2025 年 12 月 12 日 OpenAI 发布了迄今为止最强大的GPT-5.2 模型,该系列专为提升专业知识型工作的效率和经济价值而设计,在制作电子表格、编写代码、设计演示文稿及处理复杂多步骤项目方面表现出显著优势。
卓越的工作效率与质量
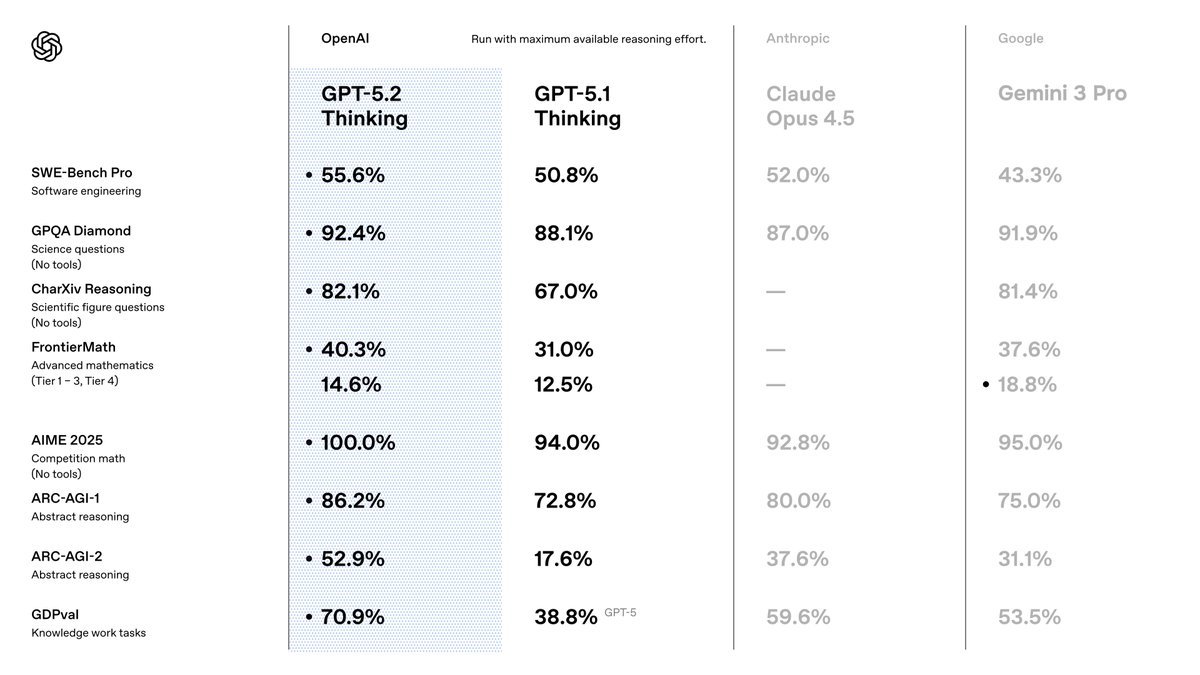
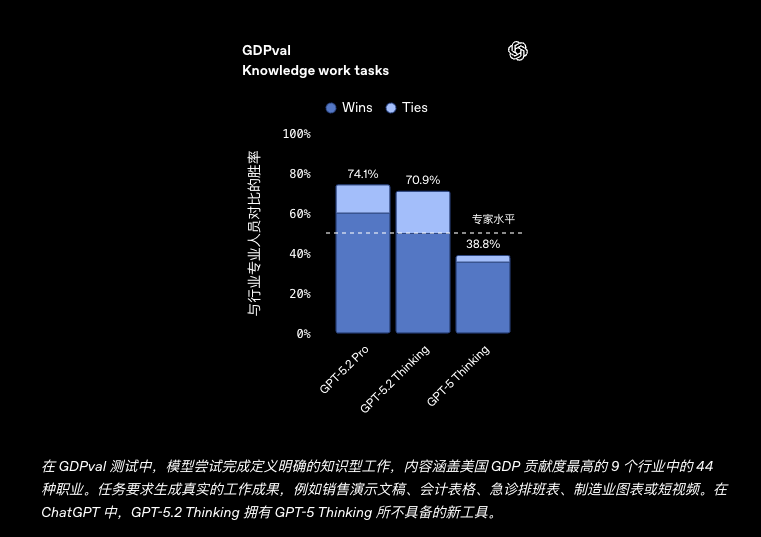
在衡量明确知识型工作任务的 GDPval 评测中, GPT-5.2 刷新了行业水平,成为首个在相关任务上达到或超过人类专家水平的模型。
- 专家级表现:在涵盖 44 个职业的 GDPval 评测中, GPT-5.2 Thinking 在 70.9% 的任务中表现优于顶尖行业专家或与其持平。
- 极致效能:在上述任务中,模型的输出速度比专家快 11 倍以上,而成本不到专家的 1%。
- 办公自动化:在生成复杂的电子表格和幻灯片方面,能力较前代提升了 9.3%,格式和布局更具专业水准。
编程与工程能力的飞跃
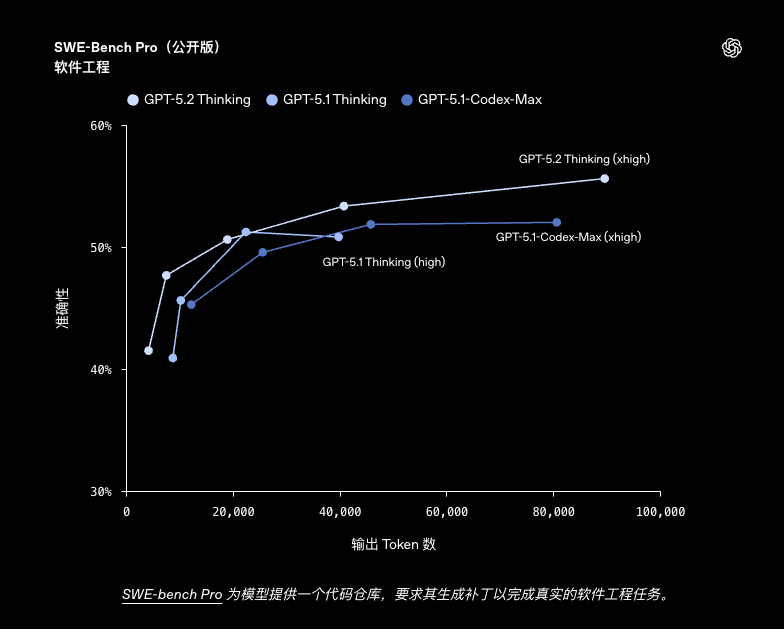
- 软件工程基准:在模拟真实工业场景的 SWE-bench Pro 测试中取得了 55.6% 的新成绩;在 SWE-bench Verified 中达到了 80% 的高分。
- 全栈开发助手:在前端开发、复杂 UI(特别是涉及 3D 元素)以及代码调试和重构方面表现更强,减少了人工干预的需求。
可靠性、长文本与视觉能力
- 错误率降低:相比 GPT-5.1 Thinking,新模型的幻觉率更低,错误回答减少了 38%。
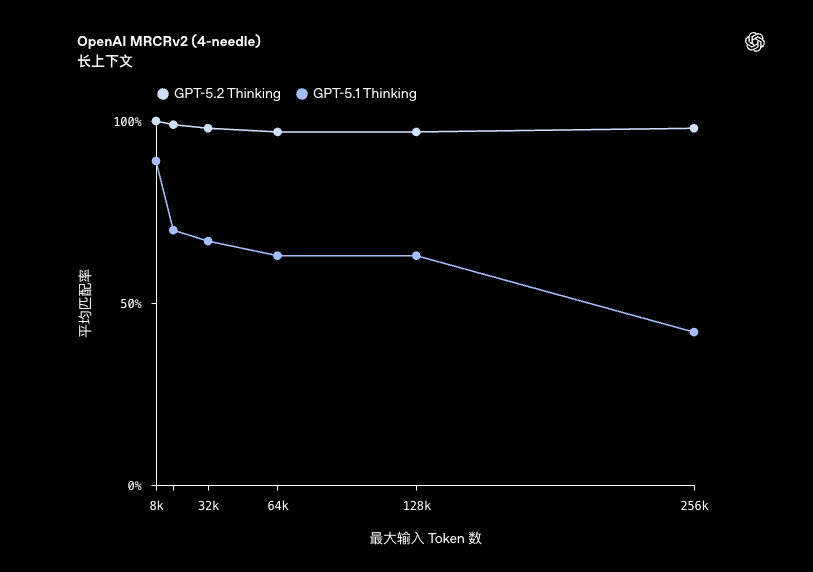
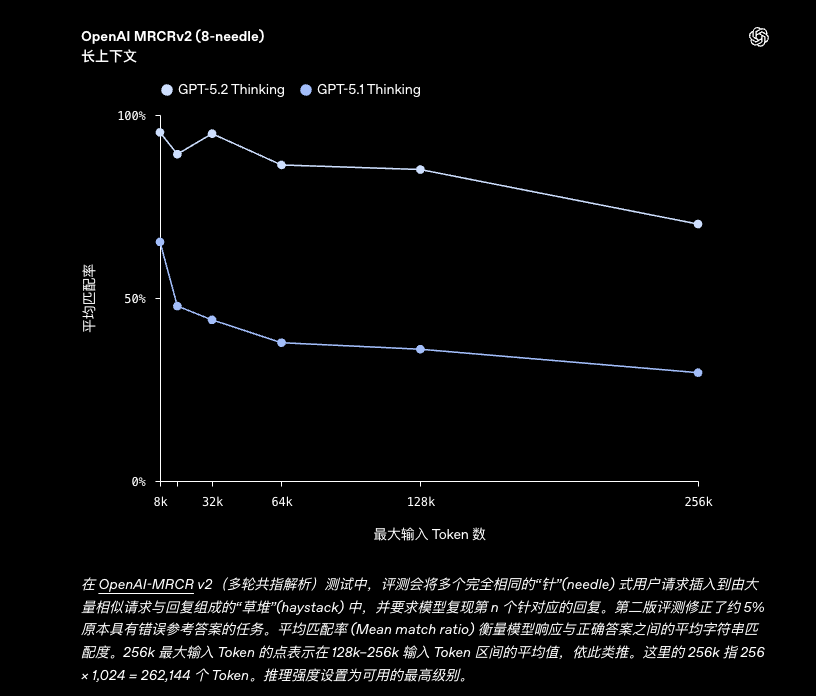
- 长文档处理:在长达 256k Token 的文本范围内(如 MRCRv2 评测),能保持接近 100% 的信息提取准确率,适合深度文档分析。
- 视觉理解:在图表推理和软件界面理解方面的错误率减半,对图像元素的空间位置有更强的感知能力。
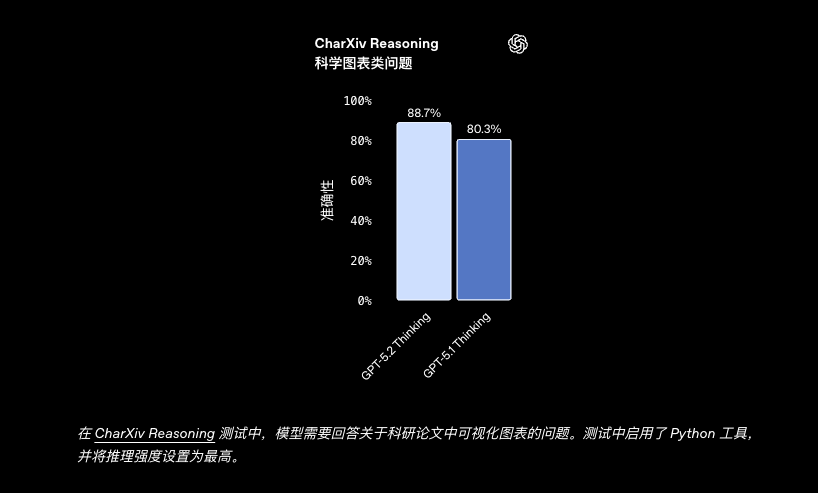
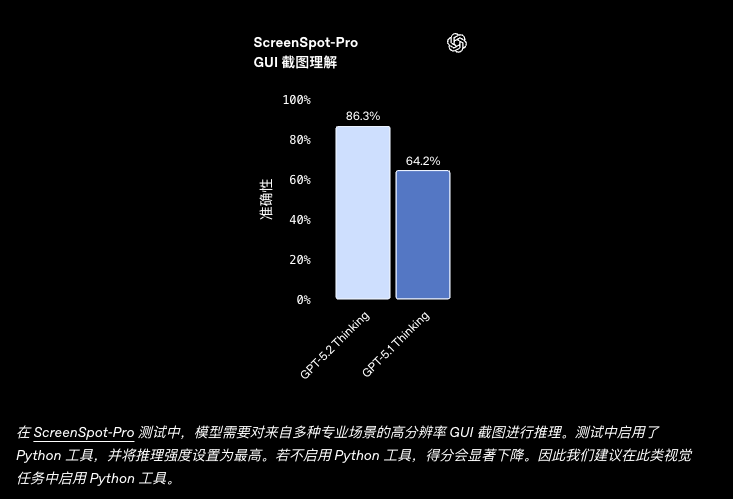
科研推进与复杂推理
- 科学研究: GPT-5.2 Pro 在研究生级问答测试 GPQA Diamond 中得分 93.2%,并已在实际数学研究中协助解决了统计学习理论的开放问题。
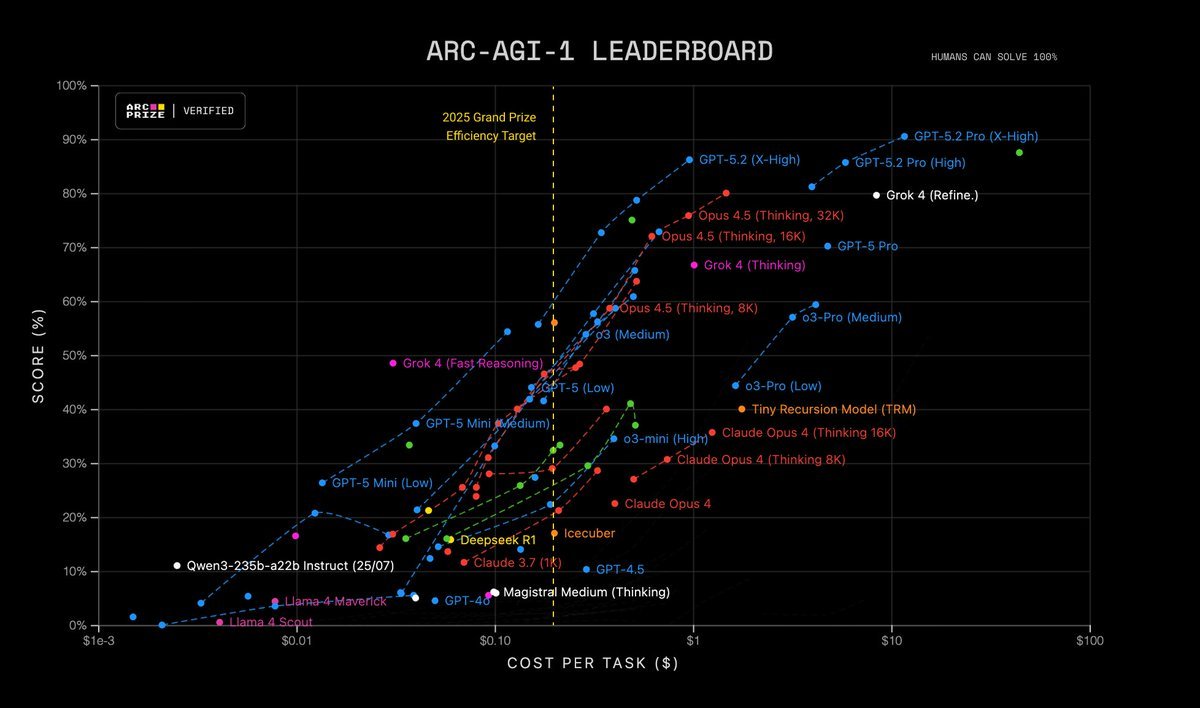
- 通用推理:在 ARC-AGI-1 测试中, GPT-5.2 成为首个突破 90% 准确率的模型。
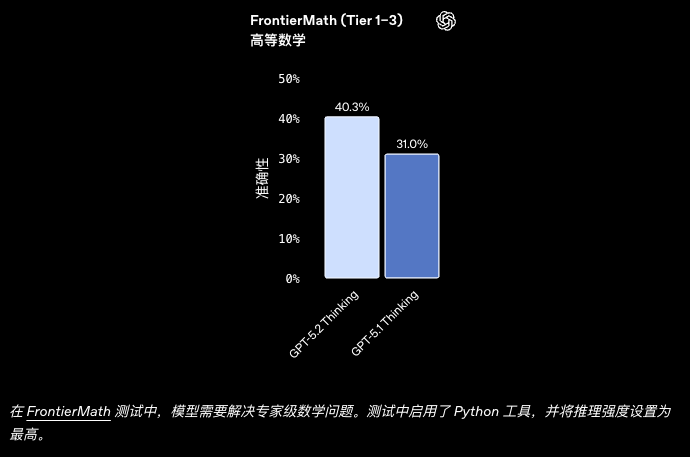
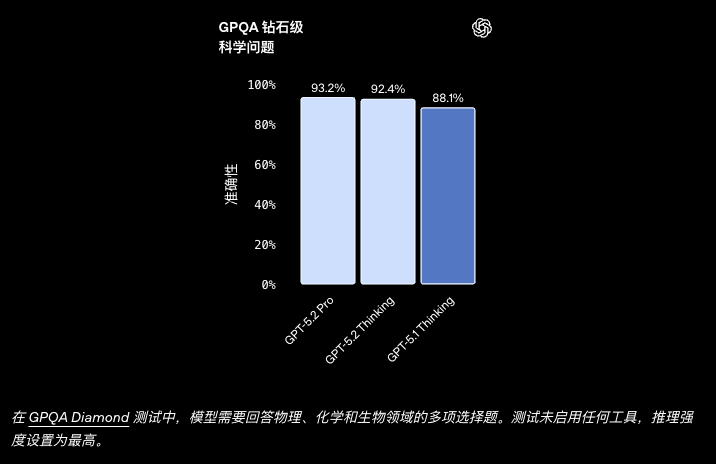
发布、安全与定价
- 可用性:即日起在 ChatGPT 中向付费套餐用户(如 Plus、Enterprise)陆续推送;API 现已向开发者开放。
- 安全性:增强了对敏感话题(如自残、心理困扰)的处理能力,并引入了针对未成年人的年龄预测保护机制。
- 定价:API 价格为每百万输入 Token 1.75 美元,每百万输出 Token 14 美元。虽然单价高于前代,但因效率提升,完成同等质量任务的整体成本可能更低。
附录
详细基准
下面我们将展示 GPT‑5.2 Thinking 的完整基准测试结果,并同时提供一部分 GPT‑5.2 Pro 的相关数据。
专业
| GPT-5.2 Thinking | GPT-5.2 Pro | GPT-5.1 Thinking | |
|---|---|---|---|
| GDPval (ties allowed, wins or ties) | 70.9% | 74.1% | 38.8% (GPT-5) |
| GDPval (ties allowed, clear wins) | 49.8% | 60.0% | 35.5% (GPT-5) |
| GDPval (no ties) | 61.0% | 67.6% | 37.1% (GPT-5) |
| Investment banking spreadsheet tasks (internal) | 68.4% | 71.7% | 59.1% |
编码
| GPT-5.2 Thinking | GPT-5.2 Pro | GPT-5.1 Thinking | |
|---|---|---|---|
| SWE-Bench Pro, Public | 55.6% | - | 50.8% |
| SWE-bench Verified | 80.0% | - | 76.3% |
| SWE-Lancer, IC Diamond* | 74.6% | - | 69.7% |
事实性
| GPT-5.2 Thinking | GPT-5.2 Pro | GPT-5.1 Thinking | |
|---|---|---|---|
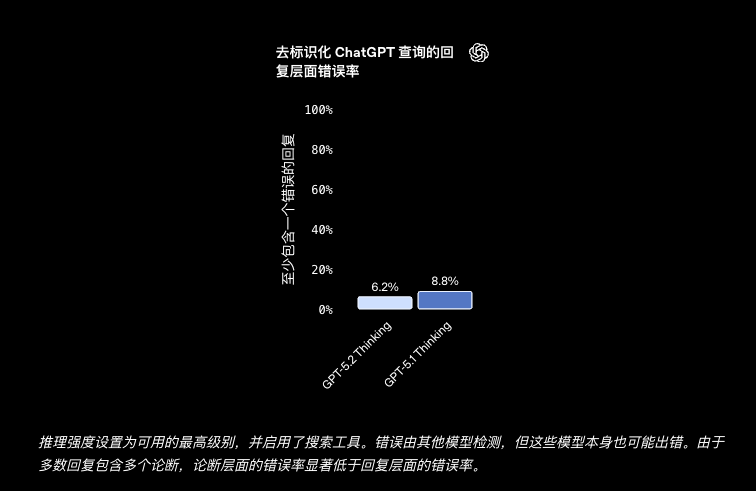
| ChatGPT answers without errors (w/ search) | 93.9% | - | 91.2% |
| ChatGPT answers without errors (no search) | 88.0% | - | 87.3% |
长上下文
| GPT-5.2 Thinking | GPT-5.2 Pro | GPT-5.1 Thinking | |
|---|---|---|---|
| OpenAI MRCRv2, 8 needles, 4k–8k | 98.2% | - | 65.3% |
| OpenAI MRCRv2, 8 needles, 8k–16k | 89.3% | - | 47.8% |
| OpenAI MRCRv2, 8 needles, 16k–32k | 95.3% | - | 44.0% |
| OpenAI MRCRv2, 8 needles, 32k–64k | 92.0% | - | 37.8% |
| OpenAI MRCRv2, 8 needles, 64k–128k | 85.6% | - | 36.0% |
| OpenAI MRCRv2, 8 needles, 128k–256k | 77.0% | - | 29.6% |
| BrowseComp Long Context 128k | 92.0% | - | 90.0% |
| BrowseComp Long Context 256k | 89.8% | - | 89.5% |
| GraphWalks bfs <128k | 94.0% | - | 76.8% |
| Graphwalks parents <128k | 89.0% | - | 71.5% |
展望
| GPT-5.2 Thinking | GPT-5.2 Pro | GPT-5.1 Thinking | |
|---|---|---|---|
| CharXiv reasoning (no tools) | 82.1% | - | 67.0% |
| CharXiv reasoning (w/ Python) | 88.7% | - | 80.3% |
| MMMU Pro (no tools) | 79.5% | - | - |
| MMMU Pro (w/ Python) | 80.4% | - | 79.0% |
| Video MMMU (no tools) | 85.9% | - | 82.9% |
| Screenspot Pro (w/ Python) | 86.3% | - | 64.2% |
工具使用
| GPT-5.2 Thinking | GPT-5.2 Pro | GPT-5.1 Thinking | |
|---|---|---|---|
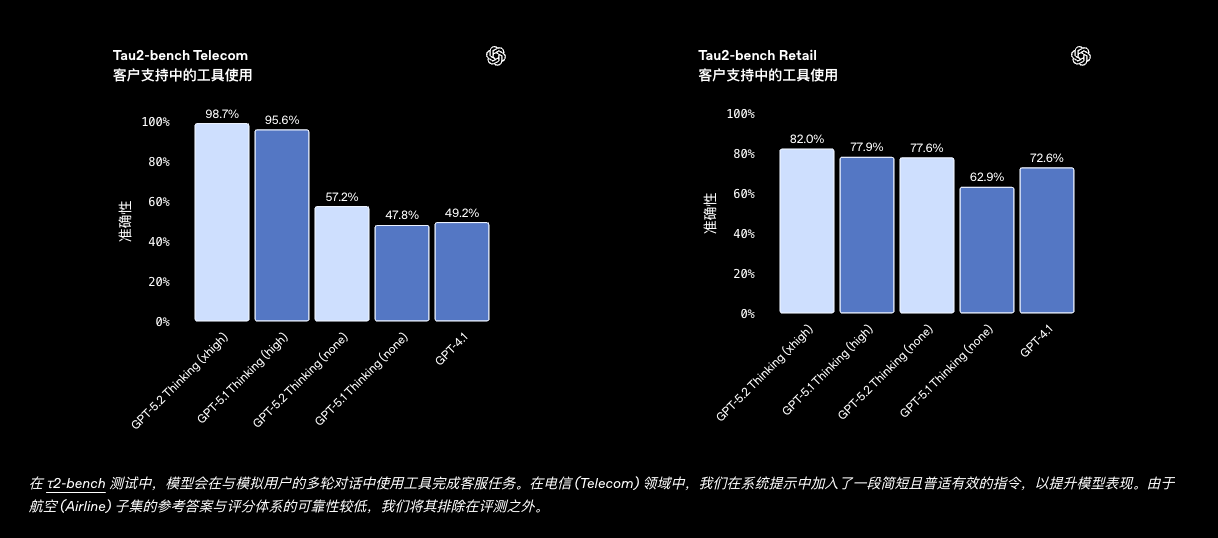
| Tau2-bench Telecom | 98.7% | - | 95.6% |
| Tau2-bench Retail | 82.0% | - | 77.9% |
| BrowseComp | 65.8% | 77.9% | 50.8% |
| Scale MCP-Atlas | 60.6% | - | 44.5% |
| Toolathlon | 46.3% | - | 36.1% |
学术
| GPT-5.2 Thinking | GPT-5.2 Pro | GPT-5.1 Thinking | |
|---|---|---|---|
| GPQA Diamond (no tools) | 92.4% | 93.2% | 88.1% |
| HLE (no tools) | 34.5% | 36.6% | 25.7% |
| HLE (w/ search, Python) | 45.5% | 50.0% | 42.7% |
| MMMLU | 89.6% | - | 89.5% |
| HMMT, Feb 2025 (no tools) | 99.4% | 100.0% | 96.3% |
| AIME 2025 (no tools) | 100.0% | 100.0% | 94.0% |
| FrontierMath Tier 1–3 (w/ Python) | 40.3% | - | 31.0% |
| FrontierMath Tier 4 (w/ Python) | 14.6% | - | 12.5% |
抽象推理
| GPT-5.2 Thinking | GPT-5.2 Pro | GPT-5.1 Thinking | |
|---|---|---|---|
| ARC-AGI-1 (Verified) | 86.2% | 90.5% | 72.8% |
| ARC-AGI-2 (Verified) | 52.9% | 54.2% (high) | 17.6% |
在我们的 API 中,模型都以可用的最高推理强度运行(GPT‑5.2 Thinking 与 Pro 使用 xhigh,GPT‑5.1 Thinking 使用 high)。唯一的例外是专业类评测:在这些测试中,GPT‑5.2 Thinking 使用的是 heavy 推理强度,这是 ChatGPT Pro 中可用的最高等级。所有基准测试均在研究环境中完成,因此在某些情况下,结果可能会与正式上线的 ChatGPT 输出略有不同。
\* 在 SWE-Lancer 测试中,我们排除了 40 个无法在当前基础设施上运行的题目(共 237 个题目)。