Google 大概几周之前就在 LMArena 上测试了 nano-banana,并很快受到社区的热捧,核心原因图像一致性保持的能力过于强大,一会会给大家一些例子来展示一下。Google 于 2025 年 8 月 26 日正式发布该模型,学名叫 Gemini 2.5 Flash Image。这个模型强大的有以下几点:
非常强大的角色一致性的保持
它可以将同一个角色放置在不同的环境中,在新场景中从多个角度展示单个产品,同时保留主体。

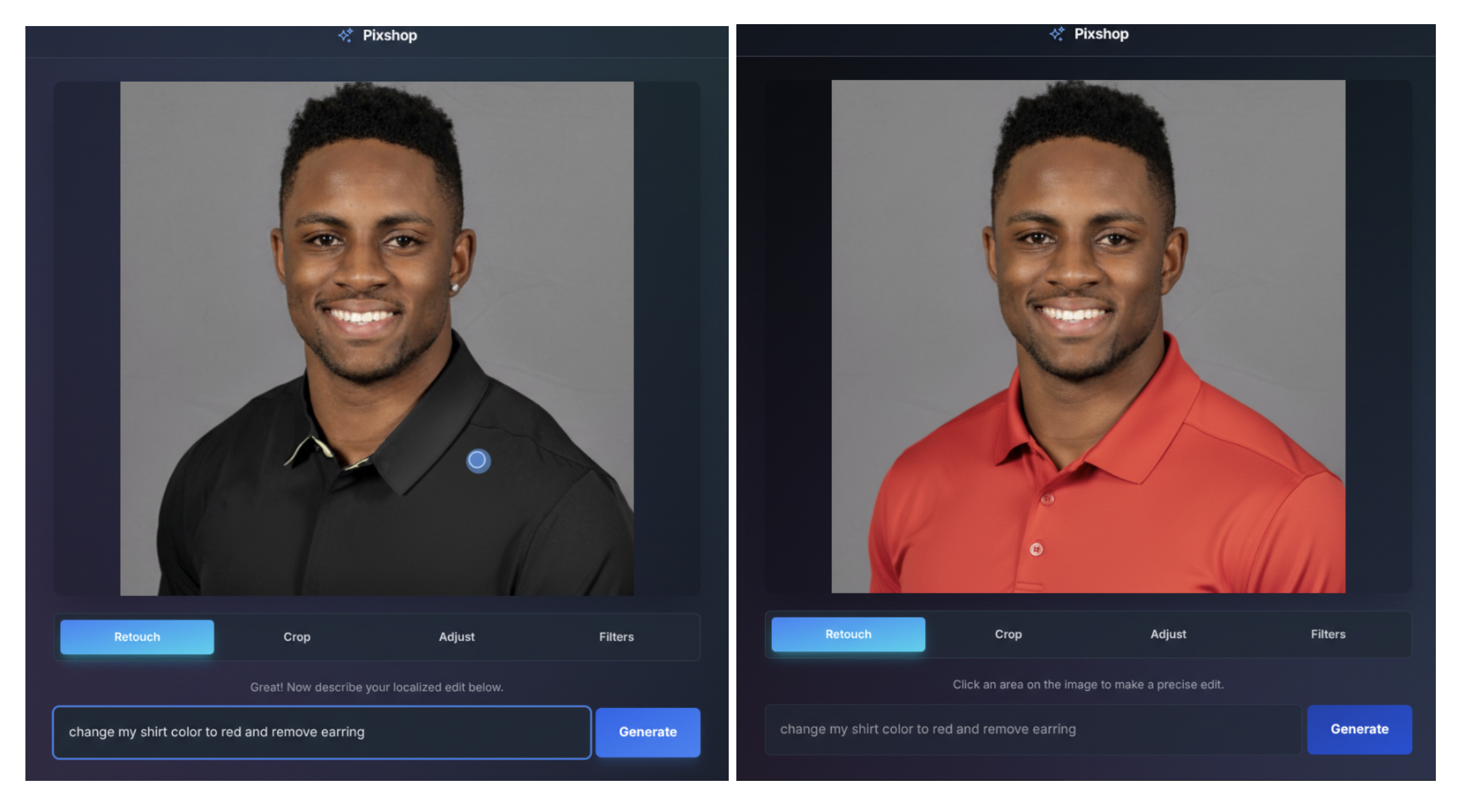
基于自然语言描述的图像编辑。
例如,该模型可以模糊图像背景、去除 T 恤上的污渍、从照片中移除整个人、改变主体的姿势、为黑白照片添加色彩,或实现任何通过简单提示能想到的效果。
强大的世界知识。
一般的图像生成模型在美学图像方面表现出色,但缺乏对现实世界的深度语义理解。Gemini 2.5 Flash Image 受益于 Gemini 的世界知识,解锁了新的应用场景。比如理解手绘图表、帮助解答现实世界问题以及单步执行复杂编辑指令的能力。
多图像融合
它能理解和融合多个输入图像。你可以将物体放入场景中,用配色方案或纹理重新设计房间,并通过单个提示融合图像。
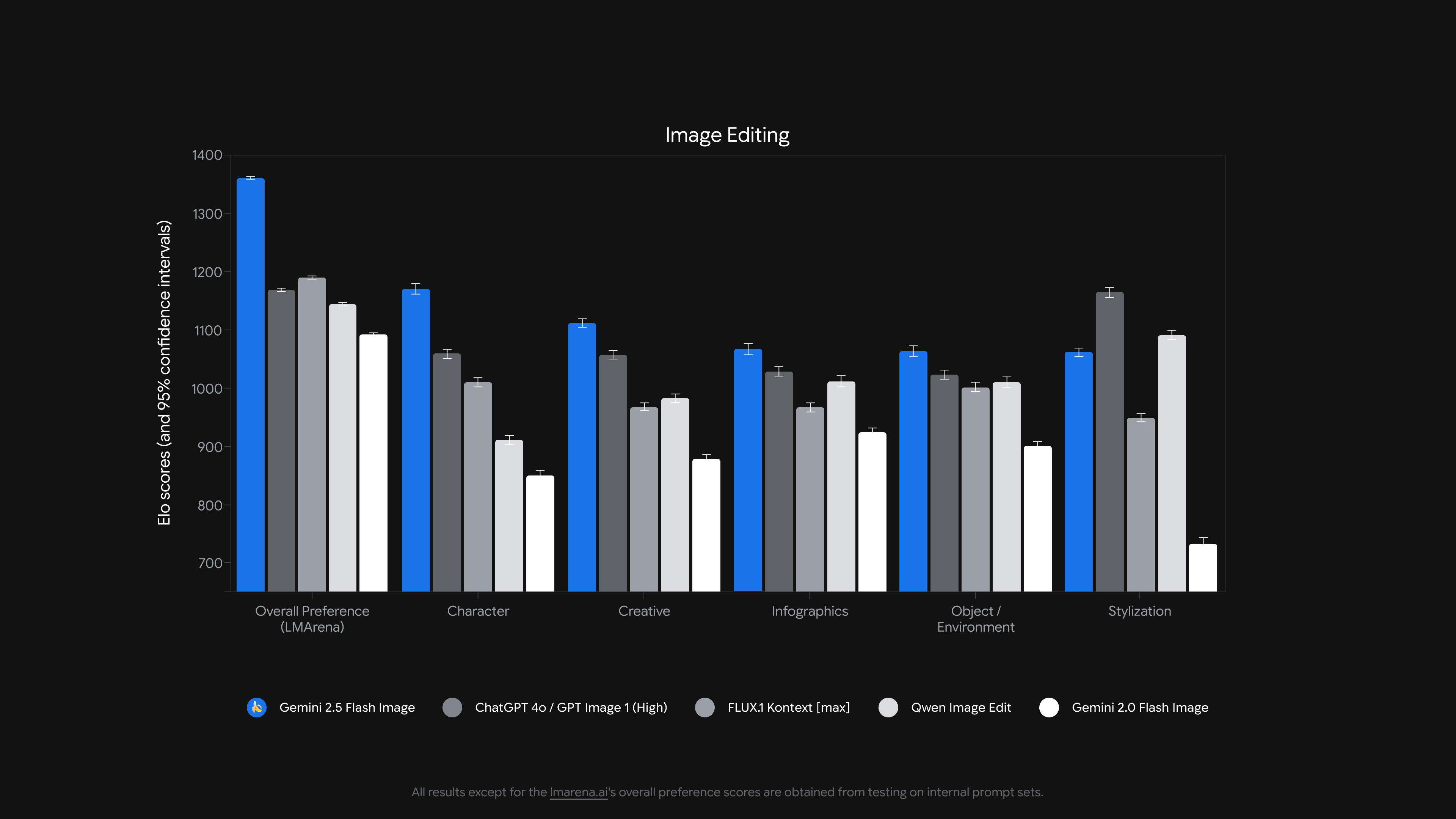
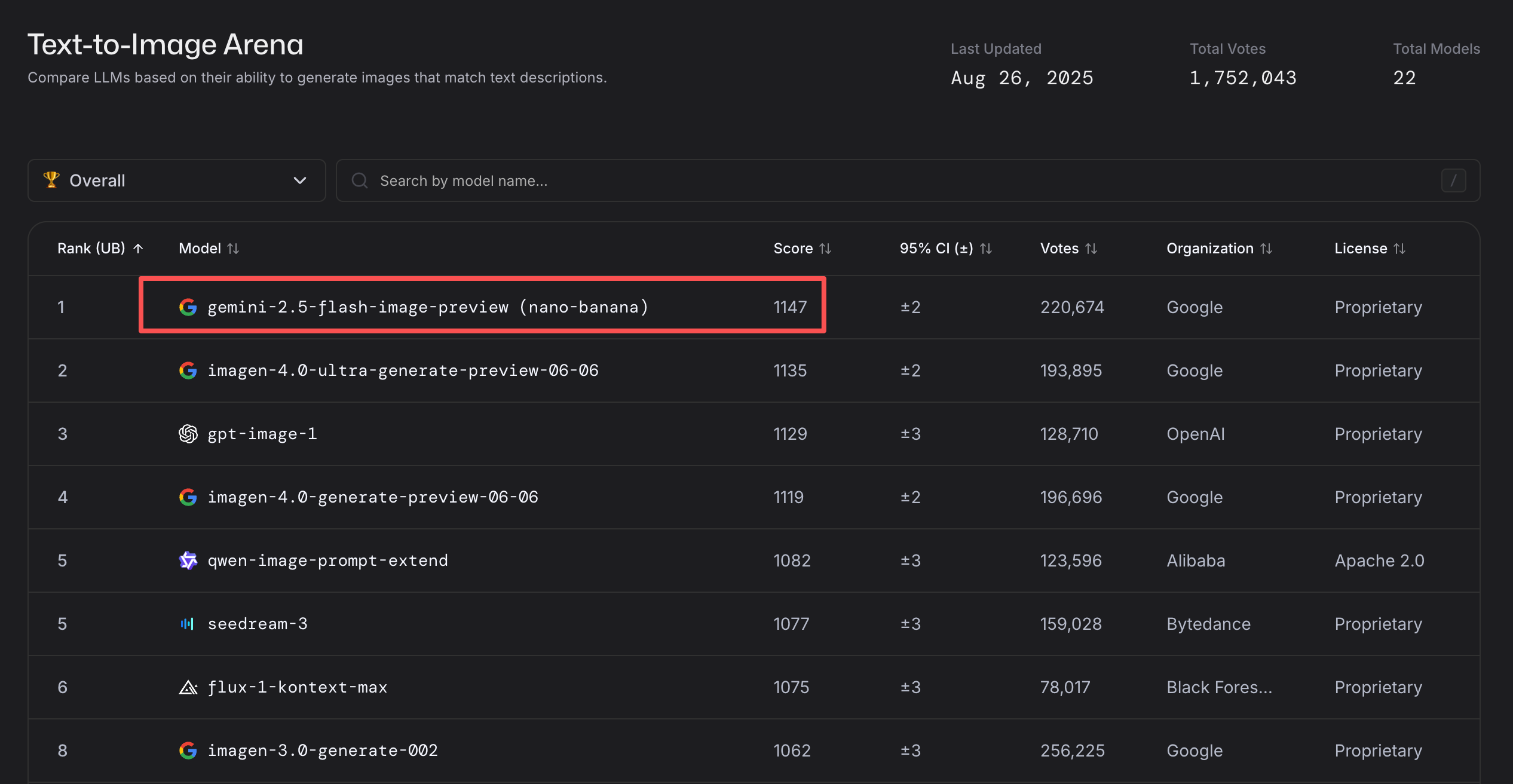
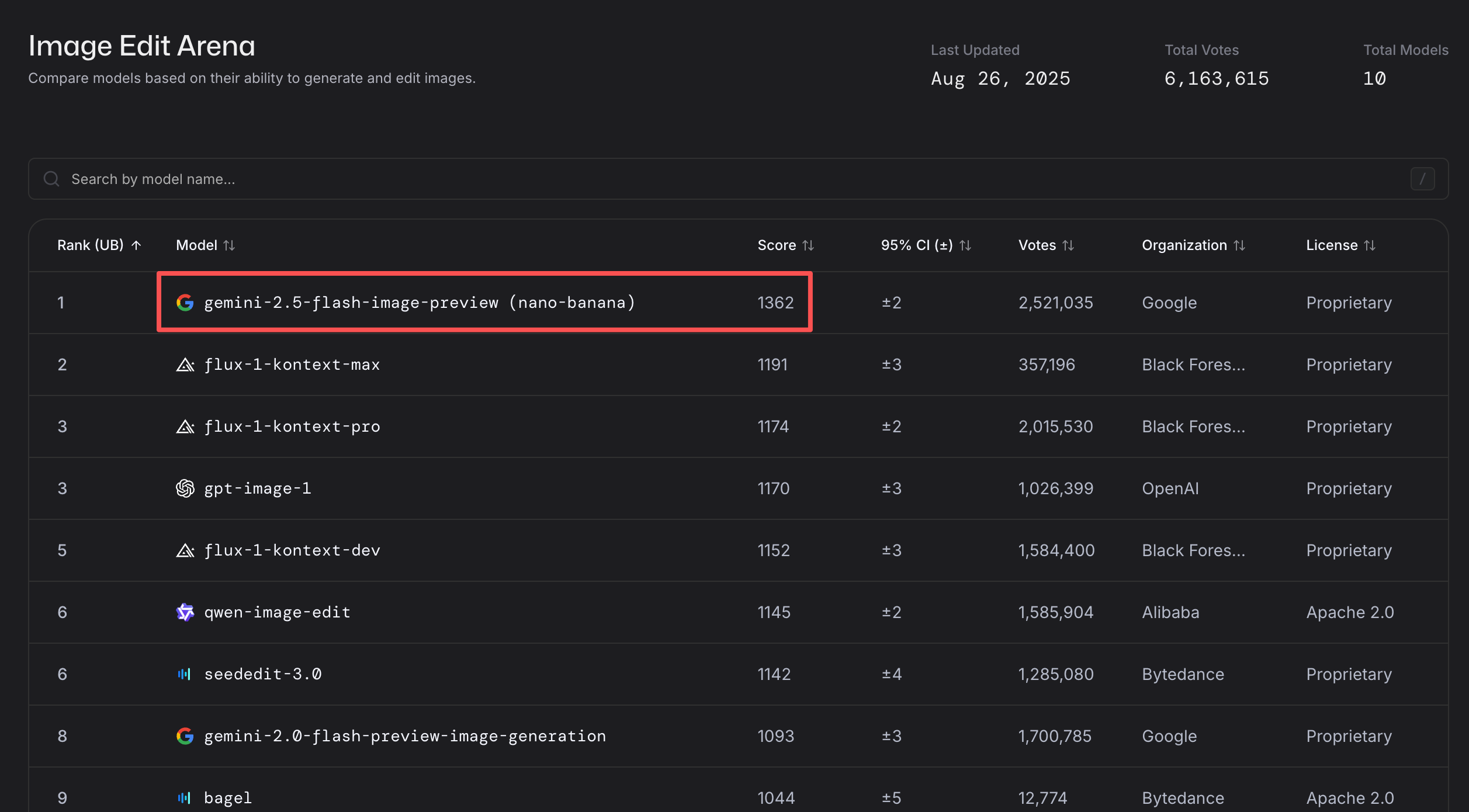
指标表现
目前 Gemini 2.5 Flash Image 基本霸榜图像编辑和生成模型的榜单了,特别是图像编辑领域更是大幅领先。
价格
文本价格(百万 token):输入 $0.3,输出 $2.5 图像生成价格(百万 token):输入 $0.3,输出 $30
输出图片的最大尺寸为 1024x1024 像素。
如果换算成一张图的话,大概一张图 3 毛钱左右。
体验地址
- Google AI Studio,右上角选择模型为:Gemini 2.5 Flash Image Preview
- Gemini,选择图片模式
- OpenRouter,选择 Google: Gemini 2.5 Flash Image Preview 或者 Google: Gemini 2.5 Flash Image Preview (free)。前者是收费的,后者是免费的。
玩法与教程
讲解完以上基本信息之后,让我们来点干货,实操一下 nano banana 的真实水平吧。
漫画上色
输入
Prompt:帮我给这个漫画自动上色

输出

修改图中细节
输入
Prompt:让图中的这个女孩的头发变成自然卷,衣服变成红色中国旗袍,牛排变成肘子,叉子上的香蕉变成苹果

输出

变换场景和衣服
输入
Prompt:让图中的人物的背景变成大海和沙滩,身上的白色 T 恤变成黄色,头上带一个墨镜

输出

扩图
这个扩图需要把先把原图放到一个指定长宽的图片中,剩余的部分用黑色来填充,之后就可以上传这张新图来实现原图的扩图了,nano banana 会把纯色的部分自动基于原图中的内容进行填充,一致性非常高。
输入
Prompt:填充上黑色区域的内容,自然扩展

输出

换衣服换鞋等场景
在这个场景中,你可以指定将图中的衣服/鞋子/配饰等穿到另一张图中的人物或模特身上。
输入
Prompt:“让这个图中的女孩子,穿上第一张图中的从右边数第一只鞋子,并根据选中的这只鞋子生成对应的另一只鞋子,都穿到这个女孩子脚上”


输出

商品秀
输入
Prompt:让这个女孩拿着第二张的饮料做广告


输出

发型设计
输入
Prompt:给图片中的人物做9个不同的发型设计(人脸要向前),注意每个发型之间的区分度要大一些,并放到一张图中
输出

多张图的角色合成到一张图,并做新的动作
输入
Prompt:“让图中女孩一个温馨的家中抱着图中的小狗玩耍”


输出

图片中的人物或角色实体化
输入
Prompt:“将这张照片变成一个角色形象。在它后面,放置一个印有角色图像的盒子,以及一台屏幕上显示 Blender 建模过程的电脑。在盒子前面,添加一个圆形塑料底座,角色形象站在上面。如果可能的话,将场景设置在室内。”

输出

微信公众号封面修改
输入
Prompt:“图中顶部的白色文字改为 :“This is Fisherdaddy”。

输出

恢复旧照片
输入
Prompt:把这个老旧照片复原

输出
模糊图变高清
输入
Prompt:“把这张照片变得高清”

输出

动作模仿1
输入
Prompt:将前两张图中的角色按照第三张图中火柴人的动作生成一个激烈的打斗场景,注意用第一张图的角色替换红色的火柴人,用第二张图中的角色替换蓝色的火柴人


输出

动作模仿 2
输入
Prompt:参考第二张图中线图人物的姿势和动作,让第一张图中的人物摆出第二张图的姿势和动作。
输出

动作模仿3
输入
prompt:将后两张图中的角色按照第一张图的动作生成一张照片,注意用第二张图的角色替换图中的男生,用第三张图中的角色替换的女生。

输出

标注内容
nano banana 目前写汉字还不太行,所以需要用英文来输出文字信息。
输入
Prompt:你是一个基于位置的 AR 体验生成器。在这张图片中突出显示有名建筑,并标注相关信息, in Enlish.

输出

变换视角1
输入
Prompt:画出红色标注的建筑的地面视图
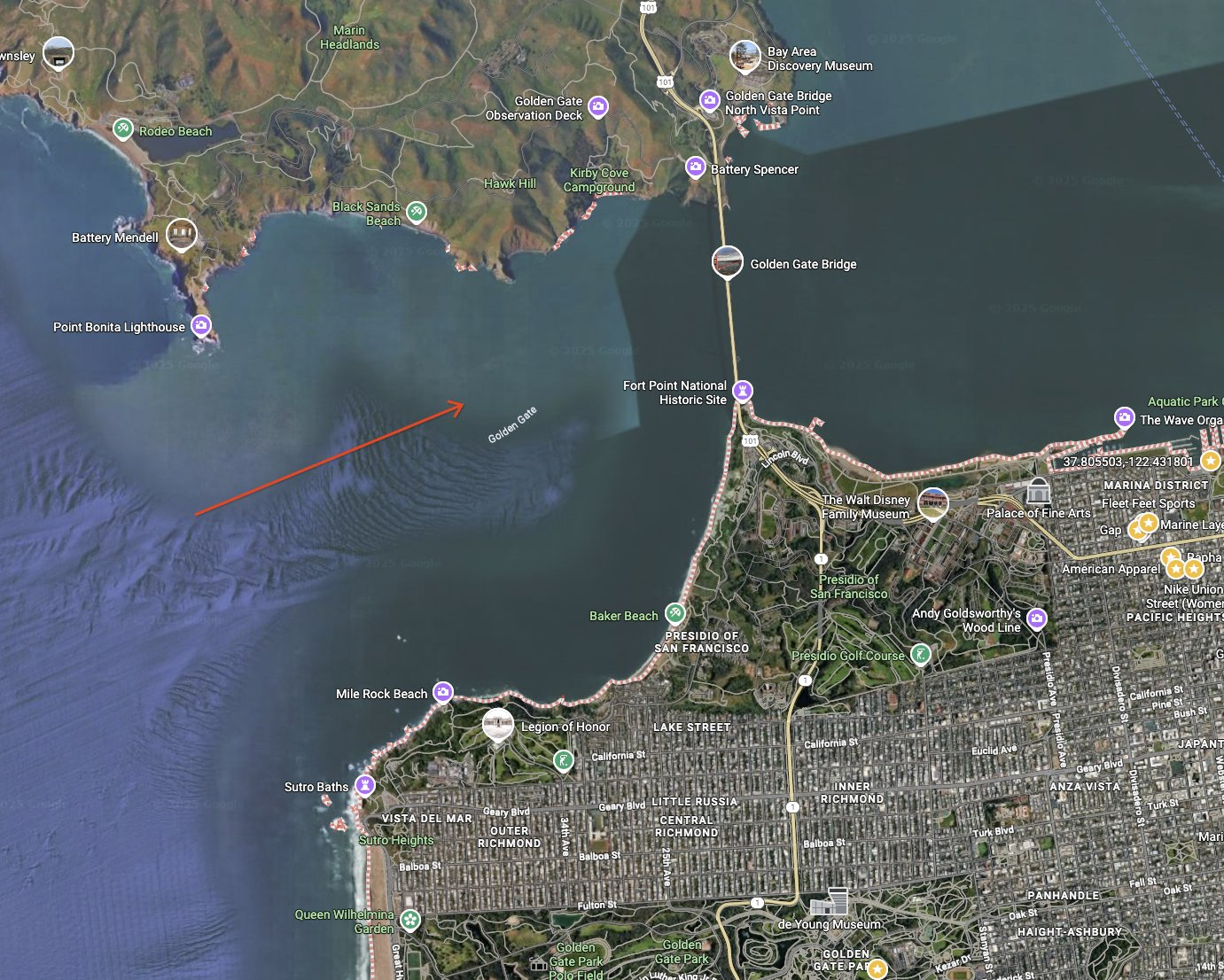
输出

变换视角2
输入
Prompt:把这张照片的拍摄视角改为正对男孩

输出

不同年代的风格图
输入
Prompt:把图中的人物放到 70 年代
输出

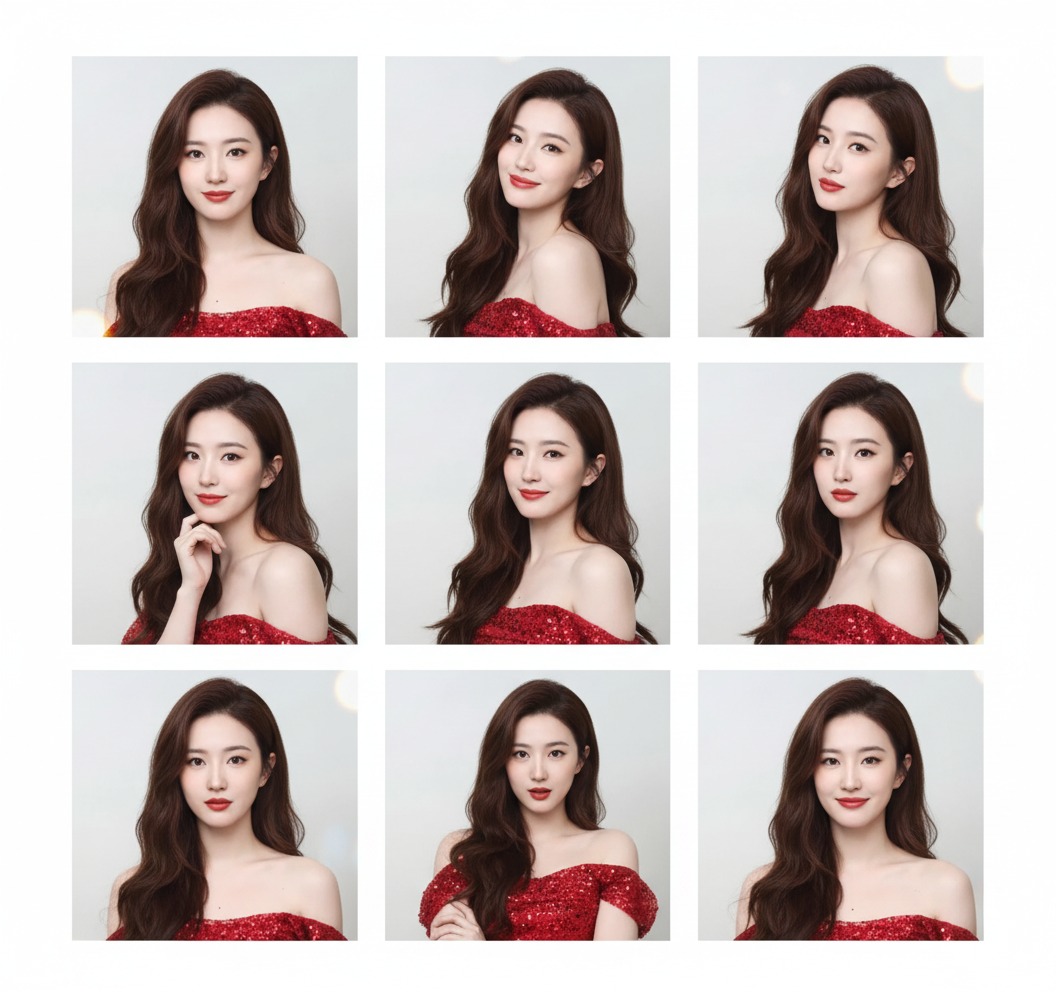
自拍九宫格
输入
Prompt:用这张图中的人物,做一个 3x3 的 九宫格的 photo booth grid 图,要是用不同的姿势和表情

输出
动漫人物 COSPlay
输入
Prompt:“生成一张真人扮演这张插画的照片,背景设置为Comiket。”
输出

众多人群中远景人物还原
输入
Prompt:“把图中红色标记的人物精确的还原出来,并生成一张该人物的完整照片”

输出

证件照
尺寸可能不一定对,但效果还是不错的。
输入
prompt:“截取图片人像头部,帮我做成2寸证件照,要求: 1、白底 2、职业正装 3、正脸 4、微笑”
输出

教育场景1
输入
Prompt:让图中的这些动物在农场里玩耍

输出

教育场景2
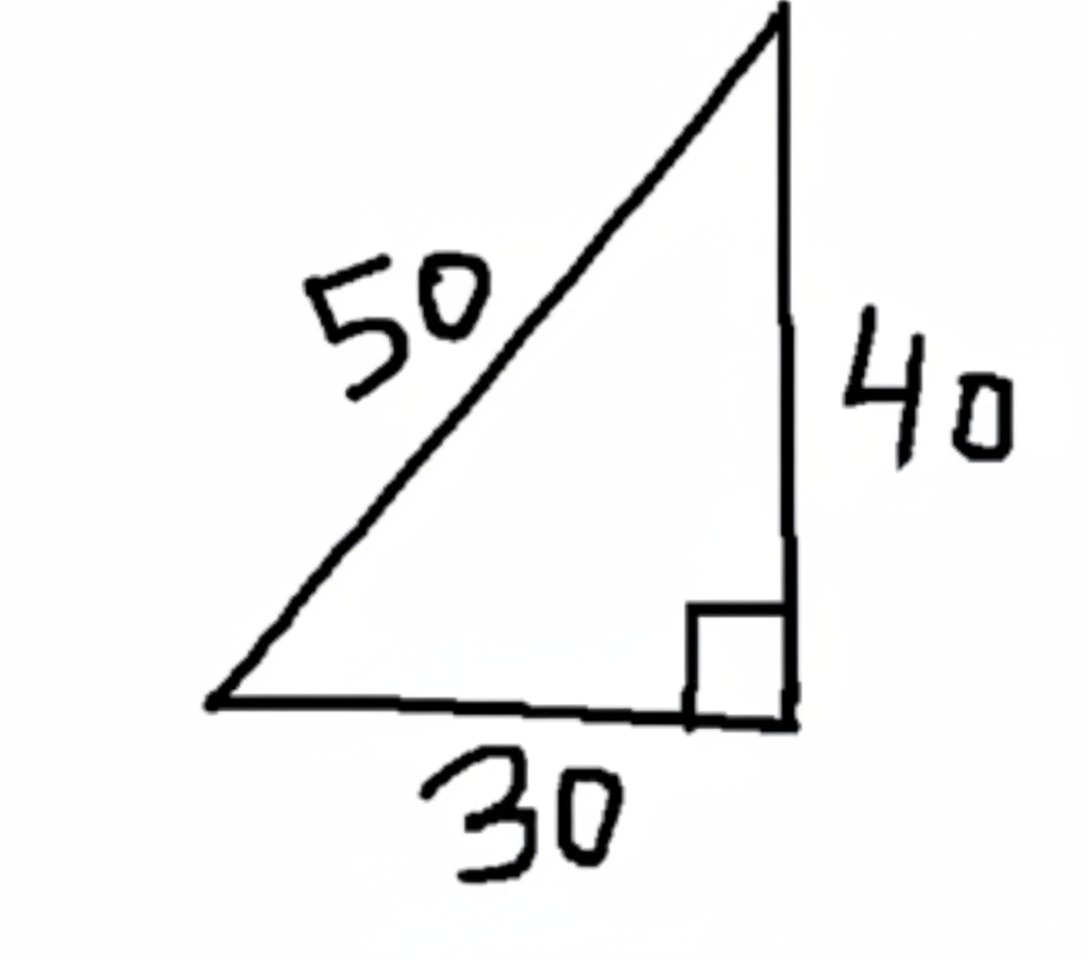
输入
Prompt:求解图中 x 的值,并更新到原图中
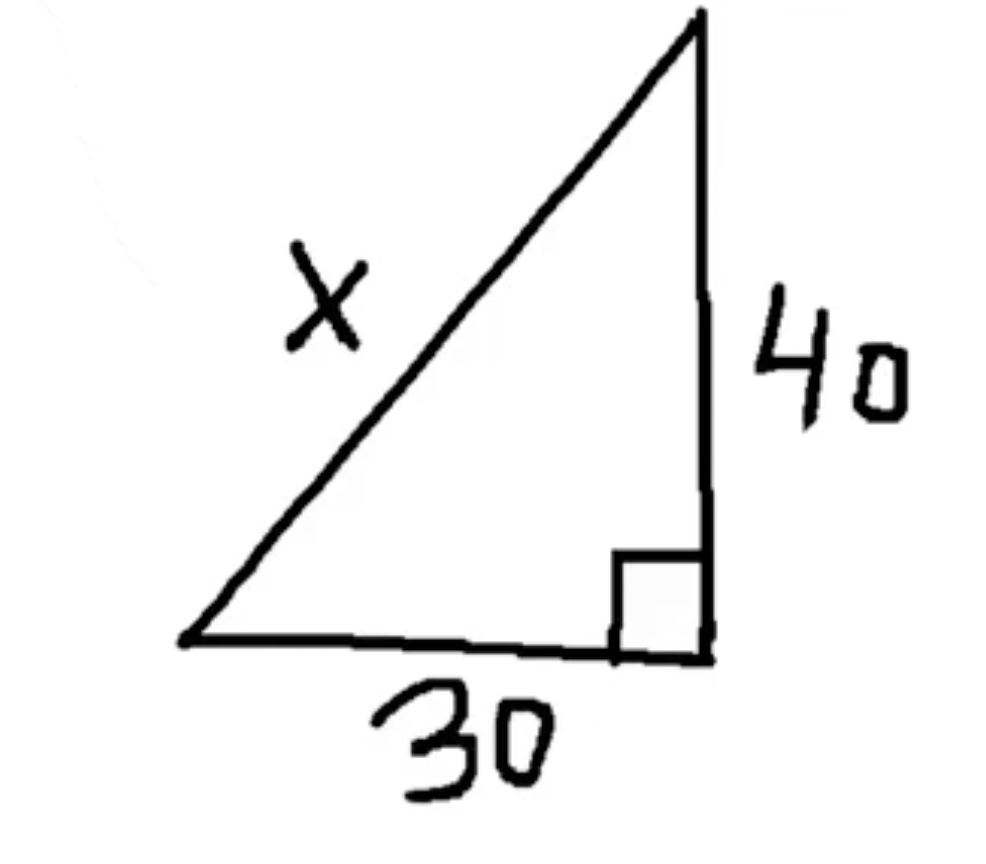
输出