Qwen 团队在 2025 年7 月 30 号开源了的最新语言模型 Qwen3-30B-A3B-Thinking-2507。该模型在 Qwen3-30B-A3B 的基础上,进一步提升了深度推理和思考能力,专为处理高度复杂的任务而设计。
Qwen3-30B-A3B-Thinking-2507 是一款经过深度优化的语言模型,其核心优势在于卓越的推理能力。该模型在过去三个月中持续迭代,显著增强了在逻辑、数学、科学、编码等需要专业知识的领域的表现。同时,它在指令遵循、工具使用、文本生成等通用能力以及对 256K 长上下文的理解能力方面也得到了显著提升。因此,官方强烈推荐在处理高复杂度推理任务时使用此版本。
模型规格与特性
- 模型类型: 因果语言模型 (Causal Language Model),采用
MoE(Mixture-of-Experts) 架构。 - 参数规模: 总参数量为
30.5B,激活参数量为3.3B。 - 架构信息: 模型包含
48个层,128个专家,每次前向传播激活8个专家。 - 上下文长度: 原生支持高达
262,144(256K) tokens 的上下文窗口。 - 核心模式: 模型仅支持 “thinking mode”,该模式默认启用,会自动在输出中包含思考过程。
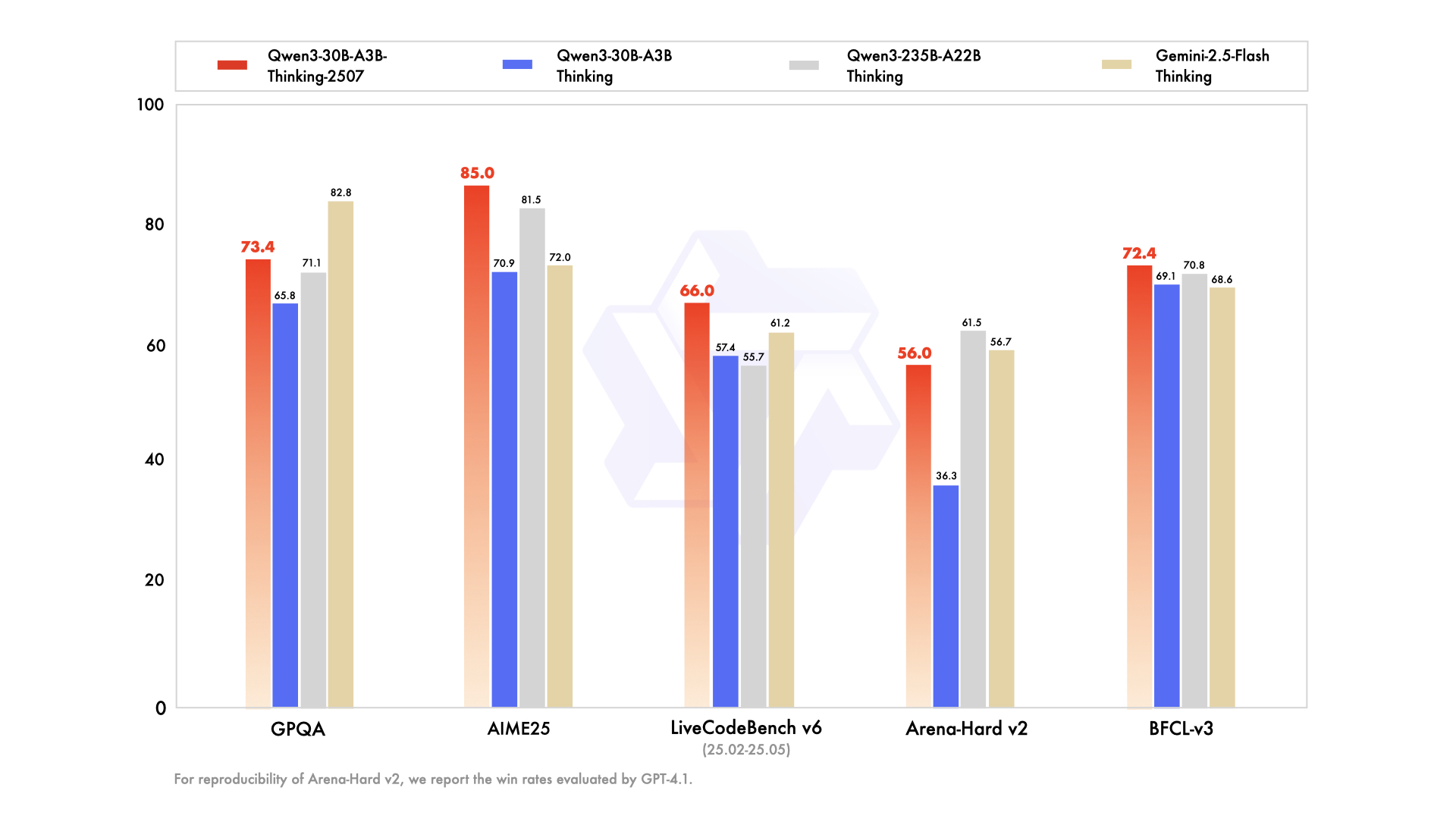
性能表现
该模型在一系列行业标准基准测试中展现了强大的性能,尤其在以下方面提升显著:
- 推理能力: 在
AIME25(数学推理) 和HMMT25(数学竞赛) 等高难度测试中得分大幅领先前代模型及部分竞品。 - 编码能力: 在
LiveCodeBench和OJBench等编码测试中表现优异。 - 综合能力: 在知识问答 (
MMLU-Pro)、与人类偏好对齐 (Arena-Hard v2)、Agent应用 (BFCL-v3,TAU系列) 等多个维度均表现出色。
使用与部署
- 环境依赖: 建议使用最新版本的
Hugging Facetransformers库 (>=4.51.0) 以避免兼容性问题。 - 快速上手: 文档提供了使用
Python和transformers库加载模型并进行文本生成的代码示例,并说明了如何从输出中分离思考内容和最终答案。 - 部署方案: 支持使用
sglang和vLLM等主流框架进行高效部署,并提供了相应的启动命令。同时,也支持Ollama,LMStudio等本地化应用。 - Agent 应用: 模型具备强大的工具调用能力,推荐结合
Qwen-Agent框架来简化开发,充分利用其Agent潜能。
最佳实践
为了获得模型的最佳性能,官方给出了以下建议:
- 采样参数: 推荐设置
Temperature=0.6,TopP=0.95。 - 输出长度: 对于大多数查询,建议输出长度为
32,768tokens;对于数学、编程等高复杂度问题,建议将长度设为81,920tokens,以给予模型充分的思考空间。 - 规范输出: 在进行评测时,建议使用提示词来标准化输出格式,例如要求数学题提供解题步骤,或要求选择题以特定
JSON格式作答。 - 多轮对话: 在构建多轮对话历史时,应只保留模型的最终回答部分,不应包含其思考过程内容。