2025 年7 月 28 日,阿里开源了一个先进的大规模视频生成模型 Wan2.2。作为 Wan 系列的重大升级,Wan2.2 在模型架构、数据训练、生成效率和美学质量上均实现了显著突破,旨在为学术界和工业界提供顶尖的视频生成能力。
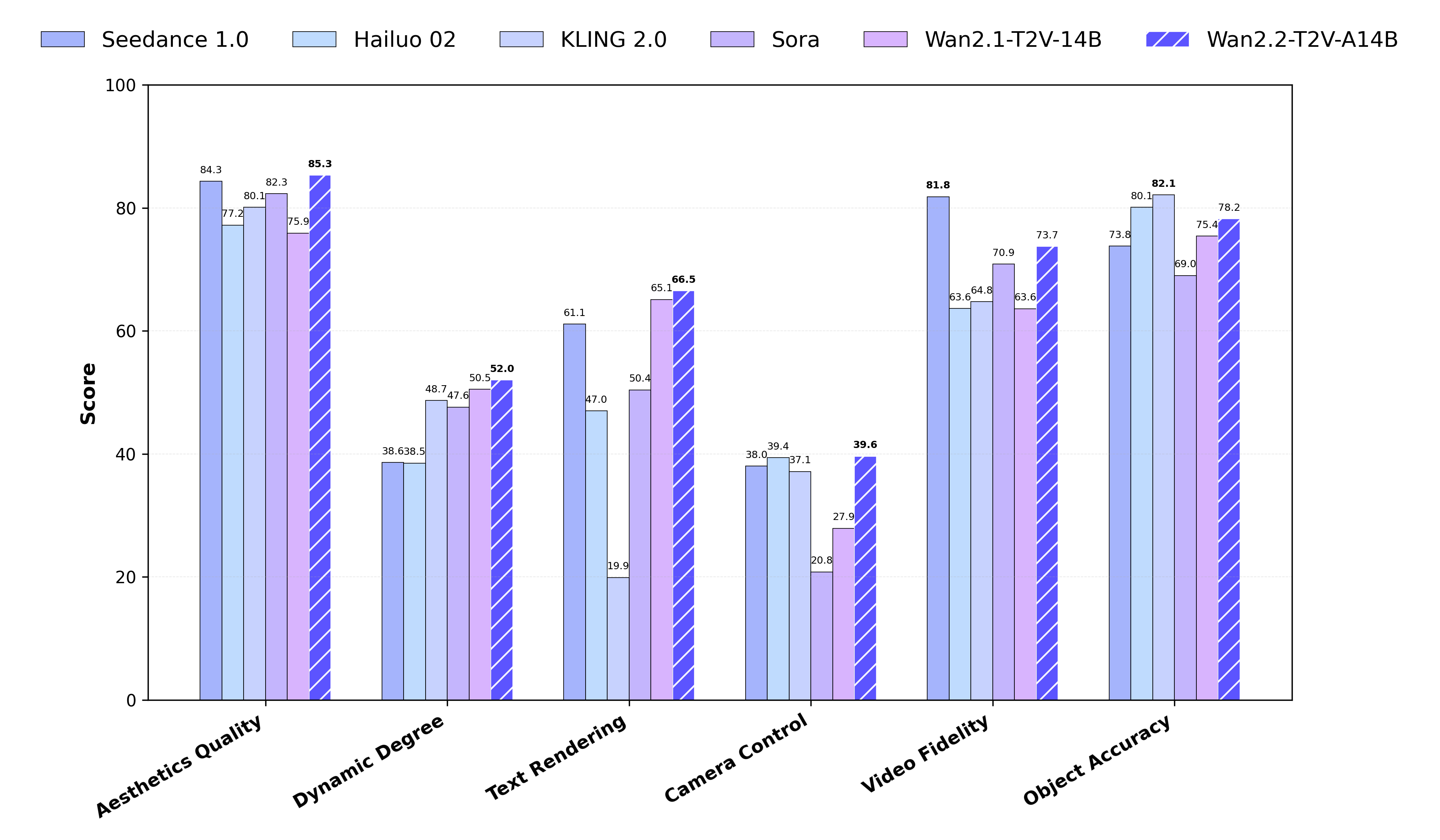
Wan2.2 是一个功能强大的开源视频生成模型,其核心创新在于引入了高效的 MoE (混合专家) 架构,显著提升了模型容量而未增加计算成本。通过使用更大规模、更精细标注的训练数据,Wan2.2 在生成视频的动作复杂度和电影级美学质感方面达到了业界领先水平。此外,它还推出了一个高效的高清混合模型 TI2V-5B,该模型能在消费级显卡 (如 RTX 4090) 上运行,支持生成 720P 分辨率的视频,并兼顾了文生视频和图生视频功能,极大地降低了高质量视频生成的门槛。
1. 架构与技术创新
MoE(混合专家) 架构:Wan2.2首次将MoE架构引入视频扩散模型。它设计了两个专家模型(高噪声专家和低噪声专家),分别处理去噪过程的不同阶段。这使得模型总参数量达到27B,但每步推理时仅激活14B参数,从而在提升模型能力的同时保持了计算效率。- 高效高清混合
TI2V模型:Wan2.2开源了一个5B参数的紧凑模型TI2V-5B。该模型采用全新的Wan2.2-VAE,实现了4×16×16的高压缩率,支持在24GB显存的消费级显卡上生成720P、24fps的高清视频,是目前速度最快的同类模型之一。 - 统一框架:
TI2V-5B模型在统一的框架内原生支持文生视频 (Text-to-Video) 和图生视频 (Image-to-Video) 两种任务。
2. 性能与质量提升
- 电影级美学: 模型使用了经过精心策划和详细标注(如光照、构图、色调等)的美学数据进行训练,使得生成的视频具有可控的电影级风格。
- 复杂动作生成: 与
Wan2.1相比,Wan2.2的训练数据量大幅增加(图像+65.6%,视频+83.2%),显著增强了模型在动作、语义和美学等多个维度的泛化能力,在Wan-Bench 2.0评测中表现优于顶尖的闭源商业模型。 - 提示词扩展: 支持使用
Dashscope API或本地模型 (如Qwen) 对用户输入的提示词进行扩展,以生成更丰富、更高质量的视频内容。
3. 开源模型与可用性
- 模型发布: 本次开源了三个核心模型:
T2V-A14B: 用于文生视频的MoE模型。I2V-A14B: 用于图生视频的MoE模型。TI2V-5B: 高效的混合模型,支持文生视频和图生视频。
- 生态集成: 所有模型权重和推理代码均已在
GitHub、Hugging Face和ModelScope上发布,并已集成到ComfyUI和Diffusers等主流工具中,方便社区用户使用和二次开发。 - 硬件要求:
A14B模型在单GPU上需要约80GB显存,而TI2V-5B模型在RTX 4090(24GB显存) 等消费级显卡上即可运行。