智谱在 2025 年7 月 29 日开源了两个全新的旗舰大语言模型:GLM-4.5 和 GLM-4.5-Air。其核心目标是打破现有模型在特定领域(如推理、编码)表现突出但综合能力不足的局限,将卓越的推理、编码和 Agent(智能体)能力统一到单个模型中。该系列模型采用 MoE(混合专家)架构,并具备创新的混合推理模式,可根据任务复杂性在用于深度思考的 thinking mode 和用于即时响应的 non-thinking mode 之间切换。在综合性能评测中,GLM-4.5 在与业界主流模型的对比中位列第三,展现出强大的竞争力,并在性能与模型规模的权衡中实现了高效率。该模型已通过 Z.ai 平台、API 接口及开源权重等多种方式向用户开放。
核心内容
- 发布新一代旗舰模型:正式推出
GLM-4.5和GLM-4.5-Air两个新模型,旨在统一并提升模型的综合能力。 - 统一三大核心能力:致力于将推理(Reasoning)、编码(Coding)和智能体(Agentic)三大关键能力融合于单一模型,以满足日益复杂的应用需求。
- 创新的混合推理模式:模型内置
thinking mode(思考模式)和non-thinking mode(非思考模式),前者用于处理复杂任务,后者用于快速响应,实现了性能与效率的平衡。 - 卓越的综合性能:在覆盖
Agent、推理和编码三大领域的12个基准测试中,GLM-4.5综合排名第三,证明了其在行业内的领先地位。 - 先进的技术架构与训练方法:采用
MoE架构,并通过专门设计的强化学习框架slime对Agent能力进行深度优化,最终通过“专家蒸馏”技术整合各项专长。
关键细节
模型参数与性能排名
- 模型规模:
GLM-4.5拥有3550亿总参数和320亿活跃参数;GLM-4.5-Air则为1060亿总参数和120亿活跃参数。 - 综合排名:在与
OpenAI、Anthropic、Google等多家机构模型的对比中,GLM-4.5综合排名第三,GLM-4.5-Air排名第六。
Agent (智能体) 能力
- 基础能力:模型提供
128k上下文长度和原生函数调用(Function Calling)能力。 - 基准测试表现:在
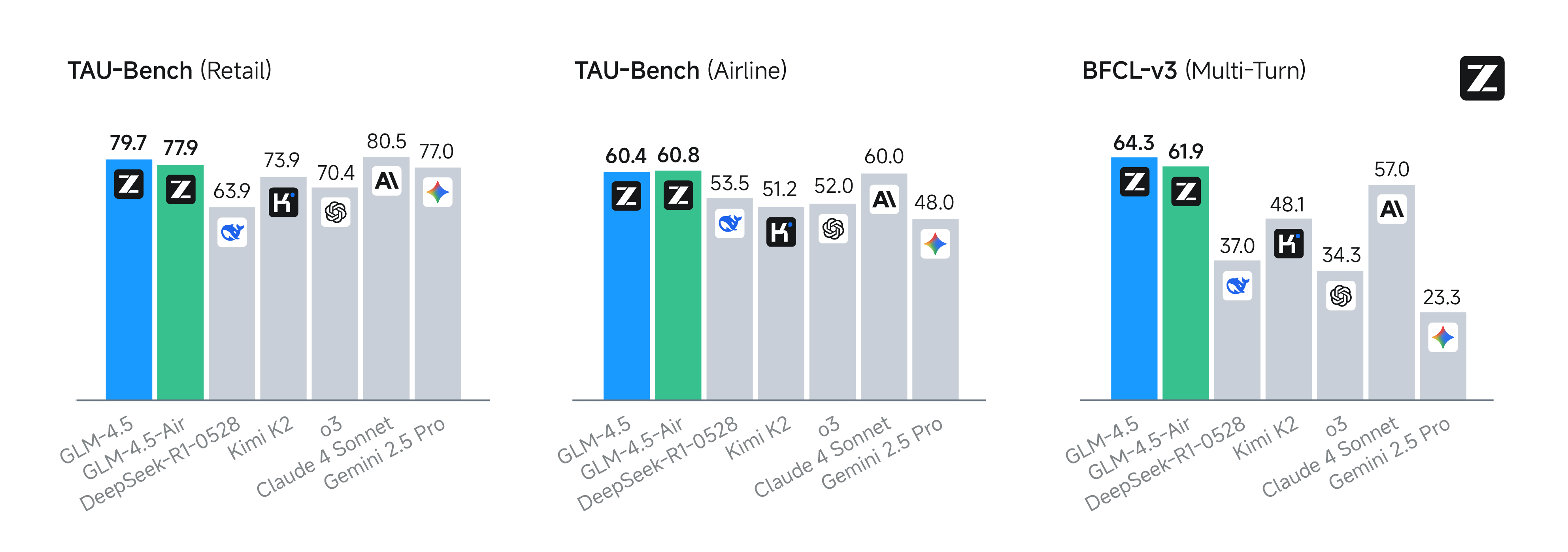
τ-bench和BFCL-v3基准上,其性能与Claude 4 Sonnet相当。在网页浏览基准BrowseComp上,其正确率达到26.4%,显著优于Claude-4-Opus(18.8%)。 - 工具调用成功率:在
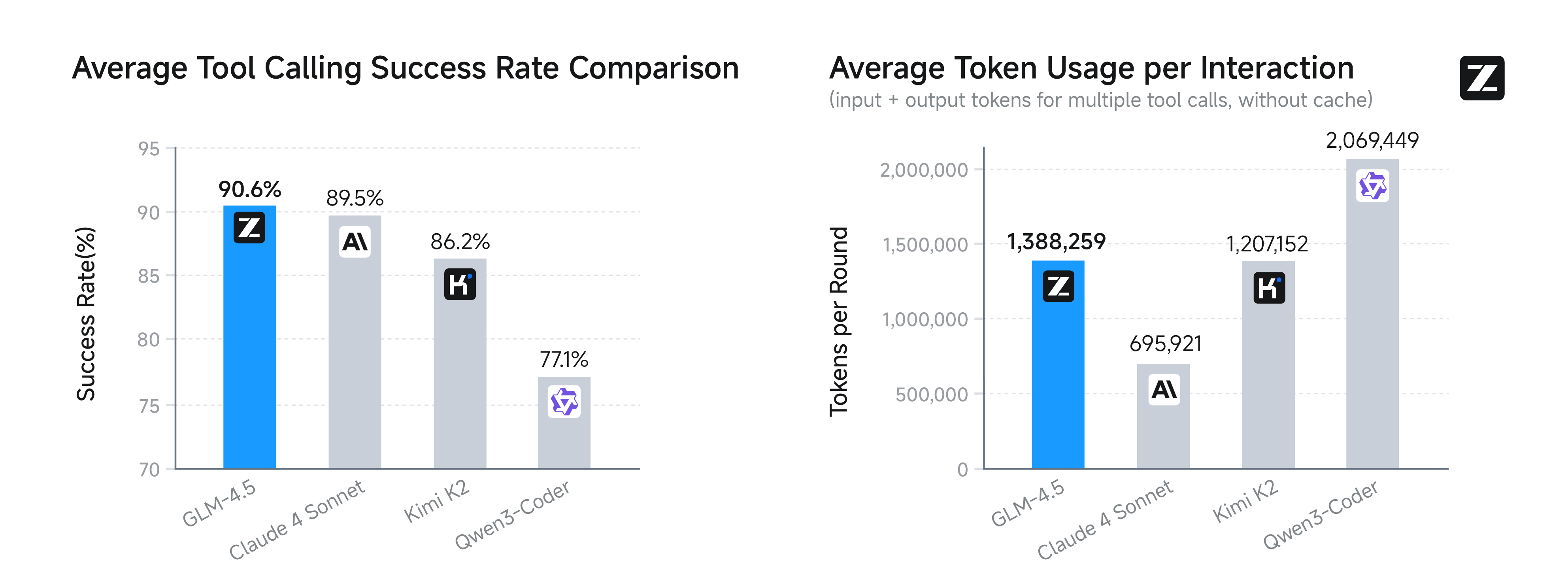
Agent编码任务中,其工具调用平均成功率高达90.6%,优于Claude-4-Sonnet(89.5%) 等竞争对手。
推理与编码能力
- 推理能力:在
thinking mode下,模型能有效解决数学、科学等复杂推理问题,在MMLU Pro、MATH 500等基准上表现优异。 - 编码能力:在
SWE-bench Verified等编码基准上表现出色,能够无缝集成Claude Code等工具。在与其它模型的对抗测试中,对Kimi K2的胜率为53.9%,对Qwen3-Coder的胜率则高达80.8%。
技术架构与训练方法
- 模型架构:采用
MoE架构,通过增加模型深度而非宽度来提升推理能力。同时使用了Grouped-Query Attention、QK-Norm等技术。 - 训练数据:预训练数据量达
15T通用语料和7T代码与推理语料。 - 强化学习框架:引入并开源了名为
slime的强化学习(RL)训练框架,该框架通过解耦设计和混合精度推理等技术,高效提升了Agent任务的训练效率。 - 训练流程:通过有监督微调和专门的强化学习阶段,针对推理和
Agent能力进行优化,最后通过expert distillation(专家蒸馏)技术融合各项技能。
应用与接入
- 应用场景:能够创建交互式迷你游戏、物理模拟等复杂代码工件(
Artifacts),并能结合Agent工具进行幻灯片(Slides)和全栈网站开发。 - 接入方式:用户可通过
Z.ai平台、Z.ai API或在HuggingFace和ModelScope上获取开源权重进行本地部署。