2025 年 7 月 10 号马斯克旗下的 AI 公司 xAI 发布了史上最强模型 Grok 4,在所有评测集上碾压所有已发布模型,甚至在 AIME25 评测集上拿下了满分。
关于 Grok 4 的基本信息
Grok 4 是一个推理模型,支持文本和图像输入,支持函数调用和结构化输出。
- 256K token 的上下文窗口。低于 Gemini 2.5 Pro 的 1M token 上下文窗口,但领先于 Claude 4 Sonnet 和 Claude 4 Opus(200K token)、o3(200K token)以及 R1 0528(128K token)。
- 定价与 Grok 3 相当,为每百万输入/输出 token 3/15 美元(每百万缓存输入 token 0.75 美元)。其每 token 定价与 Claude 4 Sonnet 相同,但比 Gemini 2.5 Pro(输入 token 少于 20 万时,为 1.25/10 美元)和 o3(近期降价后,为 2/8 美元)更贵。
- 每秒输出 75 个 token,慢于 o3(188 token/s)、Gemini 2.5 Pro(142 token/s)、Claude 4 Sonnet Thinking(85 token/s),但快于 Claude 4 Opus Thinking(66 token/s)。
Grok 4 的订阅费为 30 美元/月。此外,还有一个 Grok 4 Heavy 是个多智能体版本,费用为 300 美元/月。
发布会上,也公布了 Grok4 的训练量的情况,Grok2 到 Grok3 提高 10 倍,Grok3 到 Grok4 又提高 10 倍。毕竟 xAI 有 20 万卡集群,不继续 Scaling 也不行啊。
最后,xAI API 平台已经上架 grok-4-0709,可以通过 API 接入。注意,目前 API 接口中还不会返回思考过程,可能是防止被其他人用来蒸馏小模型。
Grok 4 在公开测试集的表现
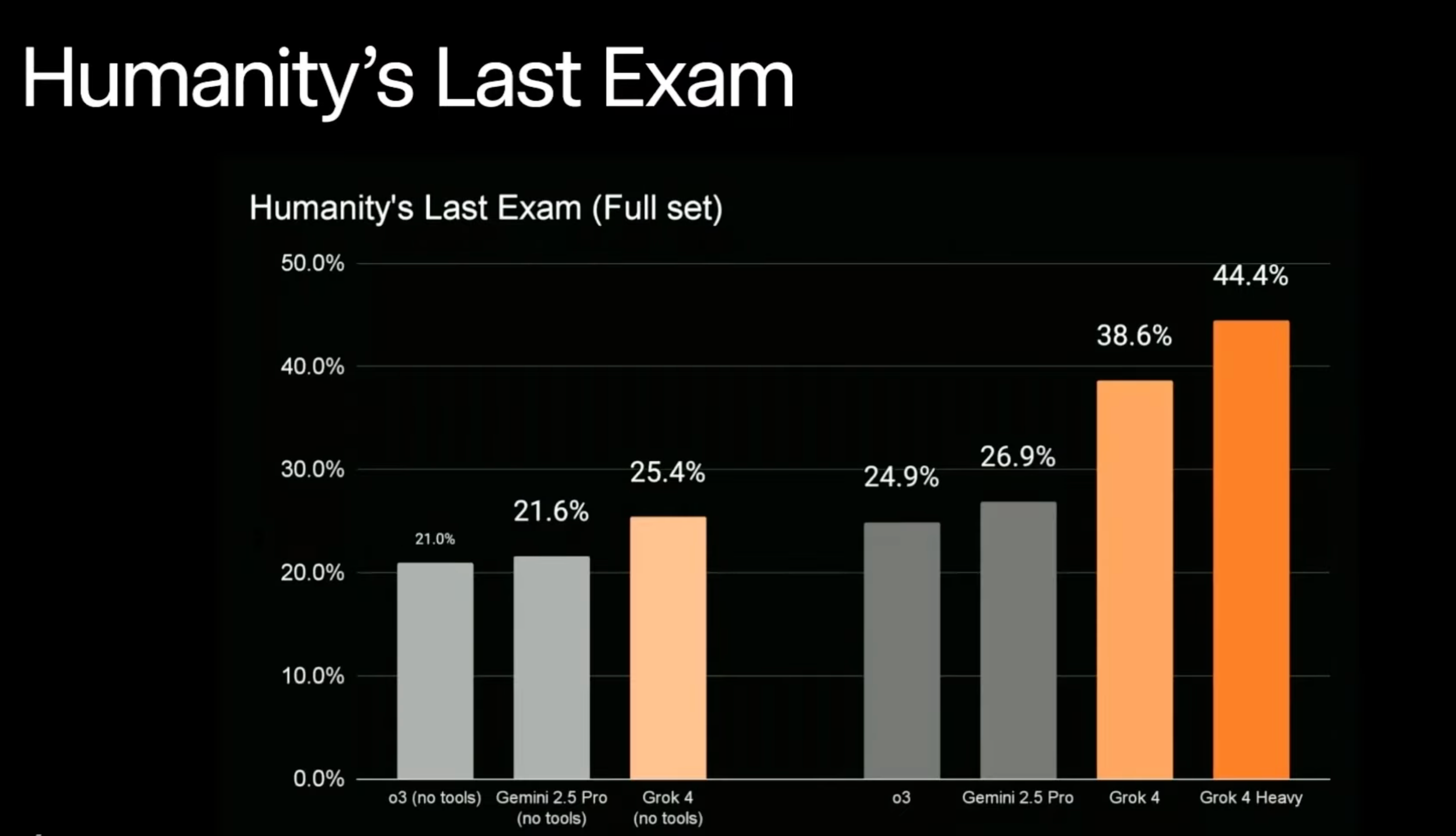
人类最终考试(HLE)评测集
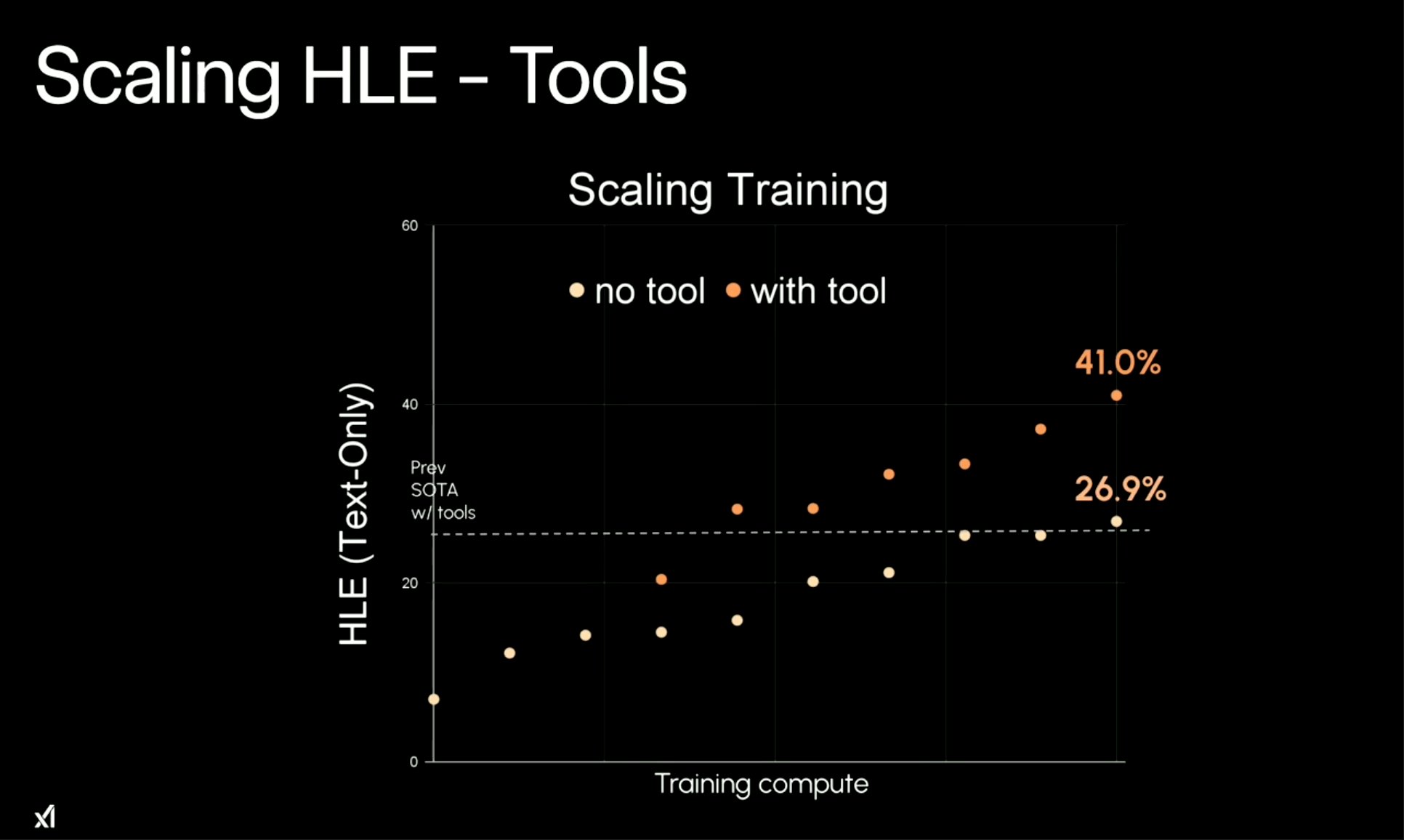
训练时扩展(Scaling - Training)的表现(带工具 vs 不带工具):
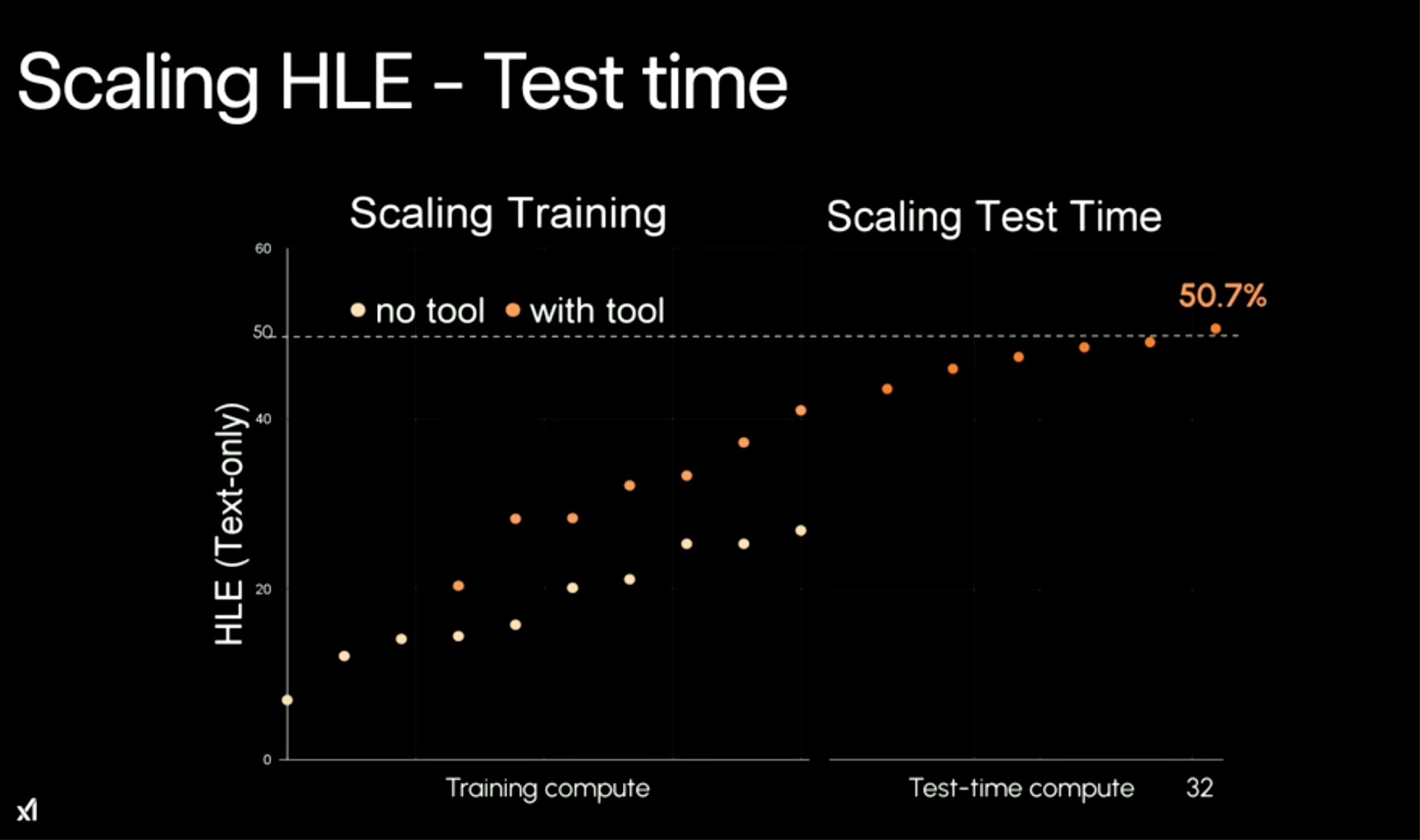
测试时计算扩展(Scaling - Test Time)的表现(带工具 vs 不带工具):
“人类最终考试”(HLE)包含约 3,000 道来自数学、物理、生物、工程、人文等多个学科的选择题和简答题,其中一部分为图文多模态题目。它主要评测大模型在跨领域专业知识、复杂推理和图文理解能力上的表现,衡量是否接近人类专家水平。
基准测试
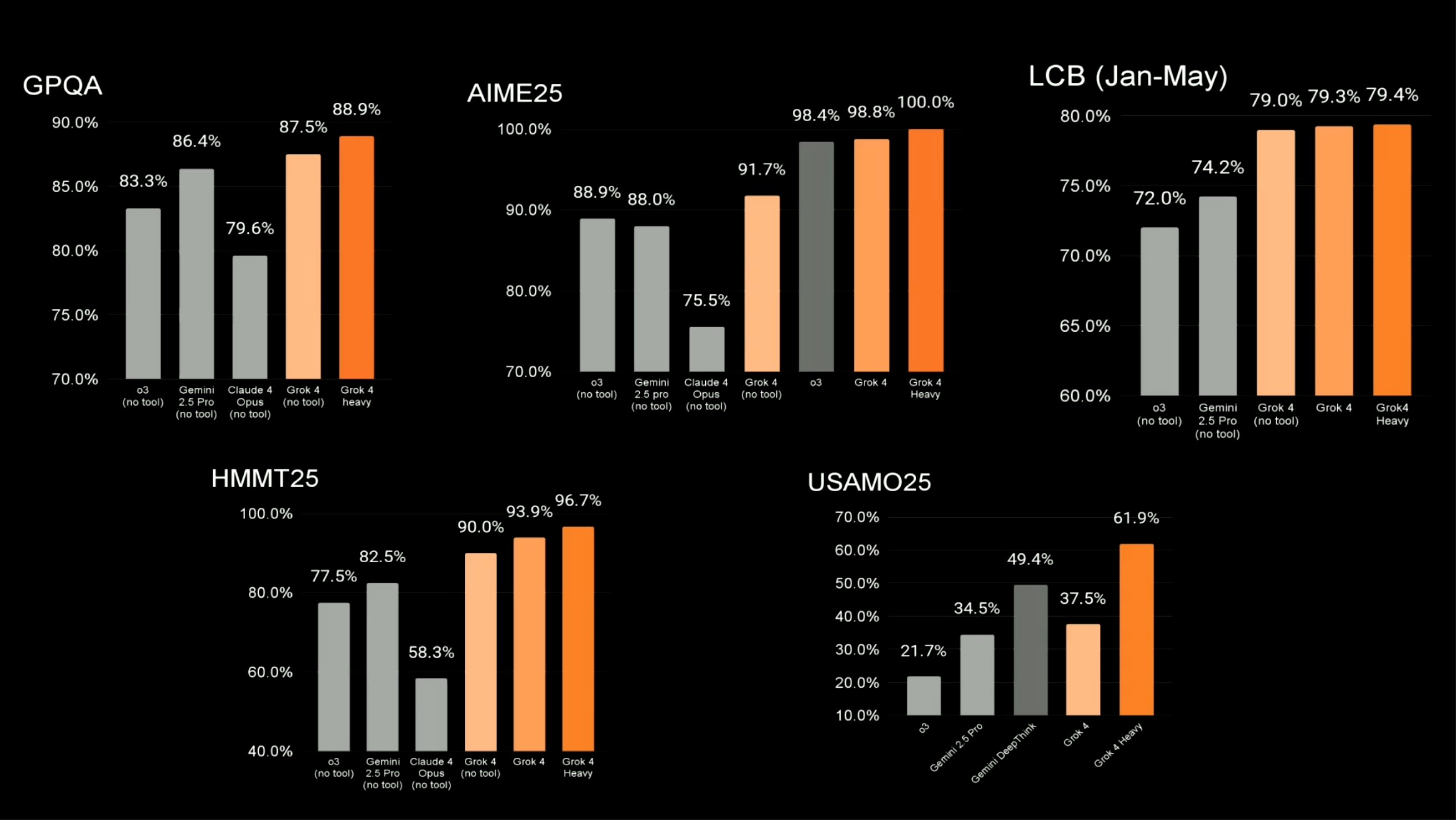
GPQA 包含 448 道来自真实研究生物理考试和教材的问答题,覆盖力学、电磁学、量子、热统、相对论等领域。它用于评测模型在高阶物理概念理解、推导能力和严谨推理方面的专家级水平。
AIME25 收录的是 2025 年 AIME 数学竞赛的原题,共 15 道中等到高难度的整数答案题。评测重点是大模型的中学奥数解题能力、代数与组合推理、精准计算与逻辑推导。
LCB 是一套综合性的编程任务集合,来自 2025 年 1 月至 5 月的真实 GitHub 问题和编码挑战,题目涵盖 Python、算法、系统设计等多种类型。它用于评估模型在多轮代码生成、调试能力和真实场景下的代码实用性方面的表现。
HMMT25 包含 2025 年 HMMT 数学竞赛的题目,题型丰富,包括代数、数论、组合、几何等高难度题。评测模型在顶尖中学生水平的数学建模与解题能力、多步骤逻辑推理和灵活策略选择上的表现。
USAMO25 收录的是 2025 年美国数学奥林匹克的完整试题,均为极具挑战性的开放性证明题。它衡量大模型是否具备结构化书面证明构建能力、抽象思维深度和跨领域逻辑组织能力。
ARC-AGI 评测集
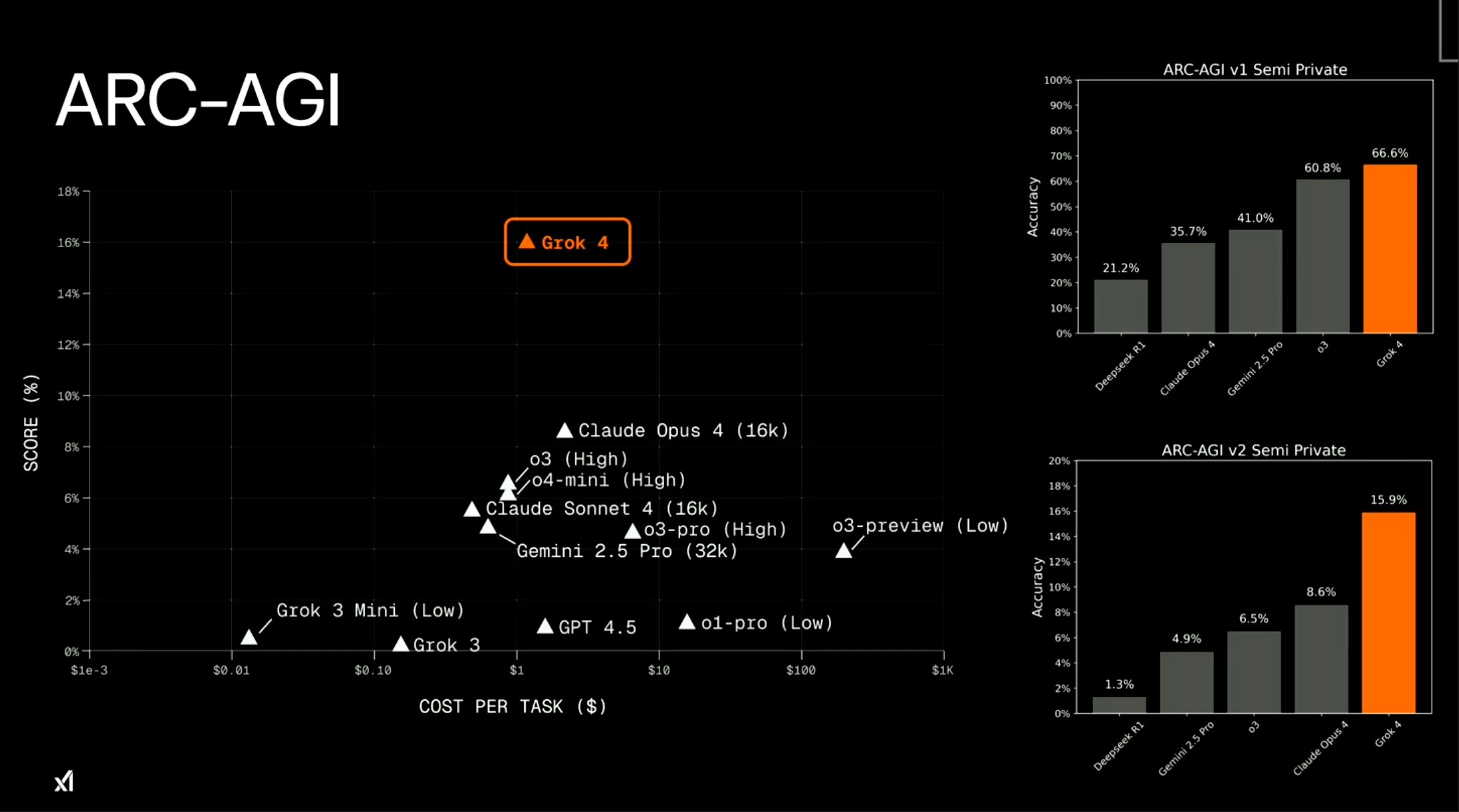
ARC-AGI 的题目是一些彩色方格组成的图形输入输出对,模型需从少量示例中推理出隐藏的变换规则,并应用于新任务。它主要评测大模型在抽象推理、泛化能力和少样本学习方面是否具备接近人类的通用智能水平。
Vending-Bench
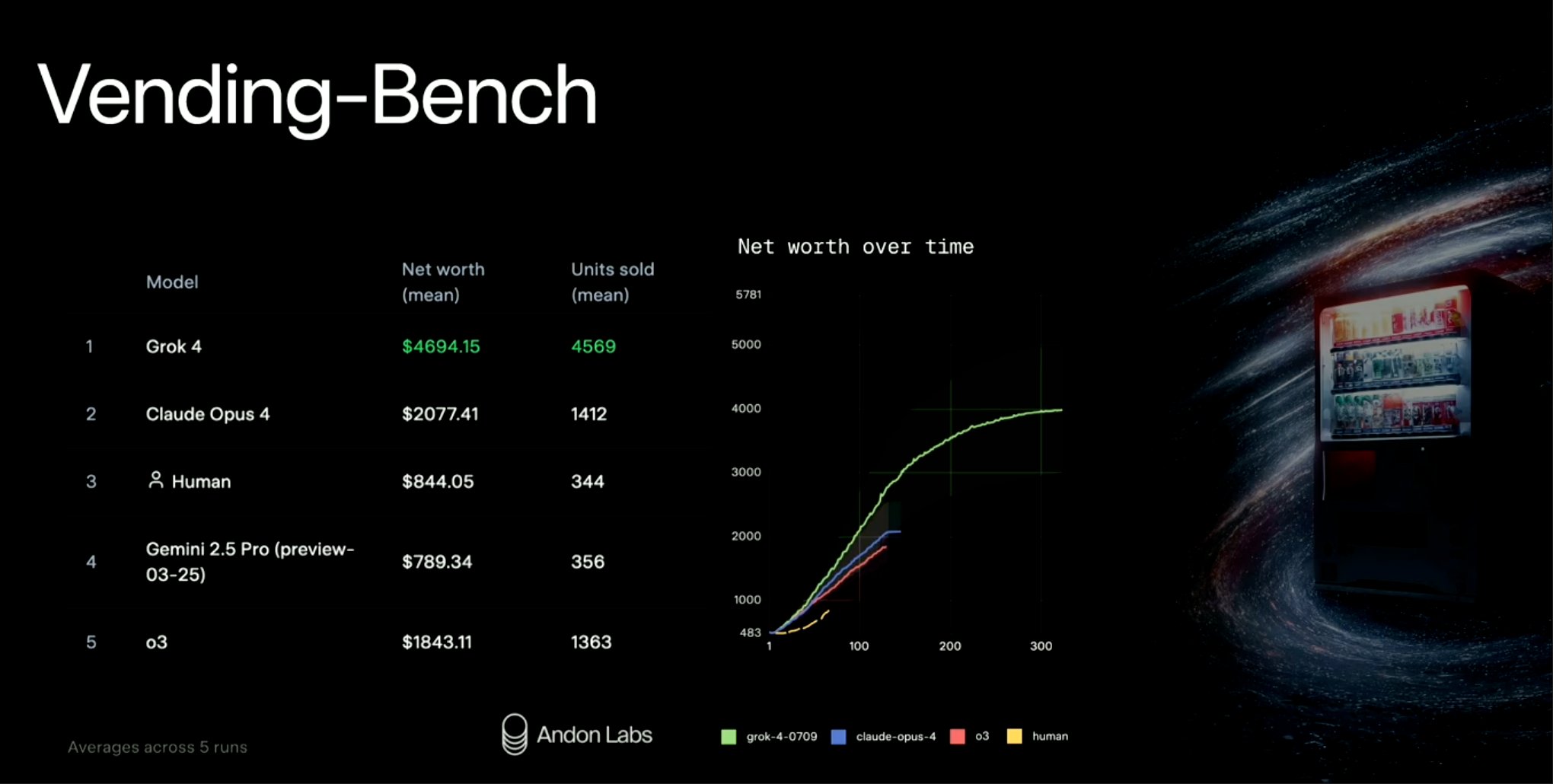
“Vending-Bench” 是一个 Long‑Term Coherence Benchmark,用于评测大模型(LLM)作为“自主智能体”在长期连续任务中的表现,尤其是模拟运营自动售货机这种长流程、需要持续决策的业务场景。
Artificial Analysis 的评测
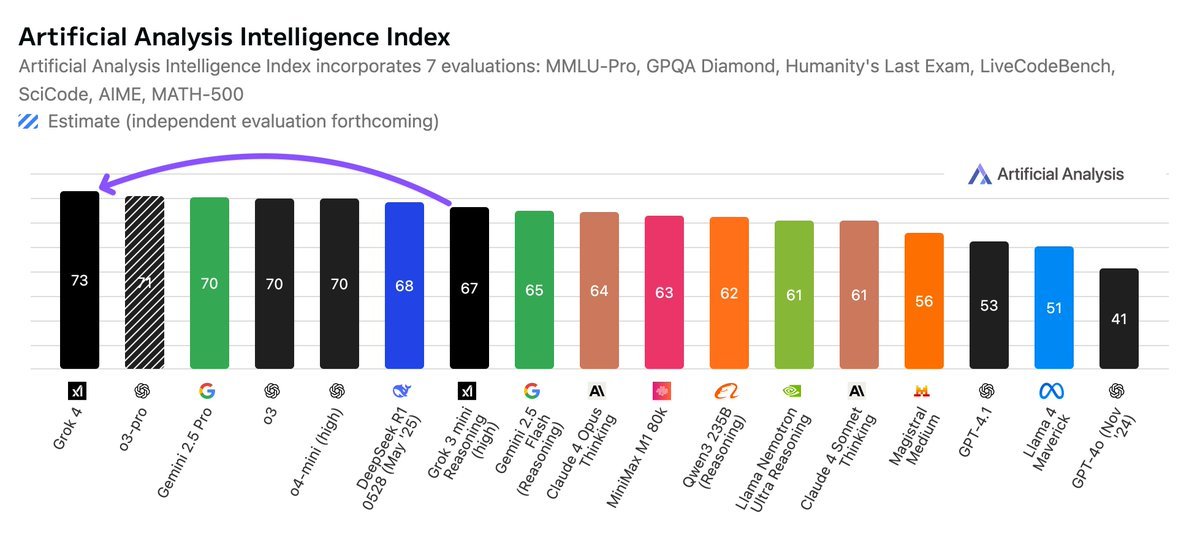
“Artificial Analysis”(一家独立的 AI 基准测试与分析公司)抢先体验了 Grok 4,并通过 xAI 的 API 进行了评测。
Grok 4 在 Artificial Analysis Intelligence Index 上取得了 73 分,位居第一位,领先于 OpenAI o3 的 70 分、Google Gemini 2.5 Pro 的 70 分、Anthropic Claude 4 Opus 的 64 分以及 DeepSeek R1 0528 的 68 分。
关键基准测试结果:
➤ Grok 4 在我们的“Artificial Analysis Intelligence Index”中领先,在“编程指数”(Coding Index, 基于 LiveCodeBench & SciCode)和“数学指数”(Math Index, 基于 AIME24 & MATH-500)中也同样领先。
➤ 在 GPQA Diamond 测试中取得了 88% 的历史最高分,较 Gemini 2.5 Pro 先前创下的 84% 记录实现了飞跃。
➤ 在“人类终极考试”(Humanity’s Last Exam)中取得了 24% 的历史最高分,超过了 Gemini 2.5 Pro 先前创下的 21% 的历史高分。请注意,我们的基准测试套件使用的是原始的 HLE 数据集(2025 年 1 月版),并且运行的是无工具的纯文本子集。
➤ 在 MMLU-Pro 和 AIME 2024 测试中分别取得了 87% 和 94% 的并列最高分。
xAI 下一步的计划
xAI 在发布会的最后公布了接下来的计划是:
➡️ 8 月份发布编码模型。
➡️ 9 月份发布多模态 Agent。
➡️ 10 月份发布视频生成模型。昨天马斯克发文说“AI 视频生成正在以光速发展”,可能也预示着 xAI 团队的视频生成也在朝着 Veo3 的水平走了,甚至更好。

总之,在科技领域的创新你永远可以相信马斯克,期待接下来三个月 xAI 团队的进展和发布。