OpenAI 于 2025年 4 月 15 日推出了 GPT-4.1 系列 API 模型:GPT-4.1、mini 及 nano。相较于 GPT-4o 和 GPT-4o mini,这些模型在各方面都实现了超越,尤其在代码生成和指令执行上的提升尤为显著。不仅如此,它们还拥有更大的上下文窗口,最多可处理 100 万个 Token,并能凭借更出色的长文本理解能力,充分利用这些上下文信息。同时,它们的知识库也已更新至 2024 年 6 月。
- 新模型发布: OpenAI 推出了
GPT-4.1、GPT-4.1 mini和GPT-4.1 nano三款 API 专用模型。 - 性能提升: 新模型在编码、指令遵循和长文本理解能力上全面优于
GPT-4o和GPT-4o mini。 - 长文本支持: 所有新模型均支持高达
1 million tokens的上下文窗口,并提升了长文本理解的可靠性。 - 成本与效率: 新模型旨在以更低的成本和延迟提供更优的性能,特别是在
GPT-4.1 mini和nano版本上体现。 - 应用场景: 改进的性能使新模型更适用于构建复杂的
agent系统,处理如软件工程、文档分析和客户服务等任务。 - 模型可用性:
GPT-4.1系列模型仅通过API提供。ChatGPT中的GPT-4o已逐步整合相关改进。 - 模型弃用:
GPT-4.5 Preview将在July 14, 2025被弃用,开发者需迁移至GPT-4.1系列。
API 新秀:GPT-4.1 系列模型
全新 GPT 模型家族,在代码能力、指令执行、长文本处理上迎来重大升级,更有首款纳米级模型惊艳亮相!
今天,我们正式在 API 中推出三款新模型:GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano。相较于 GPT-4o 和 GPT-4o mini,这些模型在各方面都实现了超越,尤其在代码生成和指令执行上的提升尤为显著。不仅如此,它们还拥有更大的上下文窗口,最多可处理 100 万个 Token,并能凭借更出色的长文本理解能力,充分利用这些上下文信息。同时,它们的知识库也已更新至 2024 年 6 月。
GPT-4.1 在以下行业标准测试中表现突出:
- 代码能力:在 SWE-bench Verified 代码测试中,GPT-4.1 的得分高达 54.6%,相较于 GPT-4o 提升了 21.4 个百分点,比 GPT-4.5 更提升了 26.6 个百分点,堪称代码模型中的佼佼者。
- 指令执行:在 Scale 公司推出的 MultiChallenge 指令执行能力评估中,GPT-4.1 取得了 38.3% 的成绩,比 GPT-4o 提升了 10.5 个百分点。
- 长文本处理:在 Video-MME 多模态 (Multimodal) 长文本理解测试中,GPT-4.1 刷新了记录,在“长文本、无字幕”类别中斩获 72.0% 的高分,比 GPT-4o 提升了 6.7 个百分点。
当然,基准测试只是参考,我们更注重模型的实际应用价值。通过与开发者社区的紧密合作,我们得以针对他们的核心应用场景,对这些模型进行深度优化。
因此,GPT-4.1 系列模型能够以更低的成本,提供卓越的性能。在相同的延迟下,它们可以将性能推向新的高度。

GPT-4.1 mini 在小型模型中实现了巨大的飞跃,在许多基准测试中甚至超越了 GPT-4o。在智能评估方面,它与 GPT-4o 并驾齐驱,同时延迟降低近一半,成本更是锐减 83%。
对于那些追求低延迟的应用场景,GPT-4.1 nano 无疑是最佳选择,它拥有我们目前最快、最经济的特性。虽然模型体积小巧,但性能却毫不逊色,凭借 100 万 Token 的上下文窗口,在 MMLU 测试中取得了 80.1% 的佳绩,GPQA 测试中也获得了 50.3% 的分数,Aider polyglot 代码测试更是高达 9.8%,甚至超越了 GPT-4o mini。分类、自动补全等任务,它都能轻松胜任。
指令执行可靠性和长文本理解能力的提升,也使得 GPT-4.1 系列模型在驱动 AI 智能体 (AI Agent) 方面表现更加出色。AI 智能体是一种可以代表用户自主完成任务的系统。结合 Responses API 等工具,开发者可以构建更实用、更可靠的 AI 智能体,应用于实际的软件工程、大型文档信息提取、客户服务等复杂场景。
请注意,GPT-4.1 仅通过 API 提供。在 ChatGPT 中,指令执行、代码能力和智能水平的提升已逐步应用于 GPT-4o 的最新版本,未来我们还将持续优化。
我们将逐步停止 API 中 GPT-4.5 Preview 的服务,因为 GPT-4.1 在关键能力上已经实现了超越或与之匹敌,但成本和延迟却大幅降低。GPT-4.5 Preview 将于 2025 年 7 月 14 日正式关闭,开发者们请尽快完成过渡。GPT-4.5 最初是作为研究预览版推出,旨在探索和试验大型计算密集型模型,我们从开发者的反馈中获益良多。未来,我们将继续把 GPT-4.5 备受赞赏的创造力、写作质量、幽默感和细节把握融入到新的 API 模型中。
接下来,我们将深入分析 GPT-4.1 在各项基准测试中的表现,并分享来自 Windsurf、Qodo、Hex、Blue J、Thomson Reuters 和 Carlyle 等 Alpha 测试伙伴的案例,展示它在实际生产环境中的卓越能力。
代码能力
在各种代码任务中,GPT-4.1 都展现出优于 GPT-4o 的强大实力,包括以 AI 智能体的方式解决代码问题、前端开发、减少不必要的修改、准确遵循 diff 格式、确保工具使用的一致性等等。
在 SWE-bench Verified 测试中,GPT-4.1 成功完成了 54.6% 的任务,而 GPT-4o(2024-11-20)的完成率为 33.2%。SWE-bench Verified 是一项衡量实际软件工程技能的测试。这一数据反映出,GPT-4.1 在代码仓库浏览、任务完成和代码生成方面的能力均有提升,它生成的代码不仅可以成功运行,还能通过各项测试。
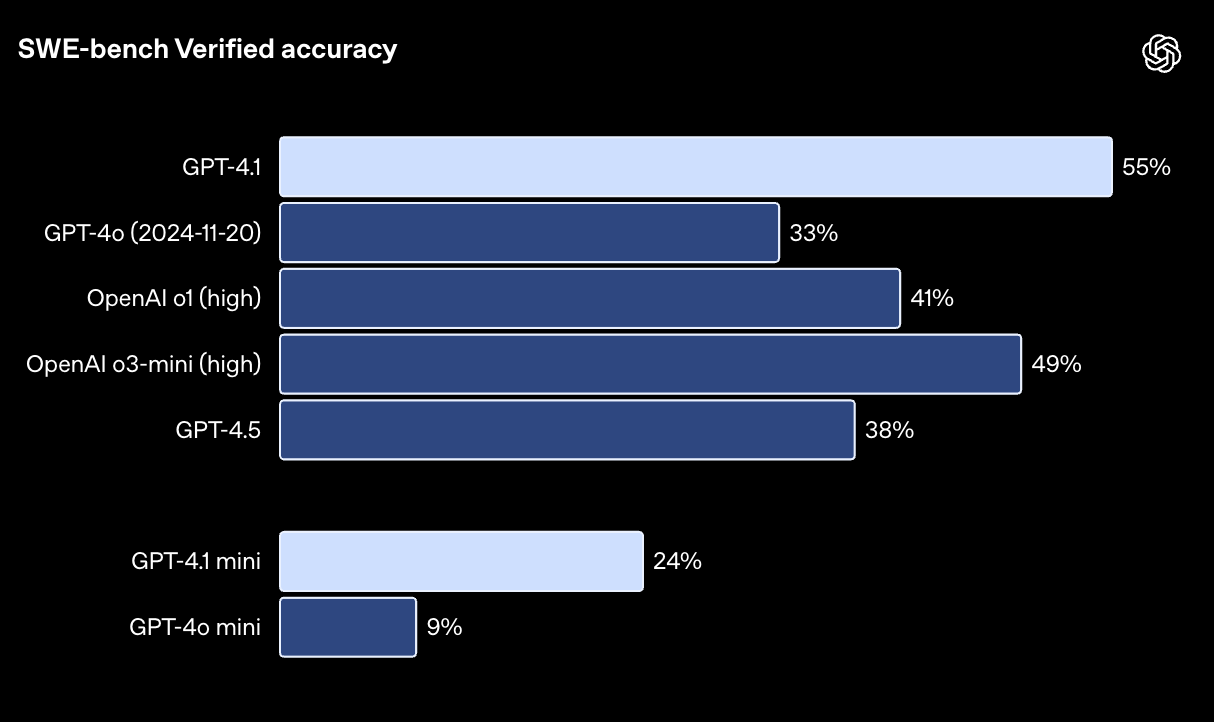
SWE-bench Verified 测试旨在评估模型解决实际软件问题的能力。测试中,模型会收到一个代码仓库和一个问题描述,它需要生成一个补丁来解决该问题。模型的性能高度依赖于所使用的提示语 (Prompt) 和工具。为了方便大家重现和理解我们的测试结果,请参考我们的 GPT-4.1 设置指南:链接。由于有 23 个问题的解决方案无法在我们的基础设施上运行,因此我们从 500 个问题中将其移除。如果保守地将这些问题的得分记为 0,那么 GPT-4.1 的得分将从 54.6% 降至 52.1%。
对于需要编辑大型文件的 API 开发者来说,GPT-4.1 在处理各种格式的代码差异时更加可靠。在 Aider 的 polyglot diff 基准测试中,GPT-4.1 的得分是 GPT-4o 的两倍以上,甚至比 GPT-4.5 高出 8 个百分点。这项测试不仅考察了模型在各种编程语言中的编码能力,还评估了模型生成完整代码和差异代码的能力。我们对 GPT-4.1 进行了专门训练,使其能够更准确地遵循差异格式,从而帮助开发者节省成本并降低延迟——模型只需输出修改过的代码行,而无需重写整个文件。如需获得最佳的代码差异性能,请参阅我们的提示指南:链接。对于偏爱重写整个文件的开发者,我们将 GPT-4.1 的输出 Token 限制增加到了 32,768 个(GPT-4o 为 16,384 个)。此外,我们还建议使用 Predicted Outputs 来减少完整文件重写的延迟:链接。
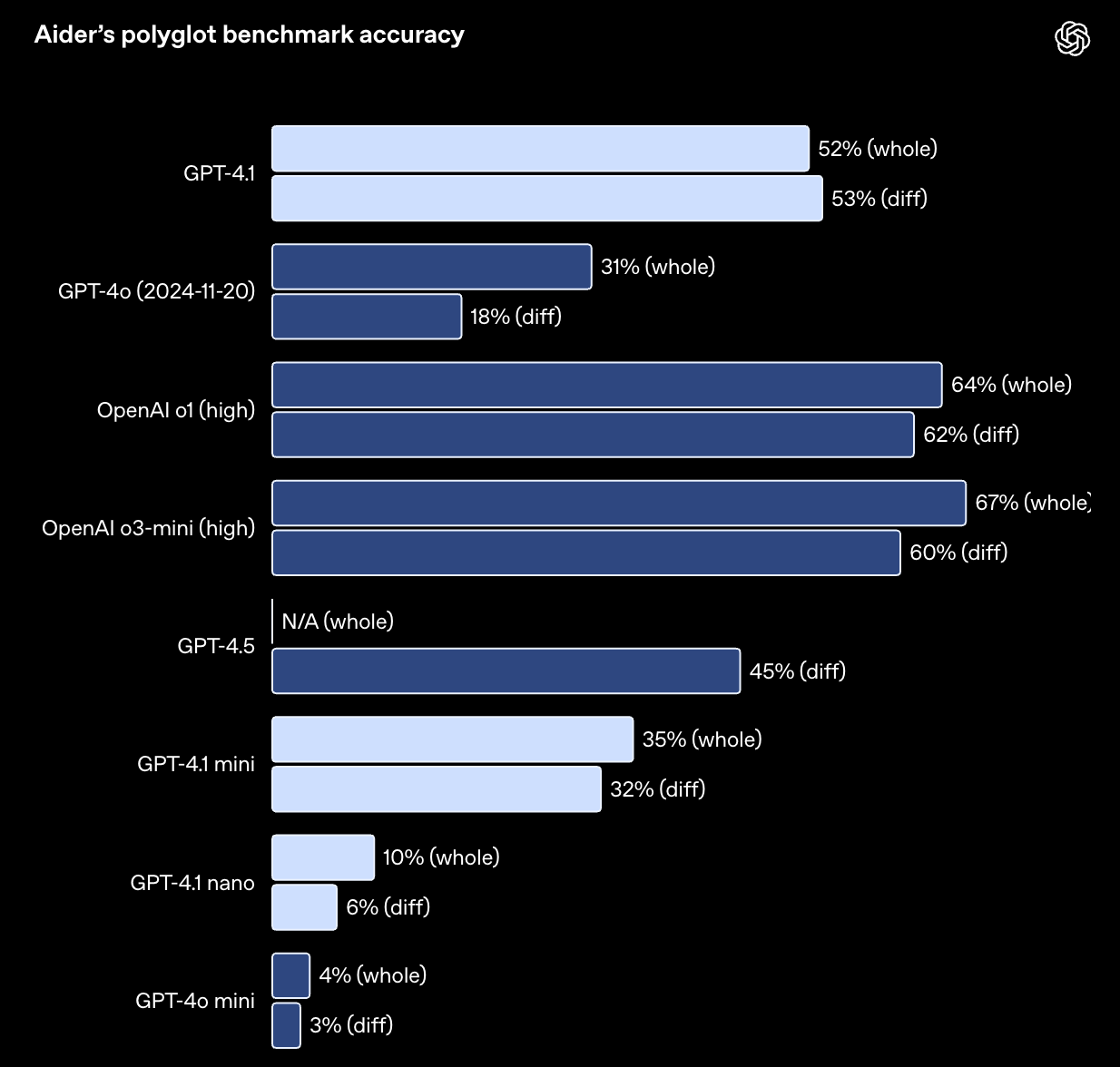
在 Aider 的 polyglot 基准测试中,模型通过编辑源文件来解决 Exercism 上的编码练习,并允许进行一次重试。“整体”格式要求模型重写整个文件,这种方式速度较慢且成本较高。“差异”格式则要求模型编写一系列 search/replace 代码块:链接。
GPT-4.1 在前端编码方面的表现也远超 GPT-4o,能够创建功能更强大、界面更美观的 Web 应用。在我们的对比测试中,80% 的付费人工评分员更喜欢 GPT-4.1 生成的网站。
提示语 (Prompt): 创建一个闪卡 Web 应用。用户应该能够创建闪卡、搜索现有闪卡、复习闪卡,并查看复习统计数据。预加载十张卡片,内容为印地语单词或短语及其英文翻译。复习界面:在复习界面中,点击或按空格键应以平滑的 3D 动画翻转卡片,显示翻译。按箭头键应在卡片之间导航。搜索界面:搜索栏应在用户键入查询时动态提供结果列表。统计界面:统计页面应显示用户已复习的卡片数量图表,以及他们答对的百分比。创建卡片界面:创建卡片页面应允许用户指定闪卡的正面和背面,并将其添加到用户的收藏中。所有这些界面都应该可以在侧边栏中访问。生成一个单页 React 应用(将所有样式内联)。
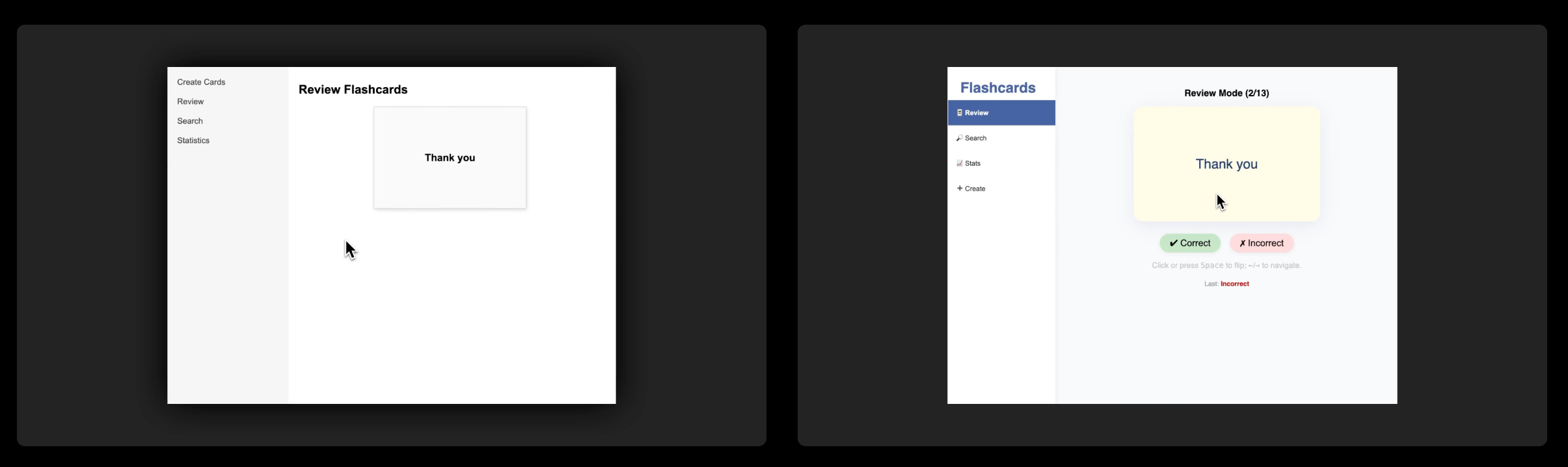
除了上述基准测试之外,GPT-4.1 在格式遵循的可靠性和减少不必要的编辑方面也表现更佳。在我们的内部评估中,GPT-4.1 生成的代码中不必要的编辑从 GPT-4o 的 9% 降至 2%。
真实世界案例
Windsurf : 在 Windsurf 的内部代码测试中,GPT-4.1 的得分比 GPT-4o 高出 60%,这与代码更改在首次审查中被接受的频率密切相关。他们的用户反馈称,GPT-4.1 在工具调用方面的效率提高了 30%,重复不必要的编辑或以过于狭窄、递增的步骤读取代码的可能性降低了约 50%。这些改进转化为工程团队更快的迭代和更顺畅的工作流程。
Qodo : Qodo 采用了一种受其微调基准测试启发的方法,对 GPT-4.1 与其他领先模型进行了对比测试,旨在从 GitHub pull request 生成高质量的代码审查。在 200 个具有相同提示语 (Prompt) 和条件的真实 pull request 中,他们发现 GPT-4.1 在 55% 的情况下提出了更合理的建议:链接。值得一提的是,他们发现 GPT-4.1 在精确性(知道何时不提出建议)和全面性(在必要时提供透彻的分析)方面都表现出色,并且能够始终专注于真正关键的问题。
指令执行
GPT-4.1 在执行指令时更加可靠,我们在各项指令执行评估中都观察到了显著的改进。
我们建立了一套内部指令执行评估体系,旨在从多个维度跟踪模型在几个关键指令执行类别中的性能,包括:
- 格式遵循: 提供指令,指定模型响应的自定义格式,例如 XML、YAML、Markdown 等。
- 否定指令: 指定模型应避免的行为(例如:“不要要求用户联系客服”)。
- 排序指令: 提供一组模型必须按照特定顺序执行的指令(例如:“首先询问用户的姓名,然后询问他们的电子邮件地址”)。
- 内容要求: 输出包含特定信息的内容(例如:“在编写营养计划时,务必注明蛋白质含量”)。
- 排序: 按照特定方式对输出结果进行排序(例如:“按人口数量对结果进行排序”)。
- 避免过度自信: 如果请求的信息不可用,或者请求不属于指定类别,则指示模型回答“我不知道”或类似内容(例如:“如果您不知道答案,请提供客服联系方式”)。
这些类别是根据开发者反馈而设定的,他们认为这些指令执行方面的能力与他们的实际应用最为相关。在每个类别中,我们都设置了简单、中等和困难三个等级的提示语 (Prompt)。GPT-4.1 在困难级别的提示语 (Prompt) 上比 GPT-4o 取得了显著进步。

我们的内部指令执行评估基于真实的开发者用例和反馈,涵盖了不同复杂程度的任务,以及关于格式、详细程度、长度等方面的指令。
多轮对话中的指令执行能力对许多开发者来说至关重要——模型需要能够在对话的深层保持连贯性,并记住用户之前说过的内容。我们对 GPT-4.1 进行了训练,使其能够更好地从对话历史中提取信息,从而实现更自然的对话。Scale 公司的 MultiChallenge 基准测试可以有效地衡量这种能力,GPT-4.1 的得分比 GPT-4o 高出了 10.5 个百分点。
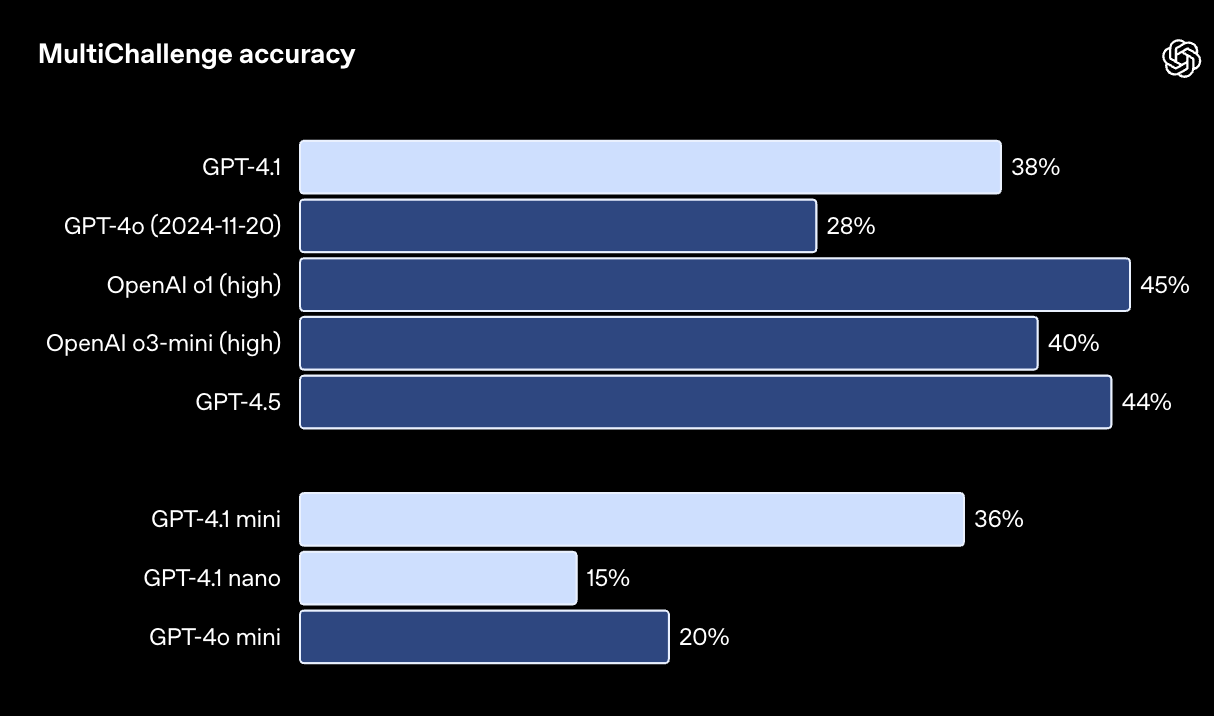
在 MultiChallenge 测试中,模型需要在多轮对话中正确运用来自先前 Messages 的四种类型的信息:链接。
GPT-4.1 在 IFEval 测试中的得分也达到了 87.4%,而 GPT-4o 的得分为 81.0%。IFEval 使用带有可验证指令的提示语 (Prompt)(例如,指定内容长度或避免使用某些术语或格式)。

在 IFEval 测试中,模型必须生成符合各种指令的答案:链接。
更出色的指令执行能力使现有应用更加可靠,并为之前受限于可靠性的新应用提供了可能。早期测试者指出,GPT-4.1 可能会过于 literal,因此我们建议在提示语 (Prompt) 中尽可能明确和具体。如需了解更多关于 GPT-4.1 提示语 (Prompt) 的最佳实践,请参阅提示指南。
真实世界案例
Blue J : 在 Blue J 内部最复杂的真实税务场景基准测试中,GPT-4.1 的准确率比 GPT-4o 高出 53%。准确率的显著提升(对系统性能和用户满意度都至关重要)凸显了 GPT-4.1 对复杂法规的理解能力,以及在长上下文中遵循细微指令的能力。对于 Blue J 用户而言,这意味着更快、更可靠的税务研究,以及更多时间用于高价值的咨询工作。
Hex : GPT-4.1 在 Hex 最具挑战性的 SQL 评估集中实现了近 2 倍的改进:链接,展现出在指令执行和语义理解方面的显著提升。该模型在从大型、模糊的架构中选择正确的表方面更加可靠——这是一个直接影响整体准确性且难以通过单独提示语 (Prompt) 进行调整的上游决策点。对于 Hex 而言,这意味着手动调试的显著减少,以及生产级工作流程的加速实现。
长文本处理
GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano 能够处理多达 100 万个 Token 的上下文——远高于之前 GPT-4o 模型的 128,000 个 Token。100 万个 Token 相当于 8 个 React 代码库的总和,因此长文本处理非常适合处理大型代码库或海量文档。
我们对 GPT-4.1 进行了专门训练,使其能够可靠地处理 100 万 Token 上下文中的信息。与 GPT-4o 相比,它在识别相关文本和忽略干扰信息方面也更加出色,无论上下文长短。长文本理解能力是法律、编码、客户支持等领域应用的关键。
下图展示了 GPT-4.1 在上下文窗口中的不同位置检索隐藏信息(即“大海捞针”)的能力。结果表明,GPT-4.1 能够在所有位置和所有上下文长度(最高可达 100 万个 Token)中准确地找到目标信息。这意味着,无论相关信息在输入文本中的位置如何,它都能有效地提取出来。

在我们的内部“大海捞针”测试中,GPT-4.1、GPT-4.1 mini 和 GPT 4.1 nano 都能够在高达 100 万 Token 的上下文中检索到所有位置的目标信息。
然而,在现实世界中,很少有像“大海捞针”这样简单的任务。用户通常需要模型检索和理解多个信息片段,并理解它们之间的关系。为了更好地评估模型在这些方面的能力,我们开源了一项新的评估:OpenAI-MRCR(多轮共指消解)。
OpenAI-MRCR 旨在测试模型在上下文中查找和消除多个隐藏目标信息之间歧义的能力。该评估模拟了用户与助手之间的多轮对话,用户要求助手撰写关于某个主题的文章,例如“写一首关于貘的诗”或“写一篇关于岩石的博文”。然后,我们在上下文中插入两个、四个或八个相同的请求。模型需要做的就是检索与特定请求相对应的回复(例如,“给我第三首关于貘的诗”)。
这项任务的挑战在于,这些请求与上下文中的其他信息非常相似——模型很容易被细微的差别所迷惑,例如关于貘的短篇小说,而不是诗歌;或者是关于青蛙的诗歌,而不是关于貘的诗歌。测试结果表明,在上下文长度不超过 128,000 个 Token 的情况下,GPT-4.1 的性能优于 GPT-4o;即使上下文长度达到 100 万个 Token,它仍然可以保持出色的性能。
尽管如此,这项任务仍然非常具有挑战性,即使对于高级推理模型也是如此。为了鼓励大家共同探索长文本检索的未来,我们在此分享 OpenAI-MRCR 评估数据集:链接。



OpenAI-MRCR 测试旨在评估模型消除歧义的能力,它需要模型在包含干扰信息的上下文中,区分 2 个、4 个或 8 个用户提示:链接。
此外,我们还发布了 Graphwalks 数据集:链接,用于评估模型在多跳推理方面的能力。在长文本处理的许多开发者用例中,模型需要在上下文中进行多次逻辑跳转,例如在编写代码时在多个文件之间跳转,或者在回答复杂的法律问题时交叉引用文档。
理论上,模型(甚至是人类)可以通过对 Prompt 进行一次通读来解决 OpenAI-MRCR 问题,但 Graphwalks 旨在考察模型跨越上下文多个位置进行推理的能力,它无法通过顺序读取来解决。
Graphwalks 使用由十六进制哈希值构成的有向图来填充上下文窗口,然后要求模型从图中的随机节点开始执行广度优先搜索 (BFS),并返回特定深度的所有节点。GPT-4.1 在此基准测试中取得了 61.7% 的准确率,与 o1 模型持平,并轻松击败了 GPT-4o。
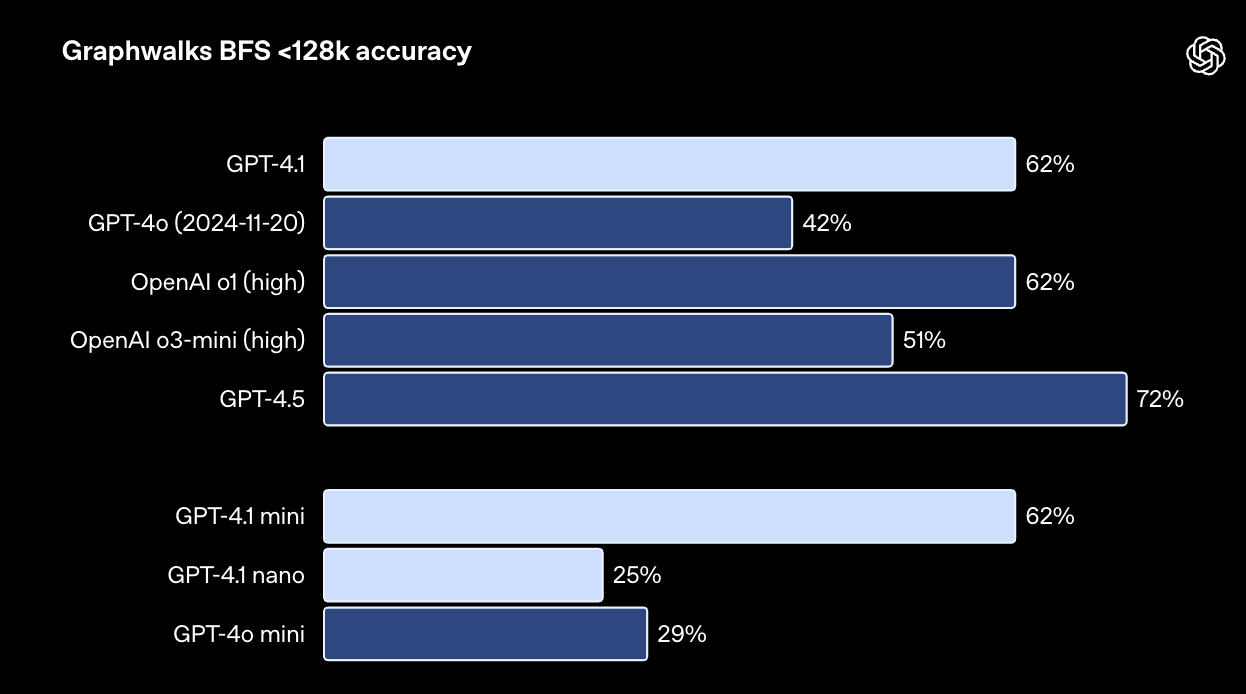
Graphwalks 测试旨在评估模型从大型图中的随机节点开始执行广度优先搜索的能力:链接。
仅仅依靠基准测试是不够的。为了更全面地评估 GPT-4.1 的性能,我们与 Alpha 测试伙伴展开合作,在他们的真实长文本处理任务中对其进行了测试。
真实世界案例
Thomson Reuters: Thomson Reuters 使用 CoCounsel(一款面向法律行业的专业 AI 助手)对 GPT-4.1 进行了测试。结果表明,在使用 GPT-4.1 处理内部长文本基准测试时,CoCounsel 的多文档审查准确率提高了 17%。这一提升充分证明了 CoCounsel 处理涉及多个冗长文档的复杂法律工作流程的能力。Thomson Reuters 发现,GPT-4.1 在跨来源维护上下文以及准确识别文档之间细微关系(例如冲突条款或补充说明)方面表现得非常可靠,而这些能力对法律分析和决策至关重要。
Carlyle : Carlyle 使用 GPT-4.1 从 PDF、Excel 文件等格式的多个冗长文档中准确地提取细粒度的财务数据。内部评估显示,GPT-4.1 在从包含密集数据的超大文档中提取信息时的性能提升了 50%,并且是首个成功克服其他模型所面临的关键限制的模型,这些限制包括“大海捞针”、中间信息丢失和跨文档的多跳推理。
除了模型性能和准确性之外,开发者还需要模型能够快速响应,以满足用户的需求。为此,我们对推理堆栈进行了改进,缩短了首个 Token 的生成时间。此外,借助 Prompt 缓存技术,您可以在节省成本的同时进一步降低延迟。在我们的初步测试中,对于包含 128,000 个 Token 的上下文,GPT-4.1 生成首个 Token 的时间约为 15 秒;对于包含 100 万个 Token 的上下文,则约为 1 分钟。GPT-4.1 mini 和 nano 的速度更快,例如,对于包含 128,000 个输入 Token 的查询,GPT-4.1 nano 通常可以在 5 秒内返回首个 Token。
视觉能力
GPT-4.1 系列模型在图像理解方面表现出色,其中 GPT-4.1 mini 的进步尤为显著,在图像基准测试中经常超越 GPT-4o。
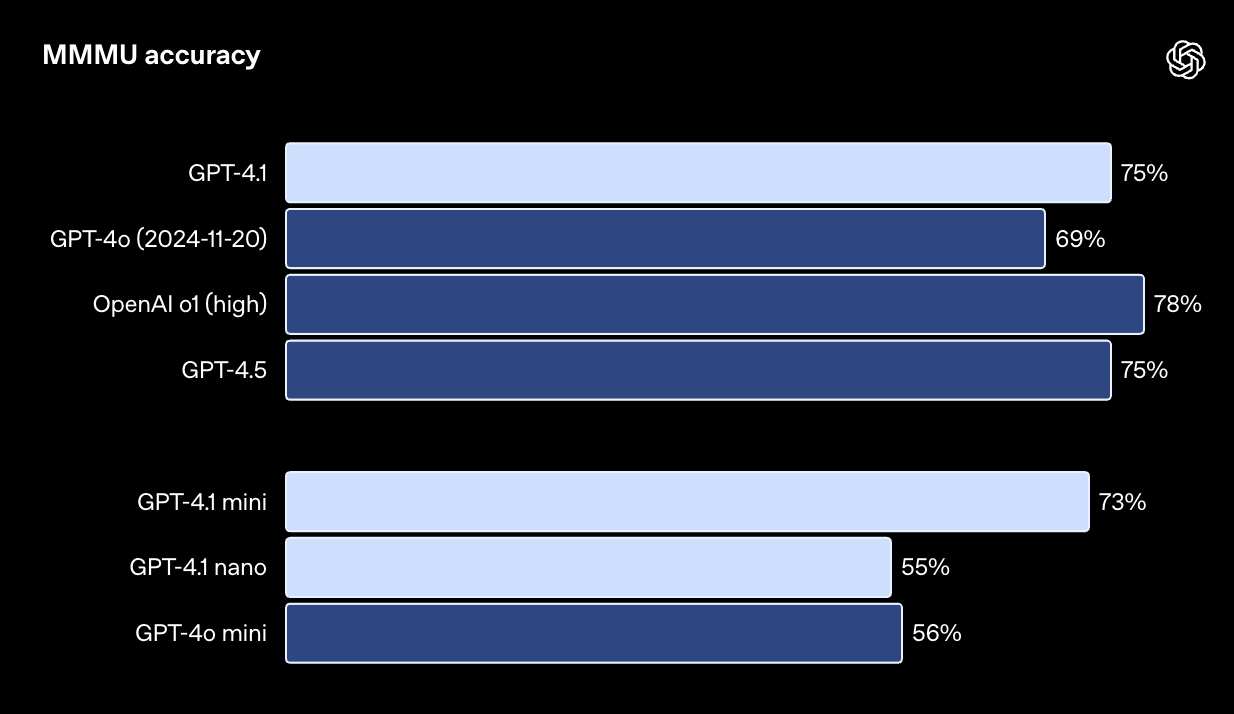
MMMU 测试旨在评估模型回答包含图表、示意图、地图等问题的能力。(注:即使不提供图像,许多答案仍然可以从上下文中推断或猜测。):链接
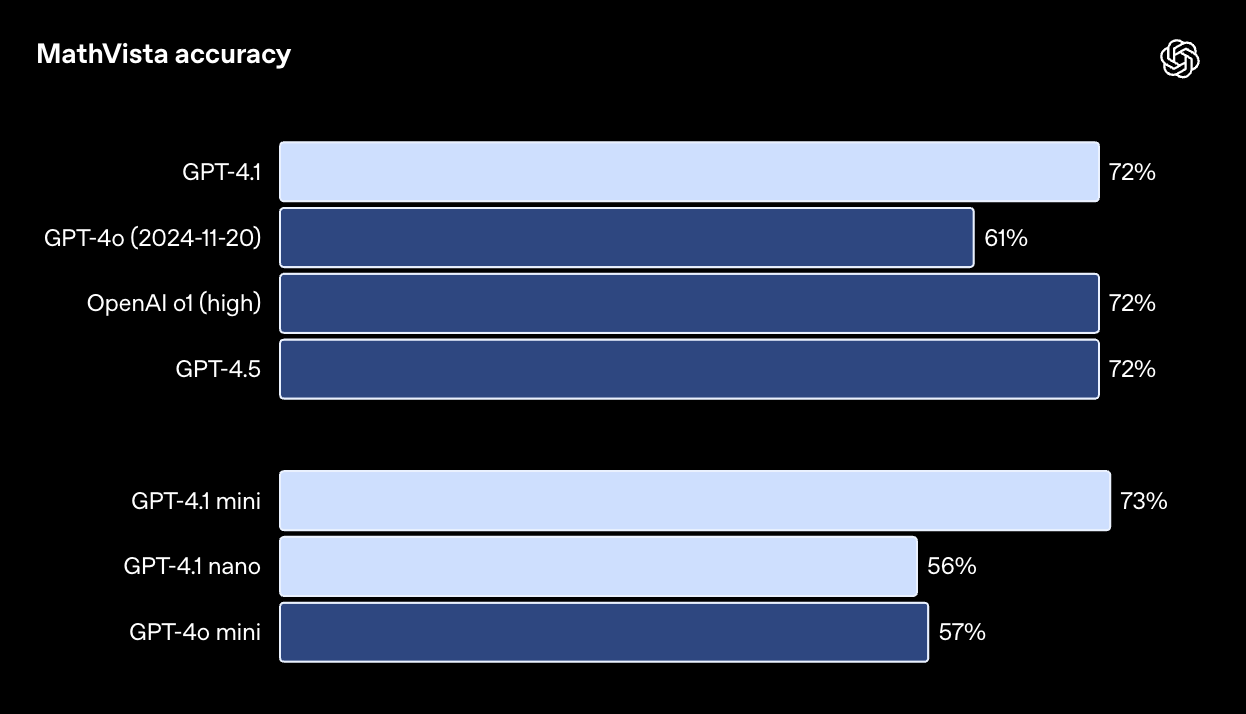
MathVista 测试旨在评估模型解决视觉数学问题的能力:链接
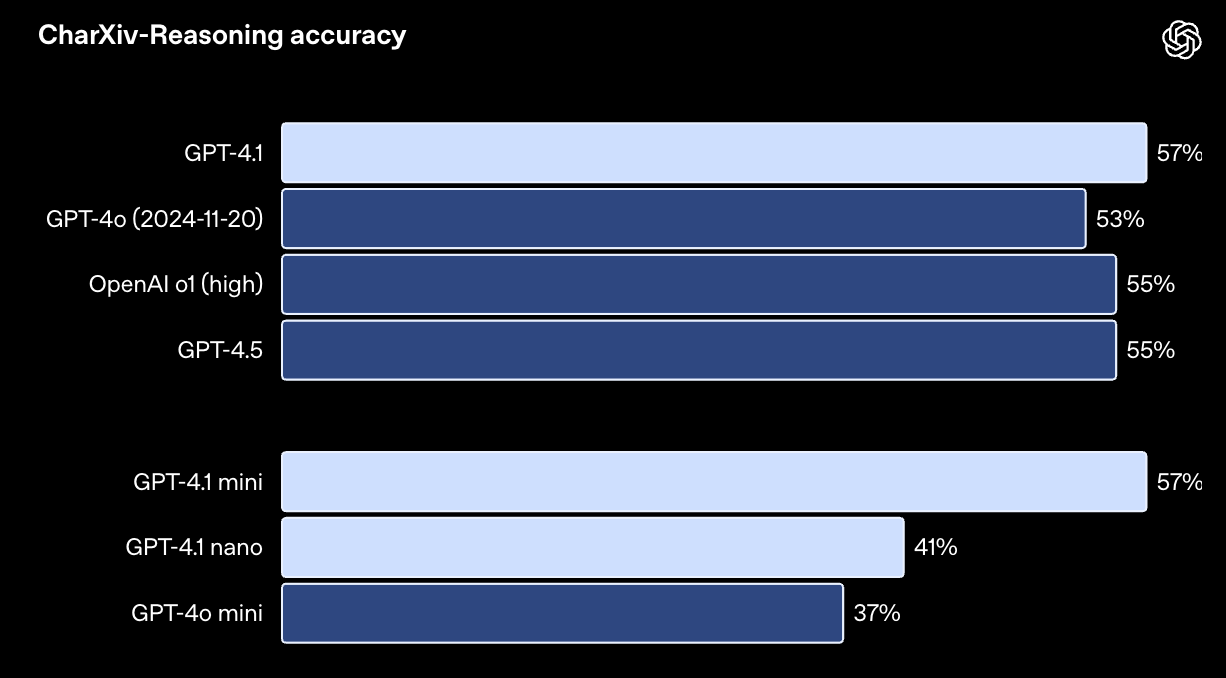
CharXiv-Reasoning 测试旨在评估模型回答关于科学论文中图表问题的能力:链接
长文本处理能力对于多模态 (Multimodal) 应用场景(如处理长视频)同样至关重要。在 Video-MME 测试(长视频、无字幕)中,模型需要根据 30-60 分钟的无字幕长视频来回答多项选择题。GPT-4.1 取得了领先的成绩,得分高达 72.0%,远高于 GPT-4o 的 65.3%。

Video-MME 测试旨在评估模型根据 30-60 分钟的无字幕长视频回答多项选择题的能力:链接
定价
GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano 现已面向所有开发者开放。
通过对推理系统进行效率优化,我们得以降低 GPT-4.1 系列模型的价格。对于中等规模的查询,GPT-4.1 的价格比 GPT-4o 便宜 26%,而 GPT-4.1 nano 则是我们有史以来最经济、最快速的模型。对于重复使用相同上下文的查询,我们将这些新模型的 Prompt 缓存折扣提高到了 75%(之前为 50%)。最后,长文本请求将按照标准的 Token 计费,不收取额外费用。
| 模型 (价格单位:每百万 Token) | 输入 | 缓存输入 | 输出 | 混合定价* |
| gpt-4.1 | $2.00 | $0.50 | $8.00 | $1.84 |
| gpt-4.1-mini | $0.40 | $0.10 | $1.60 | $0.42 |
| gpt-4.1-nano | $0.10 | $0.025 | $0.40 | $0.12 |
*基于典型的输入/输出和缓存比率。
您还可以通过 Batch API 使用这些模型,并享受 50% 的额外折扣:链接。
结论
GPT-4.1 是人工智能在实际应用中的一次重大飞跃。通过密切关注开发者的实际需求(从代码生成到指令执行,再到长文本理解),这些模型为构建智能系统和复杂的 AI 智能体应用开辟了新的可能性。我们衷心感谢开发者社区的无限创意,并期待着大家使用 GPT-4.1 创造出更多精彩的应用!
附录
以下是学术知识、代码能力、指令执行、长文本处理、视觉能力和函数调用等各项评估的完整结果列表。
学术知识
| 类别 | GPT-4.1 | GPT-4.1 mini | GPT-4.1 nano | GPT-4o (2024-11-20) | GPT-4o mini | OpenAI o1 (high) | OpenAI o3-mini (high) | GPT-4.5 |
|---|---|---|---|---|---|---|---|---|
| AIME ‘24 | 48.1% | 49.6% | 29.4% | 13.1% | 8.6% | 74.3% | 87.3% | 36.7% |
| GPQA Diamond1 | 66.3% | 65.0% | 50.3% | 46.0% | 40.2% | 75.7% | 77.2% | 69.5% |
| MMLU | 90.2% | 87.5% | 80.1% | 85.7% | 82.0% | 91.8% | 86.9% | 90.8% |
| Multilingual MMLU | 87.3% | 78.5% | 66.9% | 81.4% | 70.5% | 87.7% | 80.7% | 85.1% |
[1] 我们对 GPQA 的实现使用模型来提取答案,而不是正则表达式。对于 GPT-4.1,差异小于 1%(没有统计学意义);但对于 GPT-4o,模型提取显著提高了分数(约 46% -> 54%)。
代码能力评估
| 类别 | GPT-4.1 | GPT-4.1 mini | GPT-4.1 nano | GPT-4o (2024-11-20) | GPT-4o mini | OpenAI o1 (high) | OpenAI o3-mini (high) | GPT-4.5 |
|---|---|---|---|---|---|---|---|---|
| SWE-bench Verified2 | 54.6% | 23.6% | - | 33.2% | 8.7% | 41.0% | 49.3% | 38.0% |
| SWE-Lancer | $176K (35.1%) | $165K (33.0%) | $77K (15.3%) | $163K (32.6%) | $116K (23.1%) | $160K (32.1%) | $90K (18.0%) | $186K (37.3%) |
| SWE-Lancer (IC-Diamond subset) | $34K (14.4%) | $31K (13.1%) | $9K (3.7%) | $29K (12.4%) | $11K (4.8%) | $29K (9.7%) | $17K (7.4%) | $41K (17.4%) |
| Aider’s polyglot: whole | 51.6% | 34.7% | 9.8% | 30.7% | 3.6% | 64.6% | 66.7% | - |
| Aider’s polyglot: diff | 52.9% | 31.6% | 6.2% | 18.2% | 2.7% | 61.7% | 60.4% | 44.9% |
[2] 我们省略了 23/500 个无法在我们的基础设施上运行的问题。省略的 23 个任务的完整列表是“astropy__astropy-7606”、“astropy__astropy-8707”、“astropy__astropy-8872”、“django__django-10097”、“django__django-7530”、“matplotlib__matplotlib-20488”、“matplotlib__matplotlib-20676”、“matplotlib__matplotlib-20826”、“matplotlib__matplotlib-23299”、“matplotlib__matplotlib-24970”、“matplotlib__matplotlib-25479”、“matplotlib__matplotlib-26342”、“psf__requests-6028”、“pylint-dev__pylint-6528”、“pylint-dev__pylint-7080”、“pylint-dev__pylint-7277”、“pytest-dev__pytest-5262”、“pytest-dev__pytest-7521”、“scikit-learn__scikit-learn-12973”、“sphinx-doc__sphinx-10466”、“sphinx-doc__sphinx-7462”、“sphinx-doc__sphinx-8265”和“
直播视频
作者
研究负责人
Ananya Kumar, Jiahui Yu, John Hallman, Michelle Pokrass
核心研究人员
Adam Goucher, Adi Ganesh, Bowen Cheng, Brandon McKinzie, Brian Zhang, Chris Koch, Colin Wei, David Medina, Edmund Wong, Erin Kavanaugh, Florent Bekerman, Haitang Hu, Hongyu Ren, Ishaan Singal, Jamie Kiros, Jason Ai, Ji Lin, Jonathan Chien, Josh McGrath, Julian Lee, Julie Wang, Kevin Lu, Kristian Georgiev, Kyle Luther, Li Jing, Max Schwarzer, Miguel Castro, Nitish Keskar, Rapha Gontijo Lopes, Shengjia Zhao, Sully Chen, Suvansh Sanjeev, Taylor Gordon, Ted Sanders, Wenda Zhou, Yang Song, Yujia Xie, Yujia Jin, Zhishuai Zhang
其他研究人员
Aditya Ramesh, Aiden Low, Alex Nichol, Andrei Gheorghe, Andrew Tulloch, Behrooz Ghorbani, Borys Minaiev, Brandon Houghton, Charlotte Cole, Chris Lu, Edmund Wong, Hannah Sheahan, Jacob Huh, James Qin, Jianfeng Wang, Jonathan Ward, Joseph Mo, Joyce Ruffell, Kai Chen, Karan Singhal, Karina Nguyen, Kenji Hata, Kevin Liu, Maja Trębacz, Matt Lim, Mikhail Pavlov, Ming Chen, Morgan Griffiths, Nat McAleese, Nick Stathas, Rajkumar Samuel, Ravi Teja Mullapudi, Rowan Zellers, Shengli Hu, Shuchao Bi, Spencer Papay, Szi‑chieh Yu, Yash Patil, Yufeng Zhang
应用与推广人员
Adam Walker, Ali Kamali, Alvin Wan, Andy Wang, Ben Leimberger, Beth Hoover, Brian Yu, Charlie Jatt, Chen Ding, Cheng Chang, Daniel Kappler, Dinghua Li, Felipe Petroski Such, Janardhanan Vembunarayanan, Joseph Florencio, Kevin King, Larry Lv, Lin Yang, Linden Li, Manoli Liodakis, Mark Hudnall, Nikunj Handa, Olivier Godement, Ryszard Madej, Sean Chang, Sean Fitzgerald, Sherwin Wu, Siyuan Fu, Stanley Hsieh, Yunxing Dai
销售、市场、公关及设计人员
Andy Wood, Ashley Tyra, Cary Hudson, Dana Palmie, Jessica Shieh, Justin Wang, Karan Sekhri, Katie Kim, Kendal Simon, Laura Peng, Leher Pathak, Lindsay McCallum, Matt Nichols, Nick Pyne, Noah MacCallum, Oona Gleeson, Pranav Deshpande, Rishabh Aggarwal, Scott Ethersmith, Shaokyi Amdo, Stephen Gutierrez, Tabarak Khan, Terry Lee, Thomas Degry, Veit Moeller, Yara Khakbaz