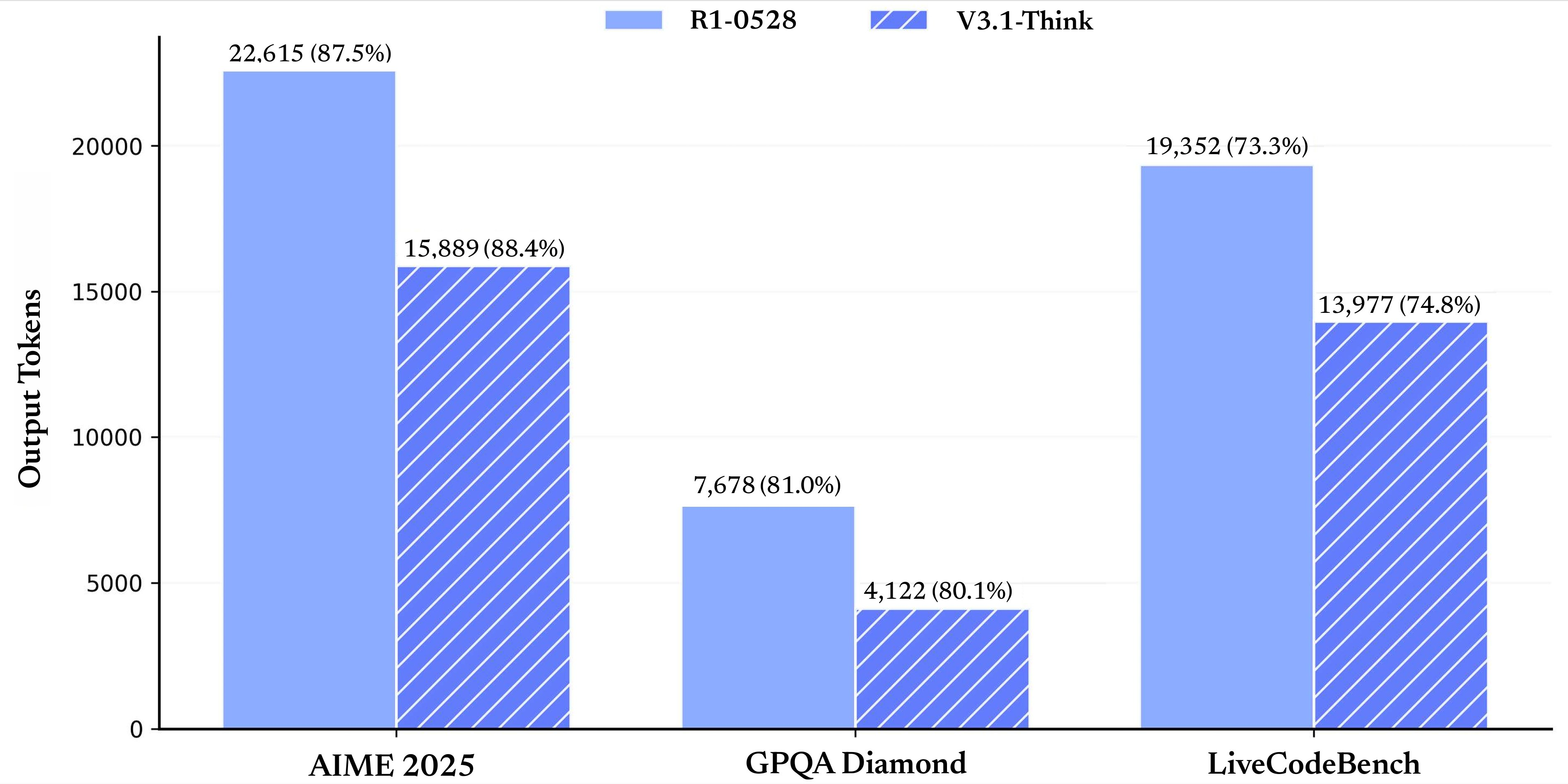
- 更快的思考速度:相较于 DeepSeek-R1-0528,DeepSeek-V3.1-Think 能在更短的时间内得出答案
- 更强的 Agent 能力:后训练(Post-training)增强了工具使用和多步 Agent 任务的能力
一些模型的细节:
- V3.1 Base:在 V3 模型基础上,额外使用 840Btokens 进行持续预训练,以扩展长文本能力
- 使用了新的分词器,新的分词器配置文件:https://huggingface.co/deepseek-ai/DeepSeek-V3.1/blob/main/tokenizer_config.json
- V3.1 Base 开源权重:https://huggingface.co/deepseek-ai/DeepSeek-V3.1-Base
- V3.1 开源权重:https://huggingface.co/deepseek-ai/DeepSeek-V3.1
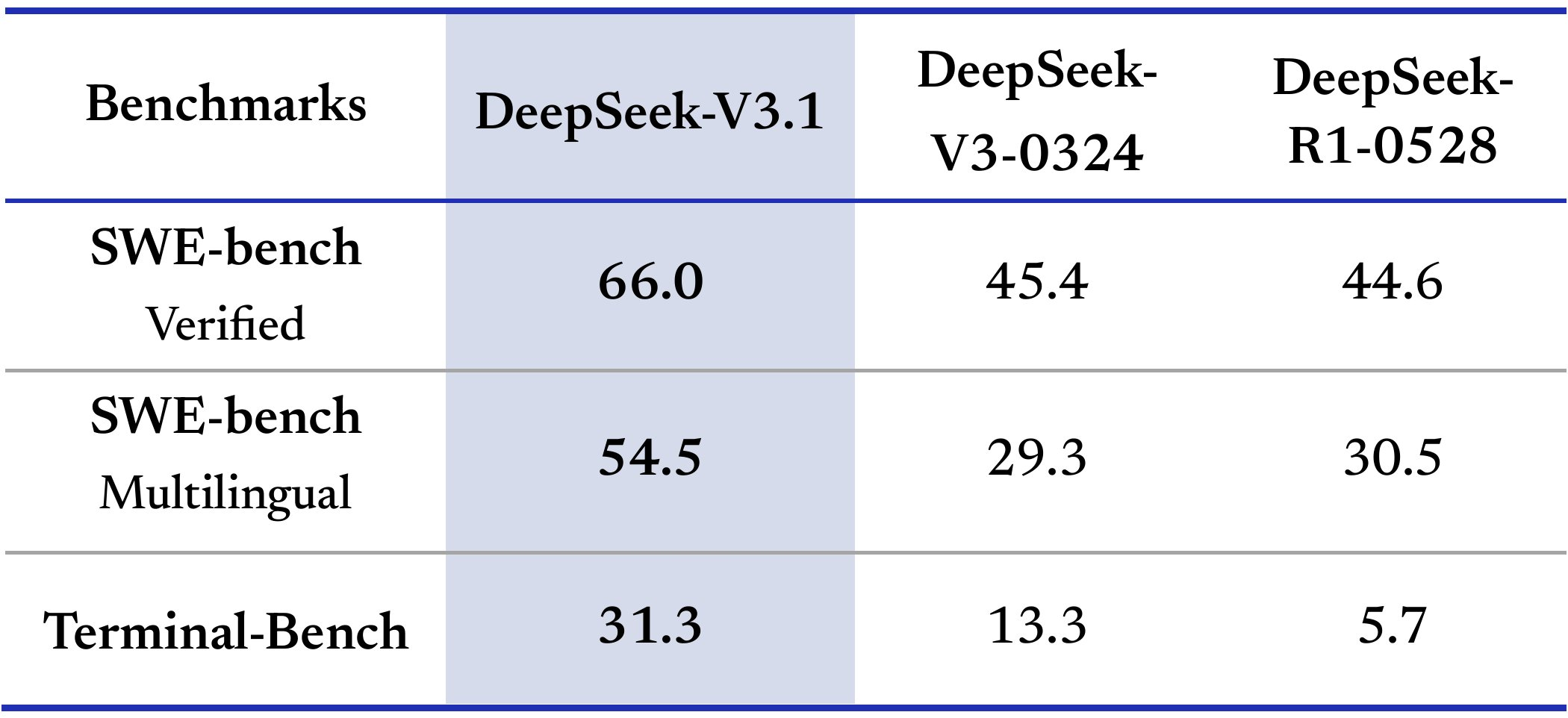
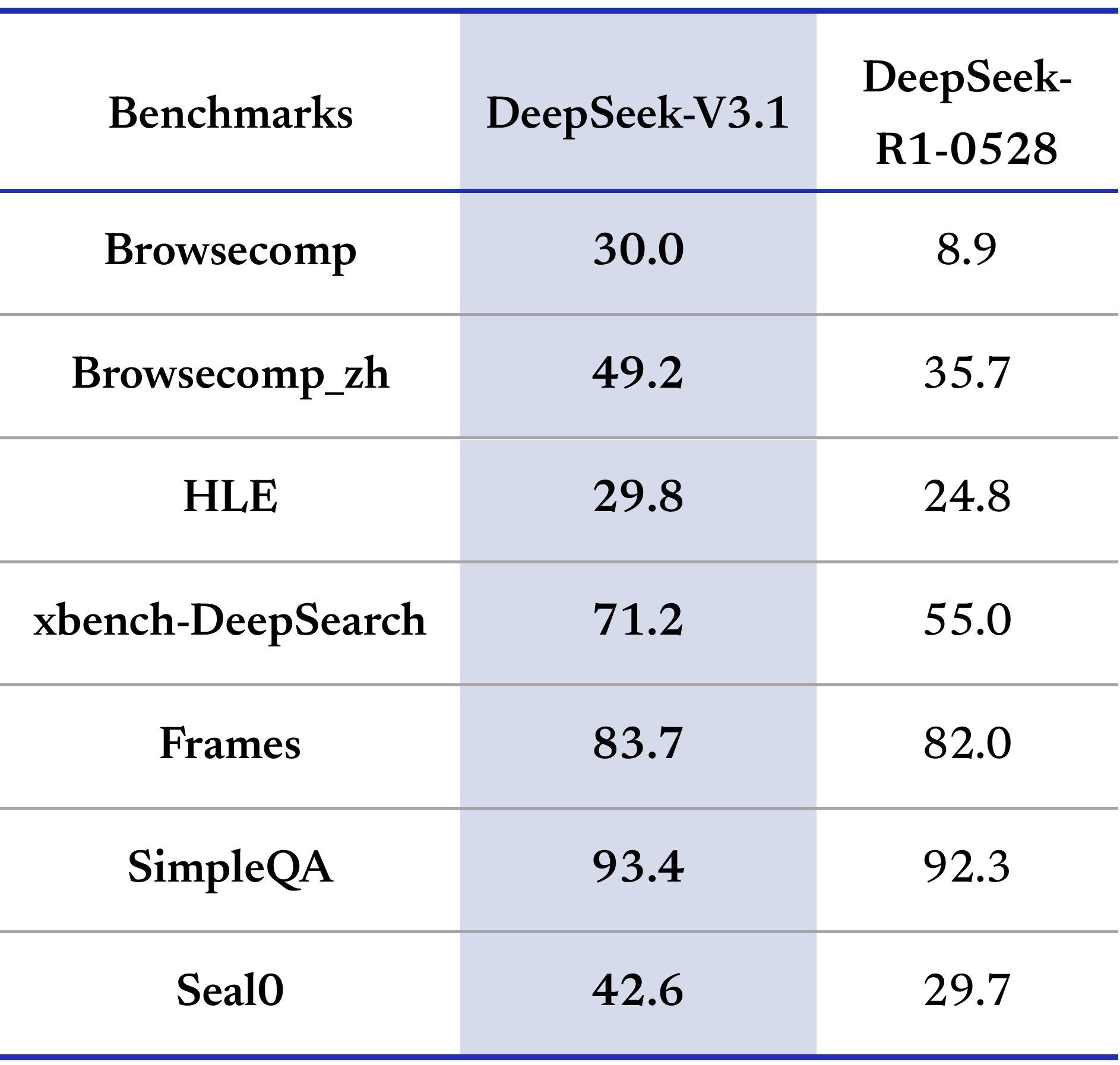
一些看法: 从 DeepSeek-V3.1 的官方指标来看,DeepSeek 在往 Agent 方向在走,此次的优化方向主要在编码能力和工具使用,对标的模型应该还是 OpenAI 和 Anthropic 的模型,比如 GPT-5 和 Claude 4。从官方指标结果上看,DeepSeek-V3.1 比 DeepSeek-V3-0324、DeepSeek R1 0528 确实有比较大的提升。
但和目前开源的 Sota 模型比还是稍微差了一些,我们来对比一下最近开源的编码 Sota 模型:一个是千问的 Qwen-Coder,一个是 Kimi 的 Kimi K2。
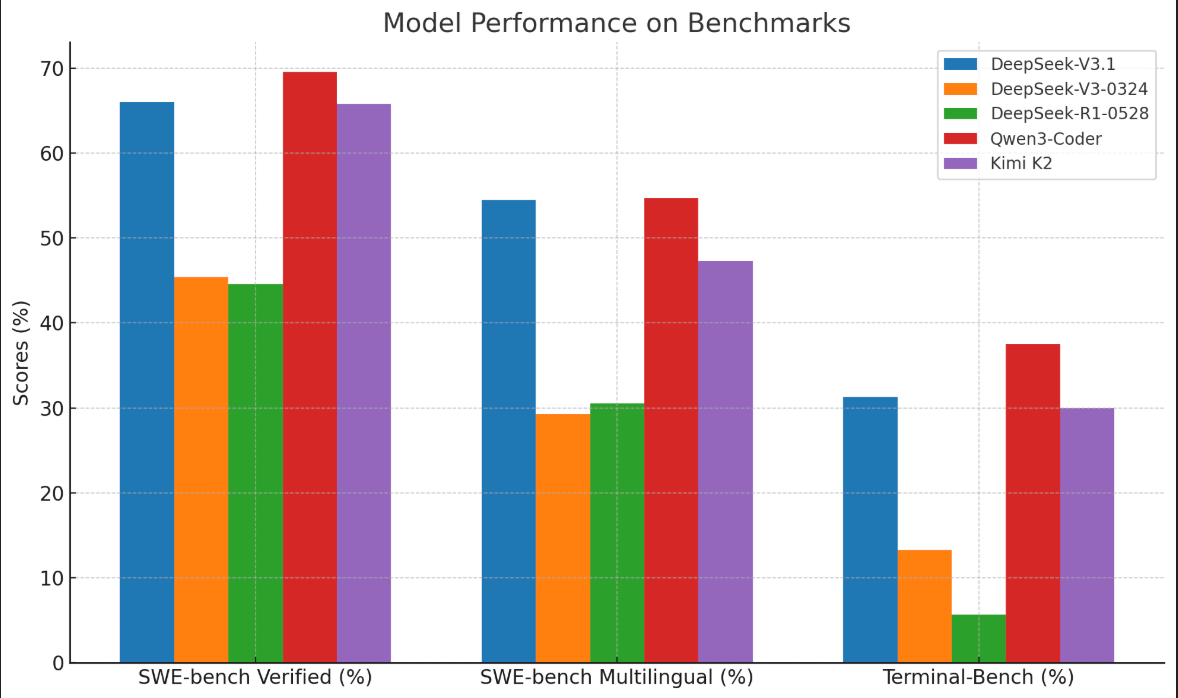
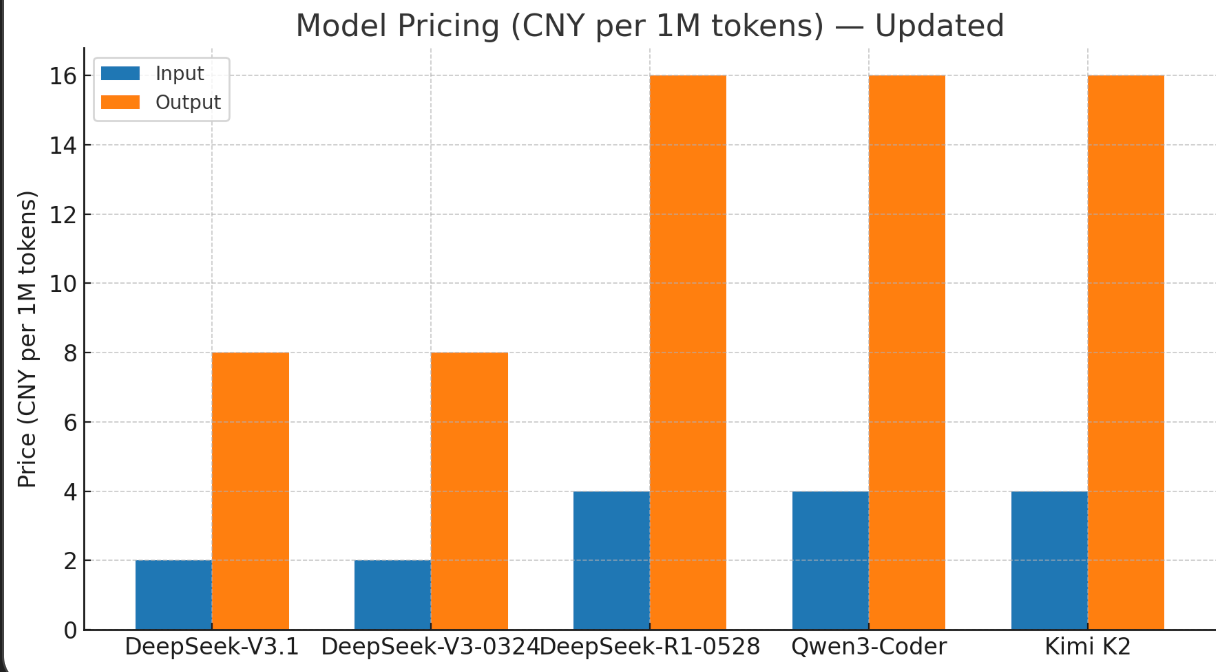
从图中可以看出来 DeepSeek-V3.1 和 万亿参数的 Kimi K2 质量相当,但弱于 Qwen-Coder。
下面我们来看一个例子,就能更加直观的看出这三个模型的差异了。具体 Prompt 为:【一只青蛙演奏萨克斯的 svg 】和【一个鹈鹕骑车的 svg 】。

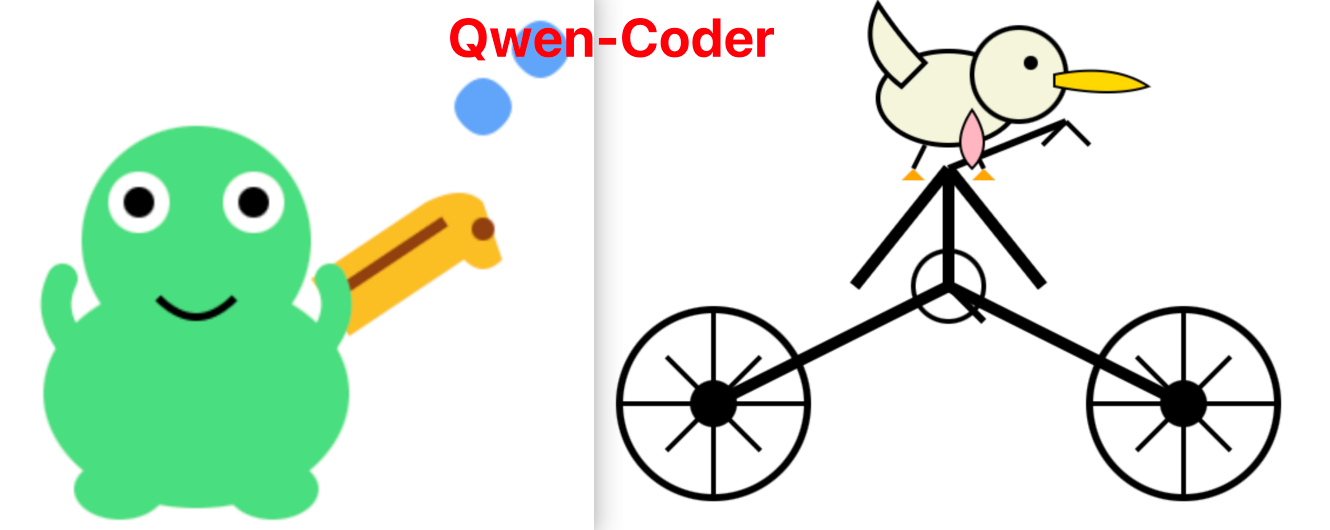

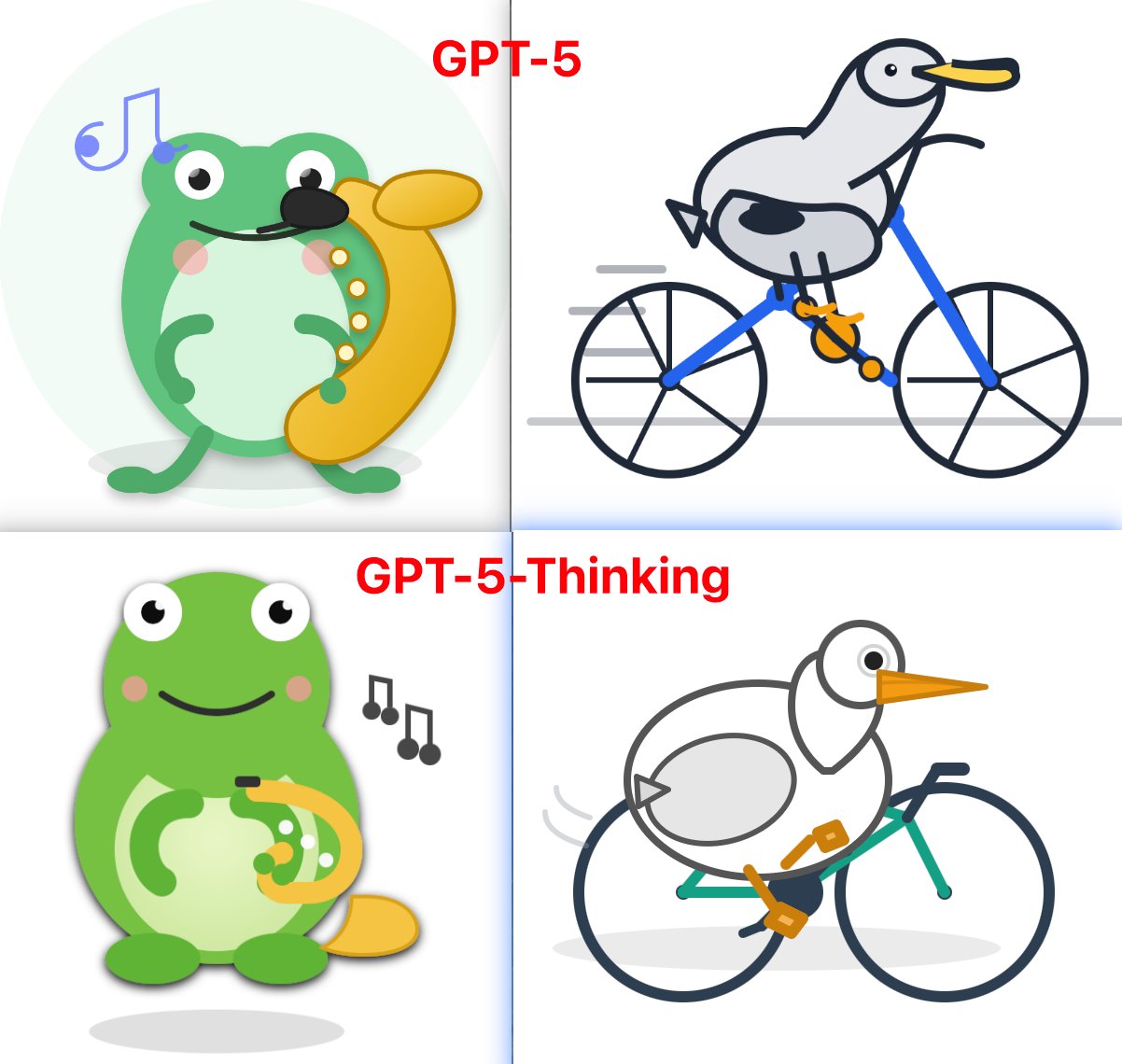
总的来看,DeepSeek 这次开源的 V3.1 模型表现一般,没有超出大家预期,期望 DeepSeek 团队继续加油,期待 R2的尽快到来,再次复刻 1月底 DeepSeek R1 时的全球爆火盛况。