Qwen 团队认为 Scaling Laws 法则仍然是未来大模型发展的趋势,主要包括 Context Length Scaling 和 Total Parameter Scaling。基于这个判断,Qwen 团队推出 Qwen3-Next 全新大模型架构,这个架构的核心就是为了提升在长上下文处理和大规模参数下的训练与推理效率。通过一个数据可以直观的看到基于这个架构的模型表现,Qwen3-Next-80B-A3B 仅用不到 Qwen3-32B 模型十分之一的训练资源,就达到了相近甚至更好的性能,并在长上下文推理场景下实现了超过 10 倍的吞吐量提升。
基于 Qwen3-Next-80B-A3B-Base 模型,Qwen 团队开源了 Qwen3-Next-80B-A3B-Instruct 与 Qwen3-Next-80B-A3B-Thinking。Instruct 版本在超长上下文任务上优势明显,性能媲美旗舰模型 Qwen3-235B;Thinking 版本在复杂推理任务上超越了 Gemini-2.5-Flash-Thinking 等顶级闭源模型。
架构创新
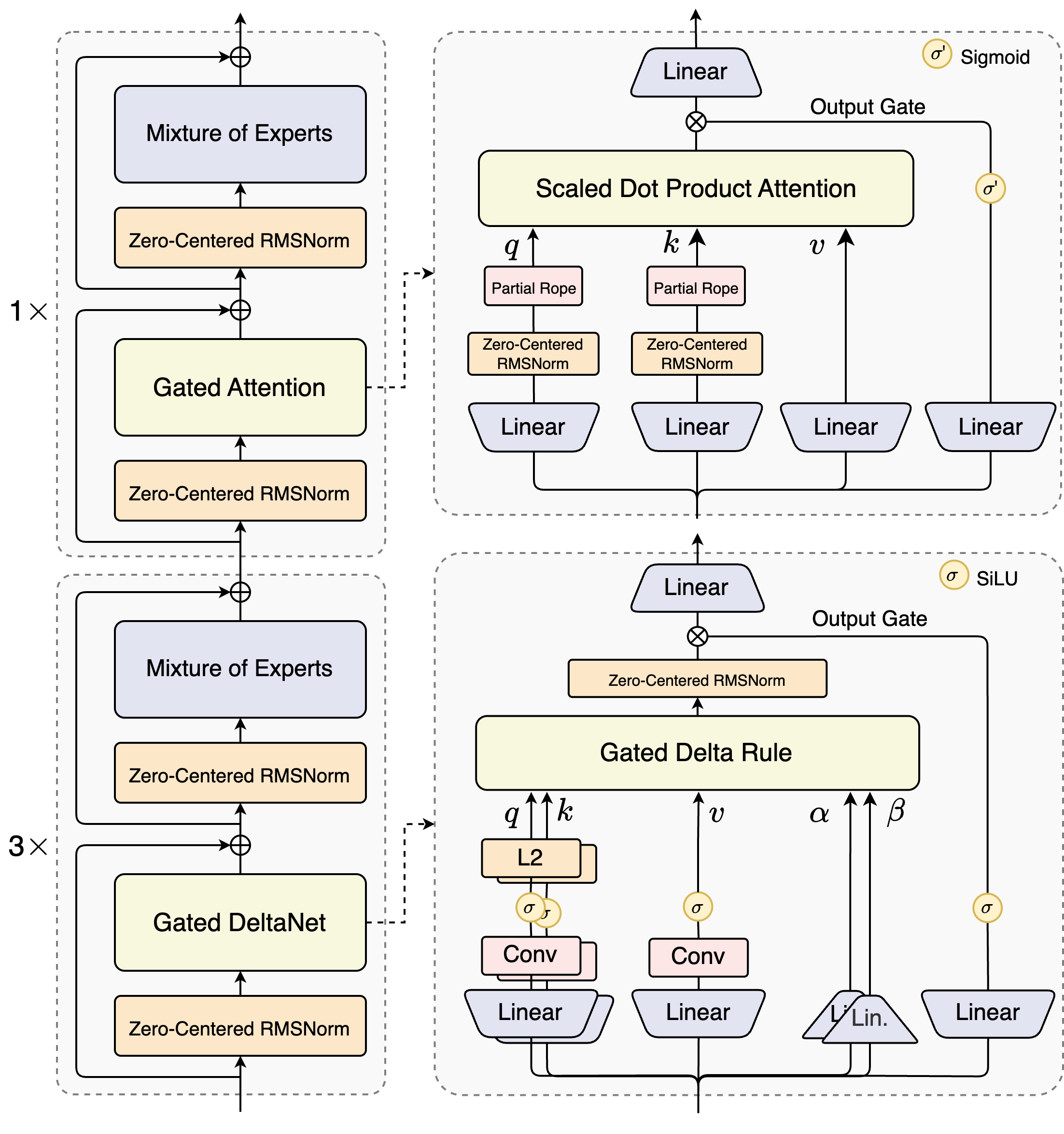
- 混合注意力机制: 模型中 75% 的层使用 Gated DeltaNet 以提升长文本处理效率,25% 的层保留增强后的标准注意力以确保模型性能,实现了效率与效果的最佳平衡。
- 高稀疏度 MoE 结构: 模型总参数量达到 80B,但每次推理仅激活约 3B 参数。专家系统扩展至 512 个总专家,并采用 10 个路由专家和 1 个共享专家的组合,最大化资源利用率。
- 训练稳定性优化: 采用了 Zero-Centered RMSNorm、权重衰减和 MoE router 参数归一化等技术,确保了模型在复杂架构下训练的稳定性。
- 多 Token 预测 (MTP): 原生支持 MTP 机制,通过一次预测多个 token,有效提升了 Speculative Decoding 的效率和推理速度。
训练与推理效率
- 训练成本: 使用 15T tokens 的数据进行预训练,所消耗的 GPU Hours 仅为 Qwen3-32B 模型的 9.3%
- 推理吞吐量: 与 Qwen3-32B 相比,在 32k 以上的长上下文场景中,预填充和解码阶段的吞吐量均提升了 10 倍以上。
模型性能表现
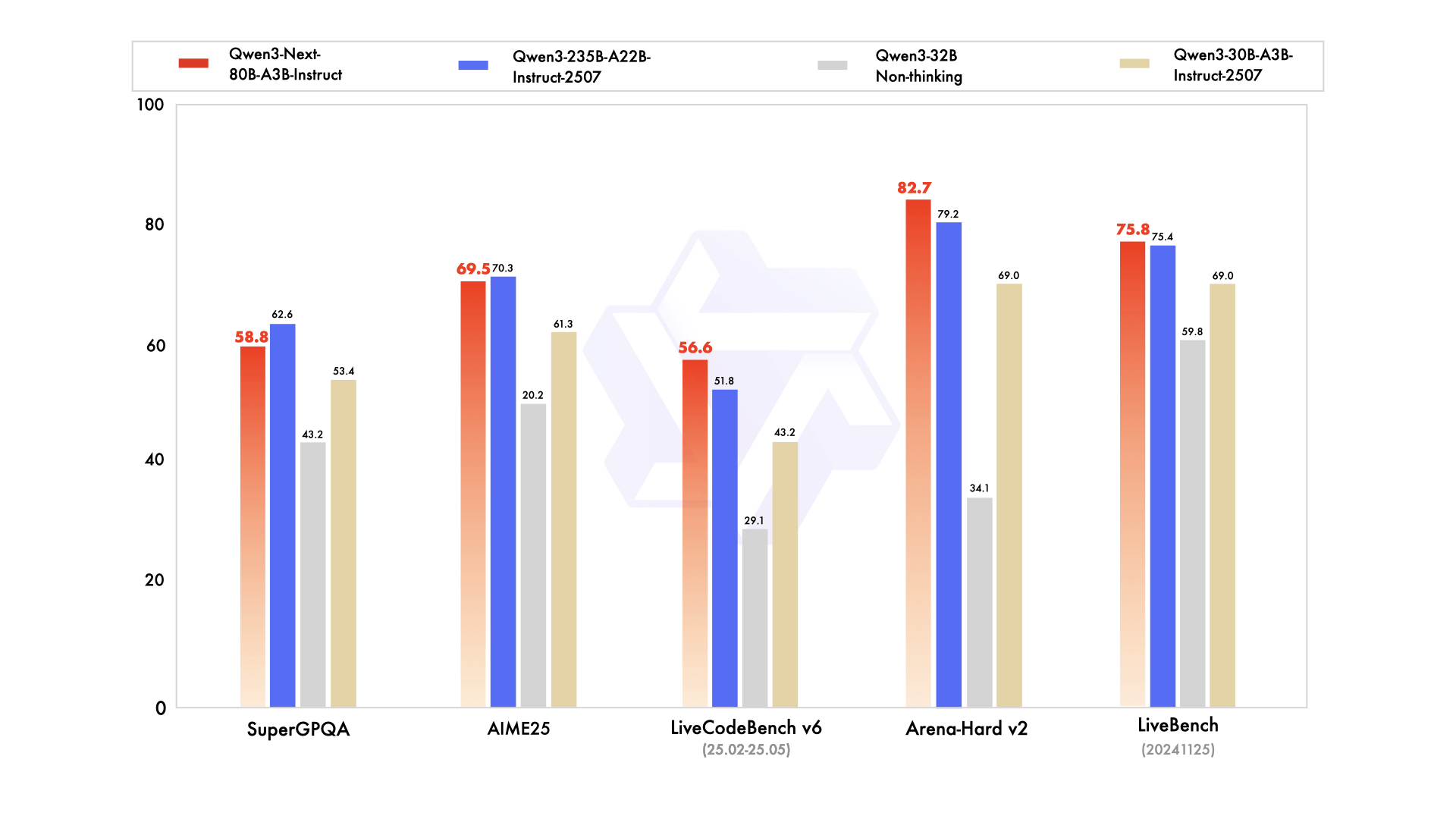
- Qwen3-Next-80B-A3B-Base 在多数基准测试中超越了激活参数多近 10 倍的 Qwen3-32B-Base 模型。
- Qwen3-Next-80B-A3B-Instruct 性能与旗舰模型 Qwen3-235B-A22B-Instruct-2507 相当,并在 256k 超长上下文处理上表现更优。
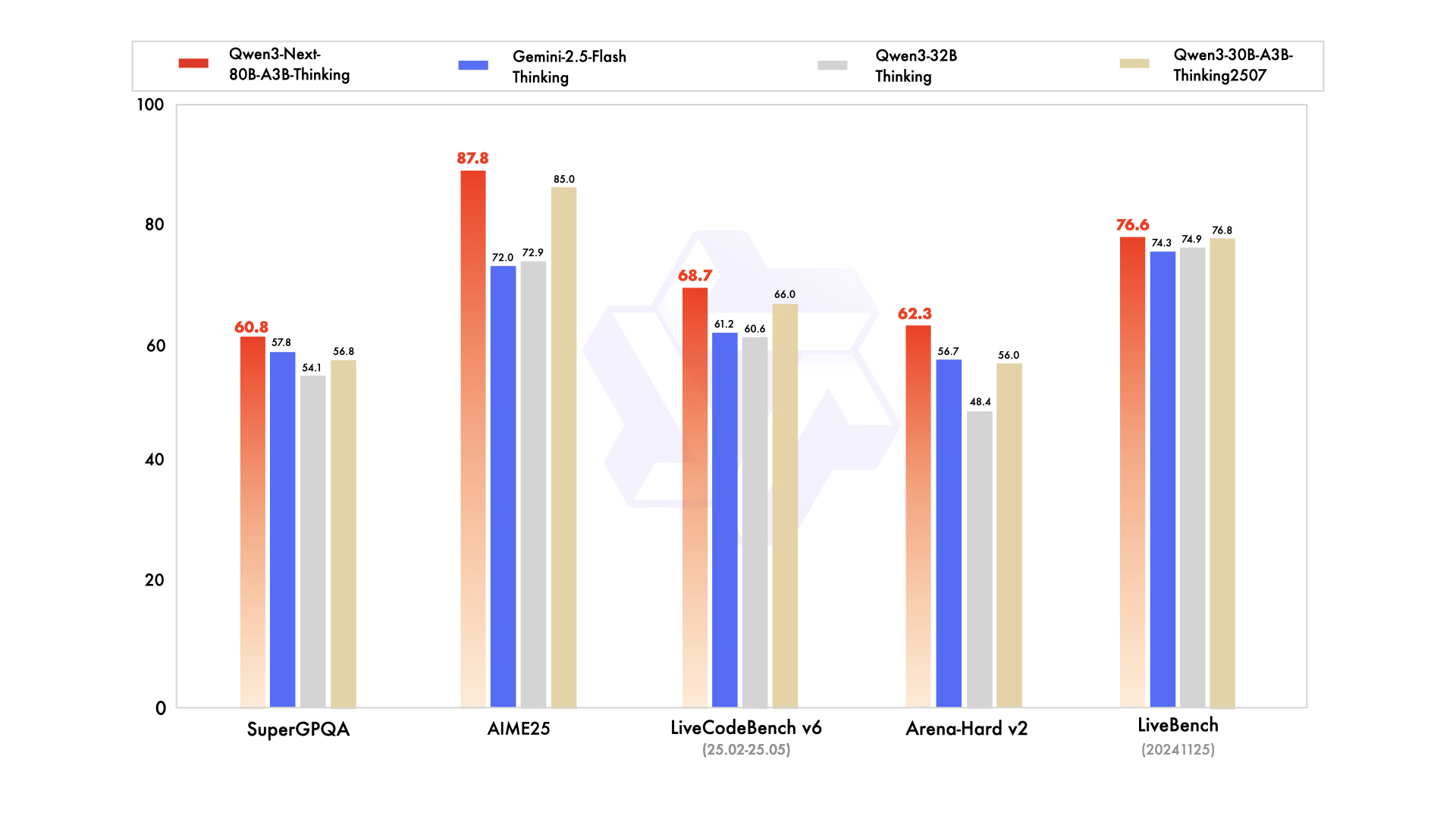
- Qwen3-Next-80B-A3B-Thinking 在复杂推理任务上优于 Qwen3-32B-thinking,并超越了闭源模型 Gemini-2.5-Flash-Thinking。
开源与体验地址
- Hugging Face: https://huggingface.co/collections/Qwen/qwen3-next-68c25fd6838e585db8eeea9d
- 体验地址:https://qwen.aliyun.com/chat,选择模型:Qwen3-Next-80B-A3B