近年来,大型语言模型(Large Language Models,LLMs)以前所未有的速度发展,深刻地改变了人工智能的格局,并日益融入我们日常生活的方方面面。从智能助手到内容创作和代码生成,大语言模型展现出强大的能力。这些模型已经从科研实验室走向实际应用,成为各种技术产品中不可或缺的组成部分,其重要性和影响力正持续扩大。
当我们谈论大语言模型时,“大”这个字不仅仅指它们所学习的海量数据,更在于其内部庞大的变量,我们称之为“参数”。正是这些数量巨大的参数,赋予了模型理解和生成人类语言的能力。例如,DeepSeek 的模型拥有高达 6710 亿个参数,Qwen 的模型参数量也达到了 140 亿,而一些较小的模型则拥有约 5 亿个参数。这些数字上的巨大差异暗示着参数规模对模型的能力和资源需求有着显著的影响。
什么是“参数”?
要理解大语言模型中的“参数”,首先需要了解它们所基于的底层技术:深度学习和人工神经网络。人工神经网络是一种受人脑结构和功能启发的计算系统。人脑由数以亿计的神经元相互连接构成,而人工神经网络则是由大量相互连接的计算单元(通常称为节点或神经元)组成,这些节点被组织成多个层次,包括输入层、隐藏层和输出层。
在大语言模型的语境下,“参数”指的是神经网络内部的变量,这些变量在模型的训练过程中被调整,以学习数据中的关系。这些参数主要包括以下两种类型:
- 权重 (Weights): 权重是分配给不同层级节点之间连接的数值,它们表示该连接在影响模型输出时的强度或重要性。权重的大小决定了前一层神经元的输出对下一层神经元的影响程度,通过调整这些权重,模型能够学习到训练数据中的复杂模式。
- 偏置 (Biases): 偏置是添加到神经元加权输入总和中的常数值。偏置允许激活函数在输入为零时也能被激活,为模型的学习提供了额外的自由度,使其能够学习更复杂的函数关系。
模型的训练过程本质上是一个不断调整这些参数的过程。通过分析大量的训练数据,模型会逐步调整其内部的权重和偏置,以最小化预测结果与真实结果之间的差异 . 想象一下,这些参数就像一个复杂机器上的无数个微调旋钮 。通过对这些旋钮进行精确的调整,机器(模型)才能更好地完成其任务。参数的值在训练结束后就被固定下来,它们实际上编码了模型从数据中学到的“知识” 。因此,参数的数量越多,模型能够学习和存储的语言模式和复杂关系就越丰富。
这里借用一下 OpenAI 前创始人、特斯拉前 AI 总监 Andrej Karpathy 大模型科普视频中的一个例子:Meta 开源的 Lama2 70B模型,可以被精简地理解为电脑文件系统目录中的两个核心文件:一个参数文件以及一个运行代码文件。
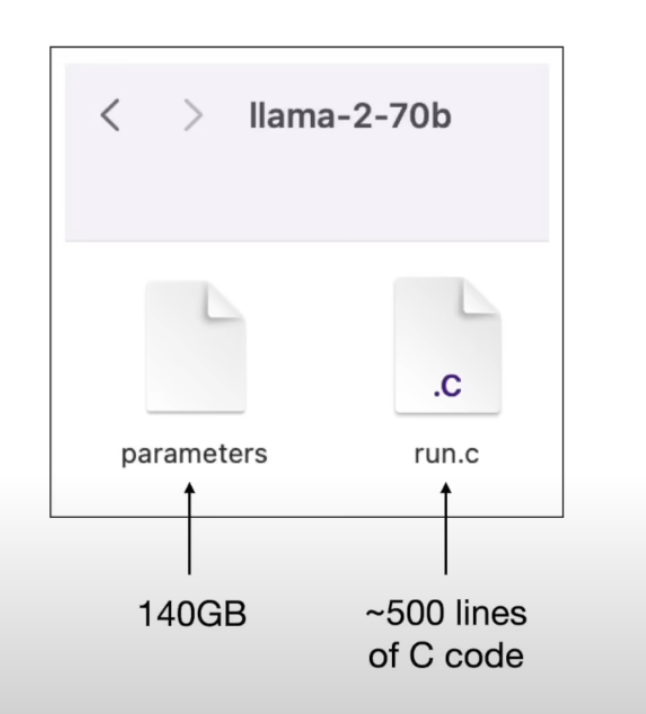
在这个模型中,每个参数都采用16位浮点数(即2个字节)来存储,累计起来,这个参数文件的体积达到了140 GB。这一数字不仅反映了模型的复杂性,也预示着其强大的处理能力。
接下来是运行代码文件,这部分可能令人意外地简洁,大约 500 行的 C 语言代码便足以实现整个神经网络的结构。然后我们将代码文件进行编译,并链接上参数文件,那么就形成了一个完整的 Llama2 70B 大模型。
规模的重要性:理解模型大小中的“B”
当我们谈论像 Qwen-14B 或 DeepSeek-671B 这样的大型语言模型时,其中的“B”代表的是“Billions”,即十亿 。这个字母清晰地表明,这些模型的参数数量级已经达到了非常惊人的程度。例如,谷歌发布的 Gemma 模型拥有 70 亿参数,这个数量几乎等同于全球人口。通常来说,模型拥有的参数越多,其学习复杂模式的能力就越强,从而能够更好地理解和生成更复杂的文本,并在各种语言任务中表现出更高的性能 。
值得注意的是,随着模型参数数量的增加,有时会出现所谓的“涌现能力” 。这意味着当模型的规模超过某个阈值时,它可能会突然展现出一些在较小模型中从未出现过的能力,例如进行更高级的推理、理解更抽象的概念,甚至执行一些它在训练过程中没有被明确指示要完成的任务。然而,模型规模的扩大也带来了挑战,例如训练和运行这些模型需要巨大的计算资源,并且需要更多的数据来有效地训练,以避免过拟合 。过拟合指的是模型在训练数据上表现非常好,但在面对新的、未见过的数据时性能却显著下降。
DeepSeek 的 671B 参数
DeepSeek-V3 是由中国人工智能初创公司 DeepSeek 开发的先进大语言模型,其参数量高达 6710 亿。如此庞大的规模使得 DeepSeek-V3 在数学、编码和复杂推理等具有挑战性的任务上,能够达到与 OpenAI 的 GPT-4 和 Anthropic 的 Claude 3 等领先的专有模型相媲美的性能。
DeepSeek-V3 采用了混合专家模型(Mixture of Experts,MoE)架构。在这种架构中,虽然模型的总参数量是 6710 亿,但在推理过程中,对于任何给定的输入 token,只有一小部分参数(约 370 亿)会被激活 16。这种技术在不牺牲性能的前提下提高了模型的效率。
训练如此庞大的模型需要巨大的计算资源,正如 DeepSeek 使用数千个高端 GPU 进行了长时间的训练所证明的那样。这体现了训练具有数千亿参数模型的巨大成本和技术挑战。
Qwen 的 14B 参数
Qwen 是阿里巴巴集团开发的一系列大型语言模型,其中 Qwen-14B 包含约 140 亿个参数。Qwen-14B 代表了一个在性能和资源需求之间取得良好平衡的模型。
Qwen 系列包括不同参数规模的模型(从 0.5B 到超过 100B),这展示了该模型家族的灵活性和可扩展性,能够满足不同的需求和计算资源限制。
小模型的 0.5B 参数
参数量在 5 亿左右的小型语言模型,例如 Qwen2-0.5B 和 MobiLlama,也具有重要的意义。尽管与拥有数百亿甚至数千亿参数的模型相比,这些模型的规模相对较小,但它们仍然可以在各种自然语言处理任务中有效地执行,并在能力和计算效率之间取得平衡。这使得它们非常适合在资源受限的环境或设备上运行。
虽然小型模型在处理高度复杂的任务时可能无法与大型模型相媲美,但它们更容易针对特定应用进行微调,并且通常需要更少的内存和处理能力,从而降低了使用先进语言处理技术的门槛。然而,与更大、更通用的模型相比,使用小型模型可能需要更精细的提示工程和对模型局限性的更深入理解。
主要大语言模型及其参数对比
为了更清晰地展示不同大语言模型的参数规模,下表列出了一些在研究中提及的著名模型的近似参数数量。
| 模型名称 | 估计参数量 |
|---|---|
| GPT-4 | ~1.8 万亿 |
| Claude 3 Opus | 1370 亿 |
| DeepSeek-V3 | 6710 亿 |
| Qwen2.5-14B | 147 亿 |
| Qwen2-0.5B | 5 亿 |
| Llama 2 (例如,7B) | (多种尺寸) |
参数规模与模型性能的关系
通常来说,大语言模型的规模(由参数数量衡量)与其在各种语言任务上的性能之间存在正相关关系。参数更多的模型通常表现出更高的准确性、对语言细微差别的更好理解,以及处理更复杂指令和推理任务的能力。这是因为更大的模型拥有更强的容量来学习训练数据中更复杂的模式和依赖关系,从而在更广泛的任务中实现更好的泛化和性能。
一个有趣的现象是“涌现能力 (Emergent Abilities)”,即拥有非常庞大参数量的大语言模型突然展现出在较小模型中不明显的强大能力,例如高级推理或复杂问题解决。这些涌现能力暗示着,当参数数量达到一定阈值时,模型对语言的理解和处理会发生质的飞跃。
然而,也存在“收益递减 (Diminishing Returns)” 的规律,这就是说 Scaling law (更大的数据规模、更多的参数量、更多的计算资源)不再那么有效了。当参数数量超过某个点后,继续增加参数所带来的性能提升开始逐渐减缓。这表明,无限地扩大模型规模可能并非在所有方面都能带来显著的性能提升,其他因素(如训练数据质量和模型架构)的重要性日益凸显。比如去年 9 月 OpenAI 推出的 o1 模型、DeepSeek 今年 1 月份开源的 R1 模型 等为大模型的能力提升提供了一个新的发展方向。
此外,非常大的模型也可能存在一些缺点,例如更容易“过拟合 (Overfitting)” 训练数据。过拟合指的是模型记住了训练数据中的特定示例,而不是学习到可泛化的模式,导致在面对新的、未见过的数据时表现不佳。因此,诸如正则化和仔细的验证等技术对于减轻大型语言模型中的过拟合风险至关重要。
值得注意的是,对于特定的、定义明确的任务,经过相关数据微调的小型语言模型有时可以达到与大型通用模型相当甚至更好的性能。所以,大家在选择合适的模型规模时,应考虑具体的应用场景和任务。
参数、训练数据与计算资源
大语言模型中的参数数量、所需的训练数据量和质量,以及训练和推理所需的计算资源是紧密相关的。一般来说,参数越多,模型需要学习的模式就越复杂,因此需要更大、更多样化的数据集才能有效地学习并避免过拟合。这自然需要大量的计算能力和时间来进行训练。
为了降低大型语言模型的计算需求和内存占用,同时又不显著损失性能,研究人员开发了多种技术,包括:
- 量化 (Quantization): 降低模型权重和激活的精度。
- 剪枝 (Pruning): 从网络中移除不太重要的连接(权重)。
- 知识蒸馏 (Knowledge Distillation): 训练一个较小的“学生”模型来模仿较大的“教师”模型的行为。
- 参数共享 (Parameter Sharing): 在模型的多个部分使用相同的权重。
这些优化技术对于使大型语言模型更适用于资源有限的实际应用部署至关重要。
最后
“参数”是大语言模型核心的、可调整的内部变量,它们存在于驱动这些模型的神经网络中。参数规模在决定 LLM 学习、理解和生成人类语言的能力方面起着至关重要的作用。一般来说,更多的参数通常意味着在更广泛的任务上具有更好的性能。然而,参数数量并非衡量模型整体质量和有效性的唯一标准。训练数据的质量和数量、底层的模型架构以及微调过程同样至关重要。