阿里发布了 Qwen 系列首个万亿参数的模型:Qwen3-Max-Preview(Instruct),模型参数超 1 万亿,非思考模型。目前可以在 qwen chat 或 api 上接入来体验,基准测试显示,其性能优于 Qwen3-235B-A22B-2507。内部测试和早期用户反馈证实:性能更强,知识更广,在对话、Agent 任务和指令遵循方面表现更佳。但不开源!!
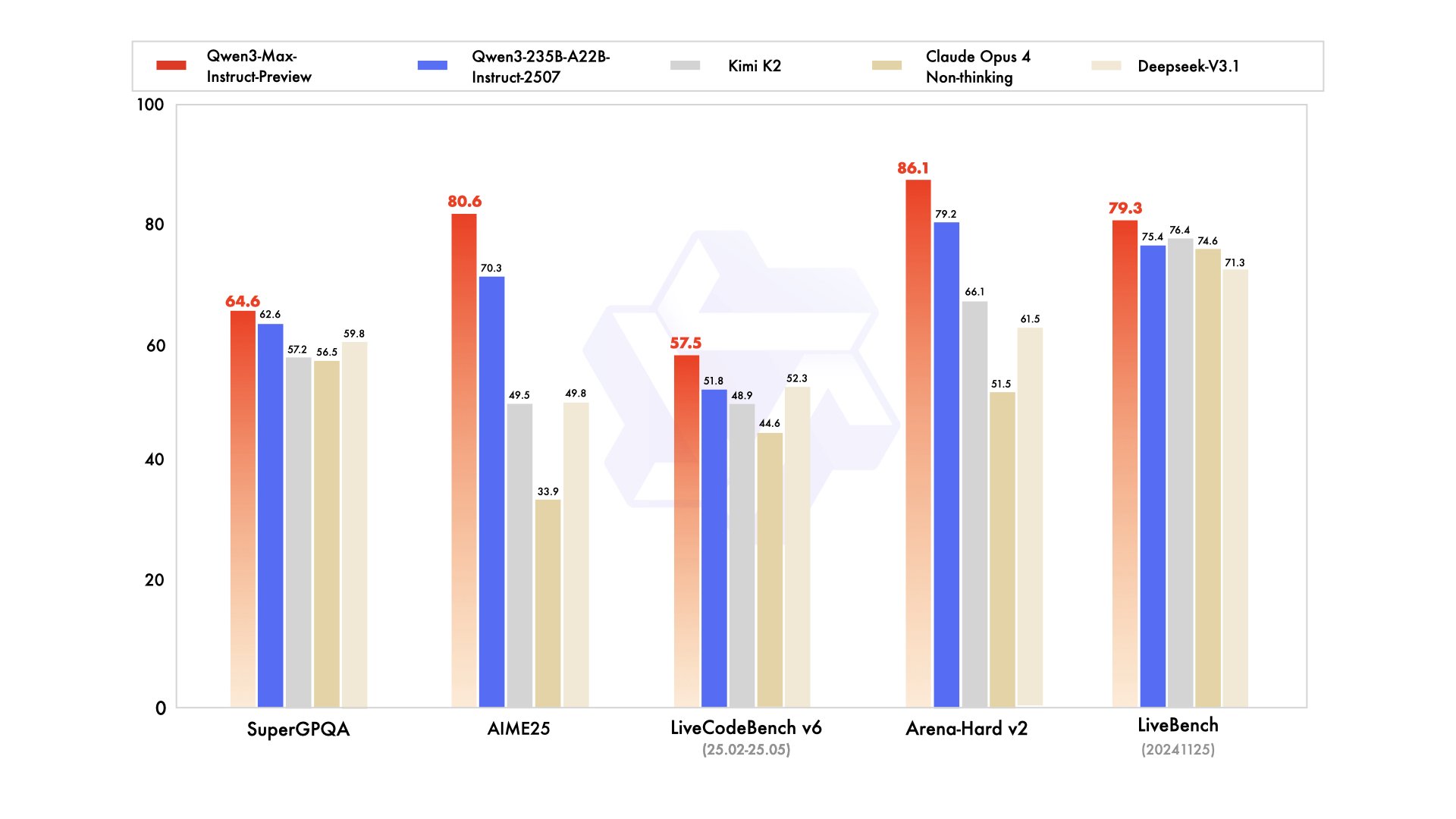
从 benchmark 上来看,作为一个非思考模型能力算是很强了,官方的这个图标上没有对比目前的顶级闭源模型的对比,可能是因为目前的顶级模型都是深度思考模型。我找了下在同一指标下 gpt-5 和 gemini 2.5 pro 的变现。
在 AIME 25(美国数学竞赛)指标上,Qwen3-Max-Preview(Instruct) 得分 80.6% 。非思考模式且不用工具的情况下的 gpt-5 仅得分 61.9 %,若开启思考则能达到 94.6%。对比思考模型,gemini 2.5 pro 和 DeepSeek r1 分别是 88% 和 87.5%。
在 LiveCodeBench(编程)指标上,Qwen3-Max-Preview(Instruct) 得分 57.6% 。对比思考模型,gemini 2.5 pro 为 69%。
最后,阿里这个万亿参数模型没有开源挺令人意外的,现在的开源更像是一种宣发策略,通过开源让社区自传播,既省去了推广费,又有机会复刻年初 DeepSeek R1 的爆火盛况。如果重投入开发出一个模型却没人使用,这个模型的收益就几乎为零了。反观国内的两个一直闭源的小虎:Kimi 和 智谱,他们今年全是走的开源策略,特别是 Kimi,大大减少 C 端投放,把投入重点放到模型研发上,至于推广靠开源来实现,比如 K2 的火爆也是这个策略带来的收益。当然,Qwen这次的逻辑有可能是先放出指标,引流到自家产品上,等过段时间再开源,抑或是走了部分模型开源,部分模型闭源的策略。
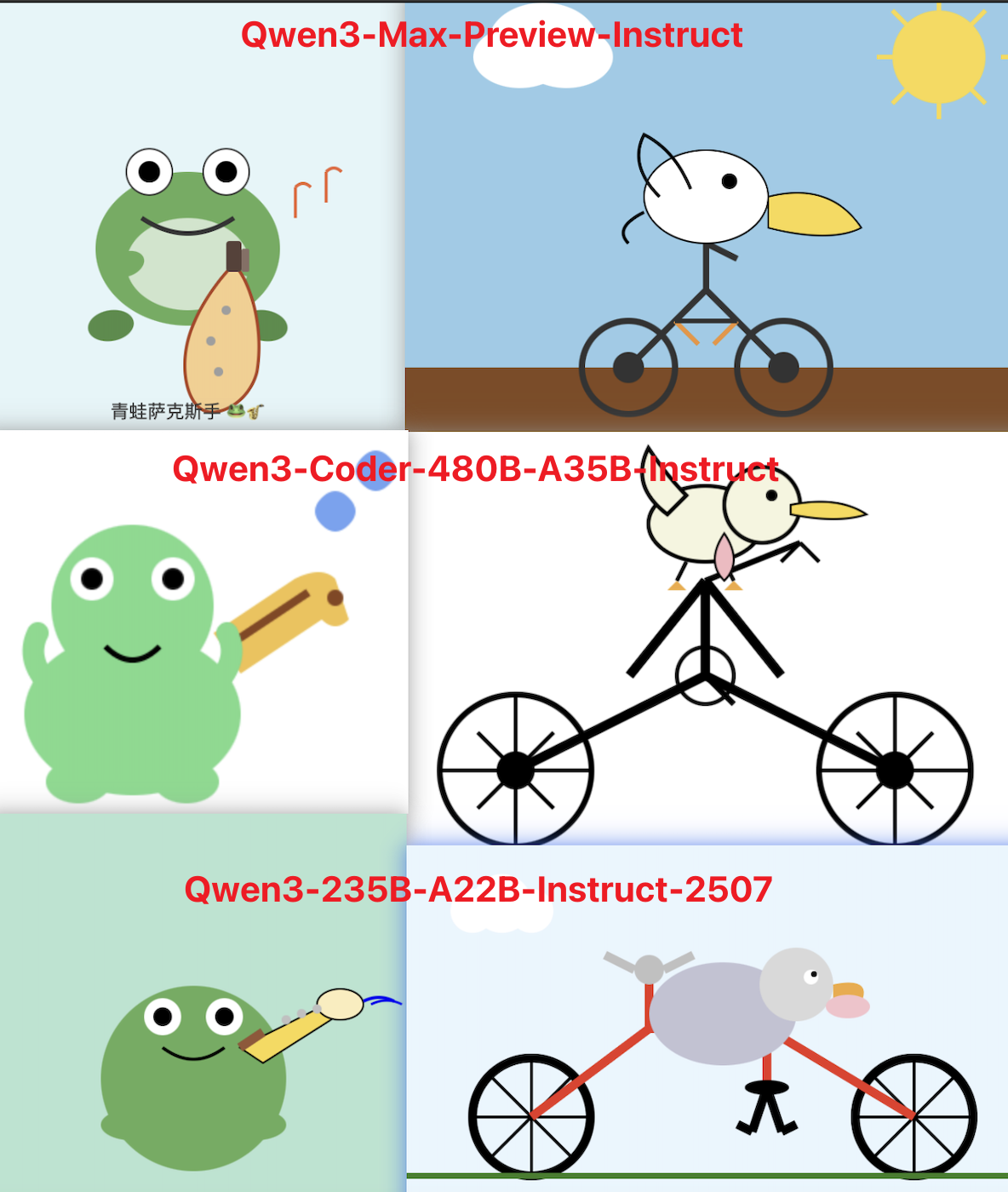
最后的最后,还是用两个经典的编程题目来看一下 Qwen3-Max-Preview(Instruct) 的实际能力:生成一个鹈鹕骑车的 svg 和 生成一只青蛙演奏萨克斯的 svg。从结果上看,这个模型的编码能力确实要优于 Qwen3-235B-A22B-2507 和 Qwen3-Coder-480B-A35B-Instruct。