Qwen团队开源 Qwen3 系列模型的最新更新版本 Qwen3-235B-A22B-Instruct-2507。这是一个在非思考模式(non-thinking mode)下运行的大型语言模型,相较于前一版本,在多个核心能力上均有显著提升。
Qwen 团队放弃了具有混合思考模式的 Qwen3-235B-A22B 的继续迭代,官方也给出了原文是“我们将分别训练 Instruct 和 Thinking 模型,以获得最佳质量”。意思就是混合思考模型虽然可以既有instruct 模型的快思考,也有 Thinking 模型的深度思考,但无法达到垂类模型的最佳质量。
Qwen3-235B-A22B-Instruct-2507 模型的核心升级在于全面提升了其综合能力和用户对齐度。主要体现在以下几个方面:
- 通用能力增强:在指令遵循、逻辑推理、文本理解、数学、科学、代码生成和工具使用等基础能力上取得了显著进步。
- 知识覆盖更广:大幅提升了在多种语言下的长尾知识覆盖范围。
- 用户对齐更优:在主观性和开放式任务中能更好地符合用户偏好,生成更有帮助和更高质量的文本。
- 长上下文能力提升:增强了对
256K超长上下文的理解能力。
模型规格
- 模型架构:该模型是一个拥有
235B总参数和22B激活参数的因果语言模型(Causal Language Model),采用了专家混合(MoE)架构,包含128个专家,每次激活8个。 - 模型层数:共
94层。 - 上下文长度:原生支持
262,144(256K) tokens 的超长上下文。 - 运行模式:此模型仅支持非思考模式,输出中不会生成
<think></think>标签。
性能表现
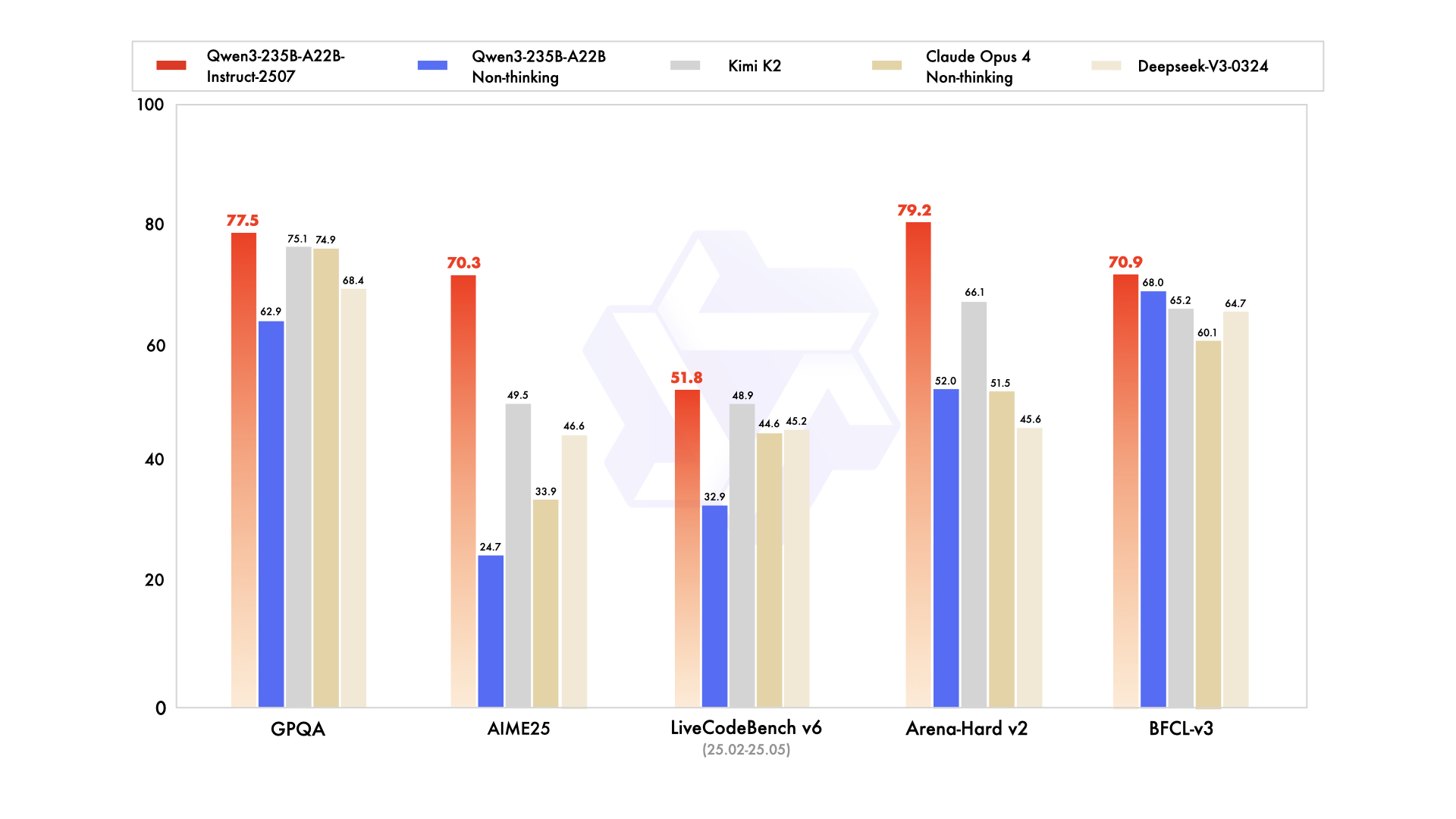
- 基准测试:在多个行业标准基准测试中,
Qwen3-235B-A22B-Instruct-2507的表现优于其前代模型,并在多个领域与GPT-4o、Claude Opus等顶级模型相当或更优。 - 突出领域:在推理能力测试(如
AIME25得分70.3,ZebraLogic得分95.0)和部分知识问答测试(如CSimpleQA得分84.3)中表现尤为出色,显著超越了竞争对手。
使用与部署
- 快速上手:可通过最新版的
Hugging Face transformers库轻松调用模型。 - 服务部署:推荐使用
sglang或vllm等框架进行服务化部署,以获得最佳性能。 - 本地运行:支持
Ollama、LMStudio、llama.cpp等多种本地化应用。
智能体(Agent)应用
- 工具调用:该模型在工具调用方面能力出众。官方推荐使用
Qwen-Agent框架来简化开发,充分利用其作为智能体的潜力。
最佳实践
- 采样参数:为获得最佳生成效果,建议设置
Temperature=0.7,TopP=0.8。 - 输出长度:建议为大多数查询设置
16,384tokens 的输出长度。 - 提示词技巧:在处理数学问题时,建议在提示中加入“请逐步推理,并将最终答案放在
\boxed{}中”以获得结构化的解题步骤。