本文档介绍了 Qwen 团队最新发布的语言模型 Qwen3-235B-A22B-Thinking-2507。该模型是 Qwen3-235B-A22B 的增强版本,在思维和推理能力上进行了深度优化,旨在处理高度复杂的任务。
Qwen3-235B-A22B-Thinking-2507 是一款在推理能力上取得显著突破的开源模型。其核心优势在于:
- 顶尖的推理性能:在逻辑、数学、科学和编程等需要深度思考的领域,该模型表现出色,在多个基准测试中达到了开源思维模型的顶尖水平。
- 全面的通用能力:除了推理能力,模型在指令遵循、工具使用、文本生成和与人类偏好对齐等方面也得到了显著提升。
- 增强的长上下文处理:模型支持
256K的长上下文窗口,能更好地理解和处理长篇文档。 - 专为复杂任务设计:官方强烈推荐在高度复杂的推理任务中使用此版本,因为它具有更长的“思考长度” (thinking length)。
模型规格
- 模型类型:因果语言模型 (Causal Language Models),仅支持思维模式 (thinking mode)。
- 参数规模:总参数量为
235B(2350亿),激活参数量为22B(220亿)。 - 模型架构:采用
MoE(Mixture of Experts) 架构,包含94个层和128个专家,每次激活8个。 - 上下文长度:原生支持
262,144(即256K) tokens 的上下文长度。
性能表现
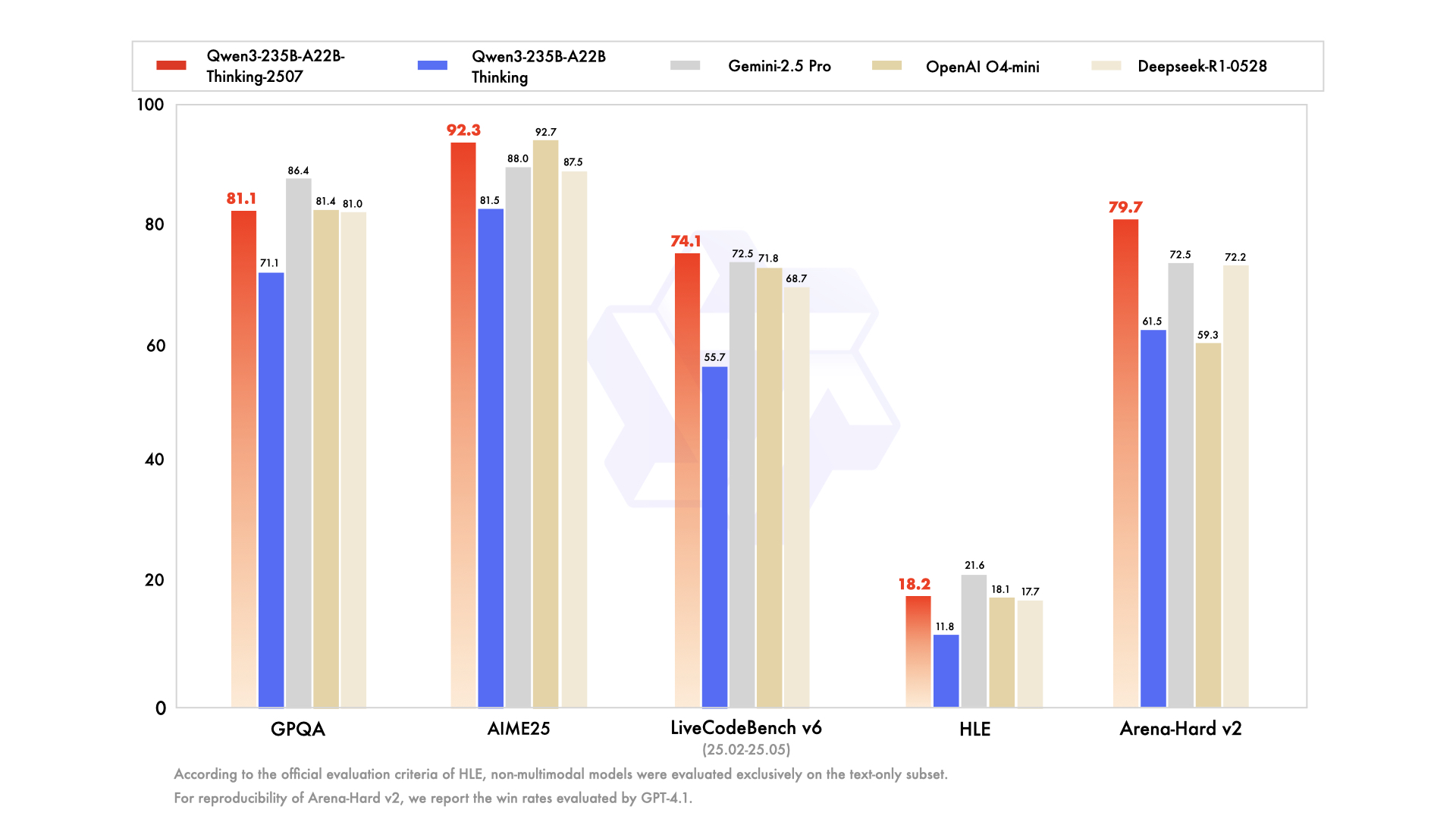
该模型在一系列权威基准测试中与其他顶尖模型(如 OpenAI O4-mini, Gemini-2.5 Pro 等)进行了对比,并在多个方面展现了卓越性能:
- 推理能力:在数学竞赛基准
AIME25(得分92.3) 和HMMT25(得分83.9) 上表现突出。 - 编程能力:在
LiveCodeBench(得分74.1) 和CFEval(得分2134) 等编程基准测试中取得了领先成绩。 - 知识与对齐:在
SuperGPQA(得分64.9) 和WritingBench(得分88.3) 等测试中也表现优异。
使用与部署
- 快速上手:推荐使用最新版的
Hugging Face transformers库 (>=4.51.0) 进行调用。代码示例展示了如何加载模型、生成文本以及解析模型输出中的“思考内容”。 - 部署框架:支持使用
sglang(>=0.4.6.post1) 或vllm(>=0.8.5) 进行服务化部署。 - 本地运行:
Ollama,LMStudio,llama.cpp等本地应用也已支持该模型。 - Agent 能力:推荐使用
Qwen-Agent框架来充分利用其强大的工具调用能力。
最佳实践
为了获得最佳性能,官方给出了以下建议:
- 采样参数:建议设置
Temperature=0.6,TopP=0.95。 - 输出长度:对于多数查询,建议输出长度为
32,768tokens;对于数学、编程等高复杂度任务,建议设置为81,920tokens,以给予模型充分的思考空间。 - 输出格式标准化:在进行数学题或选择题测试时,通过在提示中加入特定要求(如
\boxed{}或JSON格式)来规范输出。 - 多轮对话:在多轮对话中,历史记录应只包含模型的最终回答,而不应包含其“思考内容”。
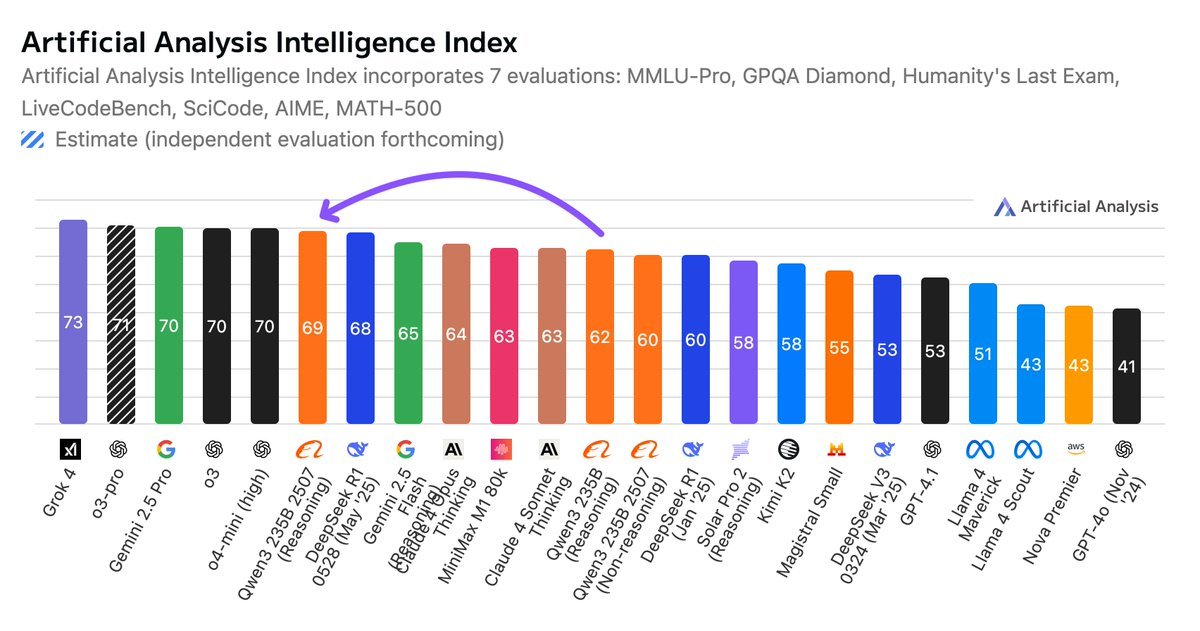
Artificial Analysis 对此模型的评价
Qwen3 235B Thinking 2507 现已成为开源模型的 SOTA,在 Artificial Analysis 智能指数上击败了 DeepSeek R1 0528!仅比 Gemini 2.5 Pro、o3 和 o4-mini (高) 落后 1 分。
全球排名前三的开源权重模型(Qwen3 235B 2507 (推理版)、DeepSeek R1 0528、Minimax M1 80K)均来自中国。
最初发布的所有 Qwen3 模型都是混合推理模型,可以切换到回答前先“思考”的模式——而 Qwen3 235B 2507 (推理版)不再是混合模型。
Qwen3 235B 2507 (推理版) 在运行 Artificial Analysis 智能基准测试时使用了 1.1 亿个 Token,比最初发布的 Qwen3 235B (推理版) 使用的 7400 万个 Token 多出约 50%。其 Token 使用量与 Grok4 相当,并高于 DeepSeek R1 0528 (9900万)、Gemini 2.5 Pro (9700万)、o4-mini (高) (7200万) 和 o3 (4500万)。
模型关键细节:
- 上下文窗口:256K (2025年5月发布的版本最高支持131K)
- 总参数量:235B (以原生 BF16 精度运行至少需要约 500GB 内存,可在 8xH100 节点上运行,或在 8xH200 节点上更流畅运行)
- 激活参数量:22B
- 原生 BF16 训练,阿里巴巴同时提供 FP8 变体
- 仅支持文本 - 无多模态输入或输出
- Apache 2.0 许可证