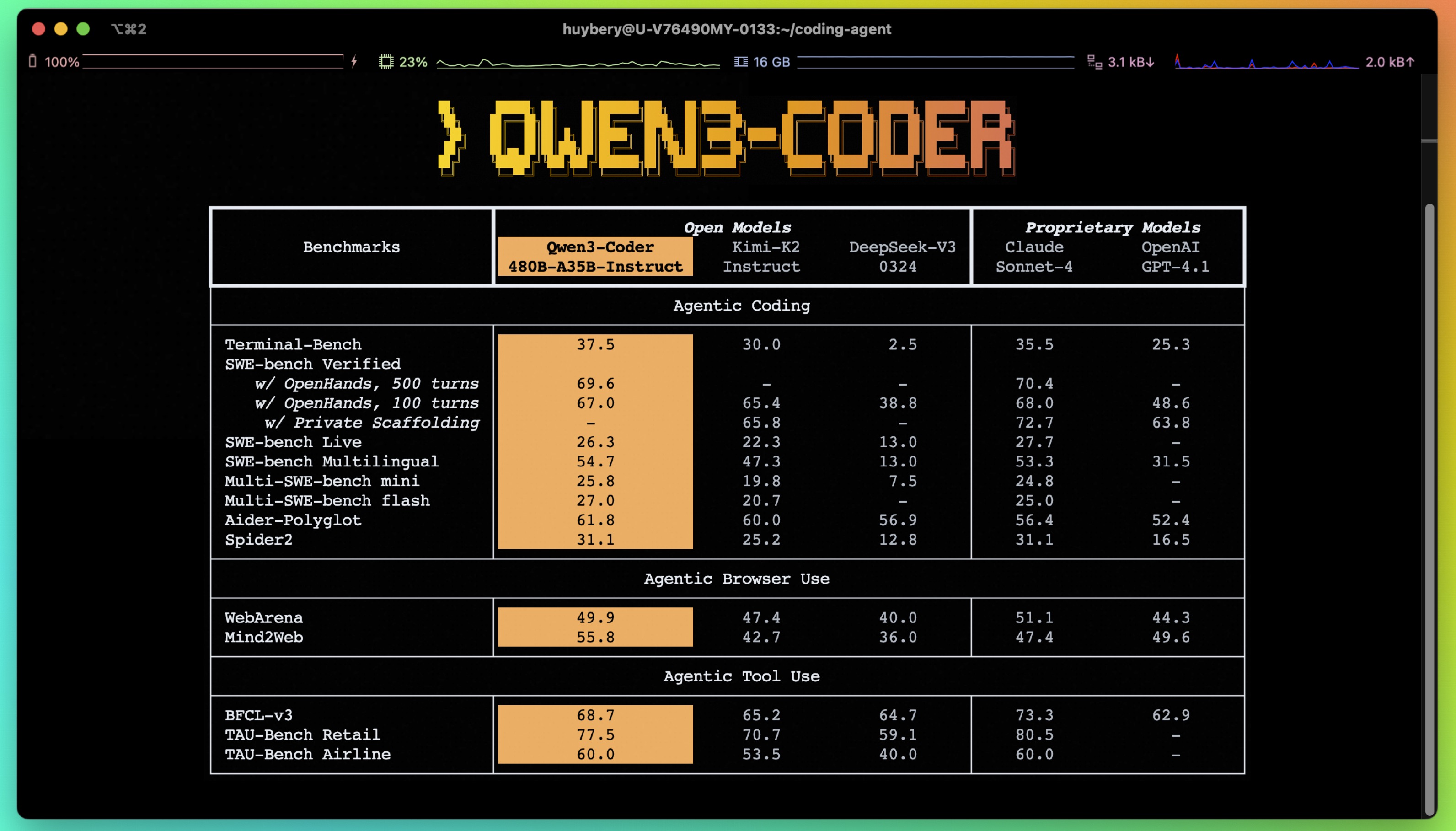
阿里巴巴 Qwen 团队发布的最新代码模型 Qwen3-Coder-480B-A35B-Instruct。该模型在代理式编程、长上下文处理和工具调用方面取得了显著进展。
模型规格
- 模型类型:因果语言模型 (Causal Language Models)。
- 参数规模:采用混合专家 (MoE) 架构,总参数量为
480B(4800亿),单次推理激活35B(350亿) 参数。 - 模型结构:包含
62个层,160个专家(每次激活8个),并使用分组查询注意力 (GQA) 机制。 - 上下文长度:原生支持
256Ktokens,为处理大规模代码和文档提供了基础。
使用与集成
- 快速上手:官方建议使用最新版本的
transformers库进行调用,并提供了详细的 Python 代码示例。 - 本地化支持:模型已得到
Ollama、LMStudio、MLX-LM、llama.cpp等多种本地部署工具的支持。 - 内存管理:如果遇到内存不足 (OOM) 的问题,建议将上下文长度缩短(例如
32,768)。
代理式编码 (Agentic Coding)
- 工具调用:模型的核心优势之一是其出色的工具调用能力。用户可以像使用
OpenAIAPI 一样,轻松定义和调用自定义函数(工具)。 - 专用格式:模型采用了为函数调用特别设计的格式,以提升其作为代理的效率和准确性。
最佳实践
- 推荐参数:为获得最佳生成效果,建议设置
temperature=0.7,top_p=0.8,top_k=20,repetition_penalty=1.05。 - 输出长度:建议为大多数查询设置
64Ktokens 的最大输出长度,以确保模型能完整地生成复杂代码或回答。
模型表现
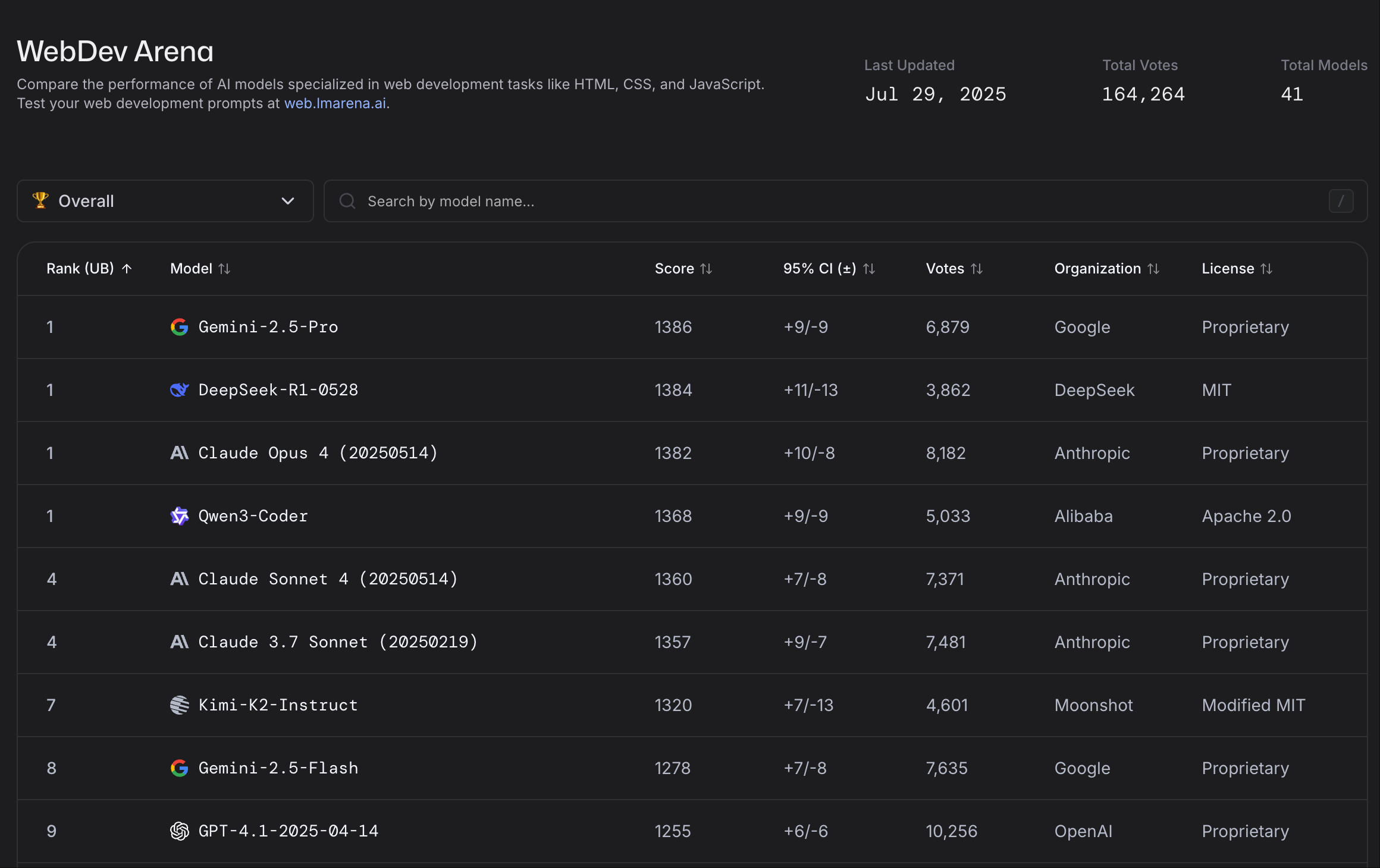
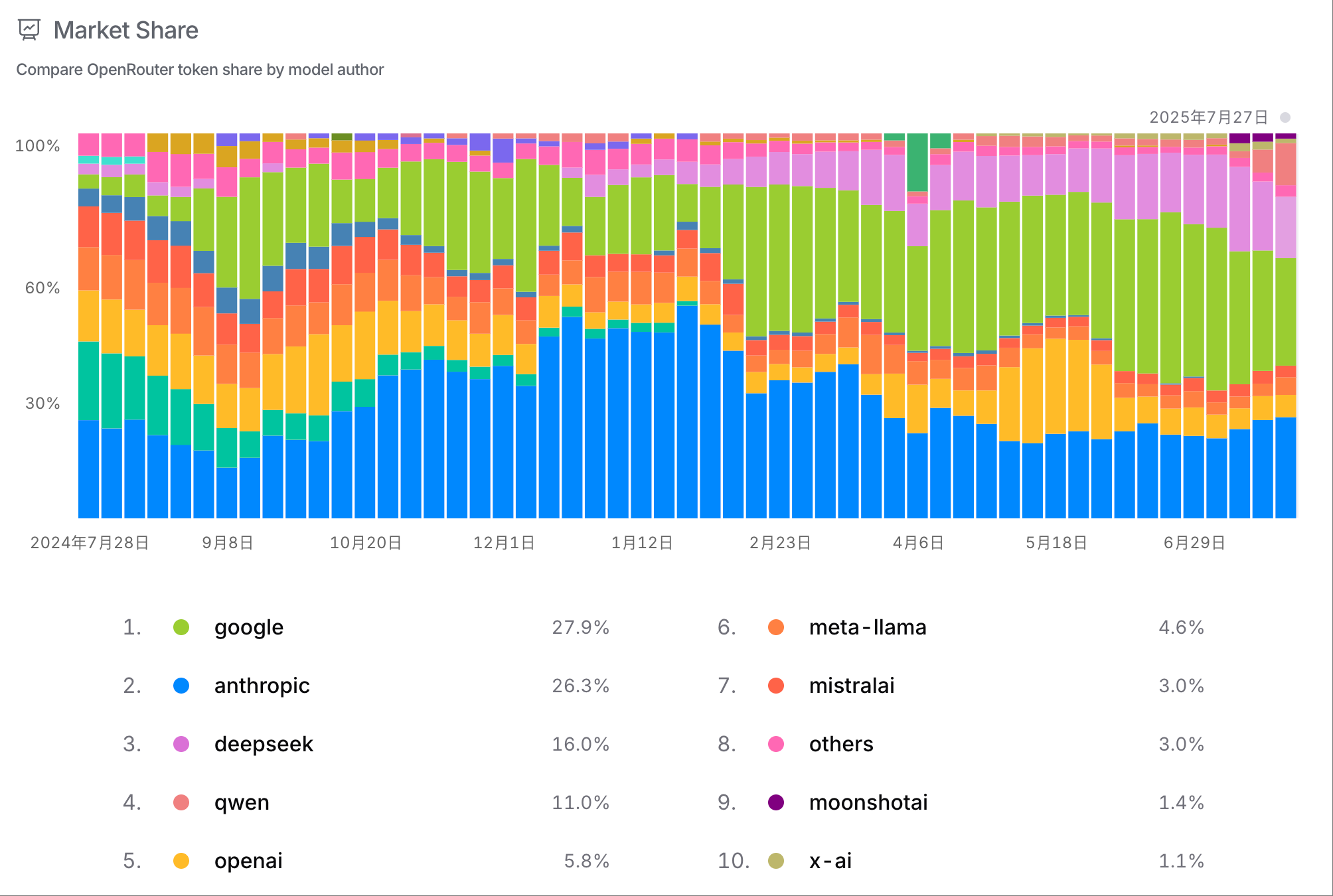
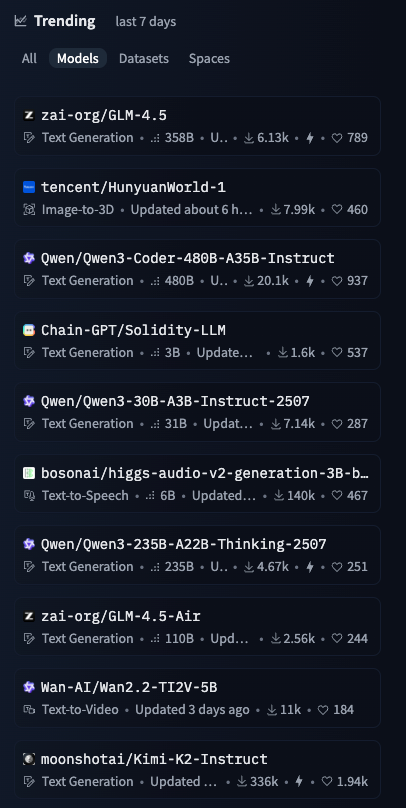
Qwen3-Coder-480B-A35B-Instruct 上线近一周后,在 OpenRouter 上 Qwen 模型调用量翻了 5 倍,排名第四,仅次于 DeepSeek。在 HuggingFace 近七日 Trending 上 Qwen3-Coder 也位列第一。在LLMArena WebDev 上也和 Gemin 2.5 pro 并列第一。