OpenAI 于 2025年 8 月 8 日发布最新、最强大的、转为开发者设计的 AI 模型——GPT-5。该模型在编码和智能体任务方面树立了新的行业标杆,提供了前所未有的性能、可控性和协作能力。
主要内容
- 发布新一代模型
GPT-5:GPT-5是一个专为编码和智能体任务优化的顶尖模型,现已通过 API 平台发布。 - 卓越的编码与智能体能力:该模型在各项关键基准测试中表现出色,能够高效处理复杂的编码任务,如修复
bug、代码编辑和问答。同时,它在执行需要连续调用多个工具的长期智能体任务方面也达到了业界领先水平。 - 增强的开发者控制:API 引入了多项新功能,包括用于控制响应速度与质量的
reasoning_effort参数、调节内容详略的verbosity参数,以及支持更灵活工具调用的custom tools。 - 多样的模型选择:为满足不同场景下对性能、成本和延迟的需求,
GPT-5提供了三种不同规模的版本:gpt-5、gpt-5-mini和gpt-5-nano。 - 更高的可靠性与安全性:
GPT-5在事实准确性上相比前代模型有显著提升,事实性错误减少了约80%,使其在处理关键任务时更加值得信赖。
关键细节
性能表现
- 编码能力:
- 在
SWE-bench Verified基准测试中得分74.9%,超越了o3的69.1%。 - 在
Aider polyglot代码编辑测试中得分88%,错误率比o3降低了三分之一。 - 在前端开发测试中,
70%的情况下优于o3。
- 在
- 智能体任务:
- 在
τ2-bench telecom工具调用基准测试中得分高达96.7%,远超其他模型。 - 能够可靠地连续或并行调用数十个工具来完成复杂任务。
- 在
- 长上下文处理:
- 在
OpenAI-MRCR测试中全面超越前代模型,尤其在长输入下优势明显。 - 所有
GPT-5模型支持最高272,000输入token和128,000输出token,总上下文长度达400,000token。
- 在
- 事实准确性:
- 在
LongFact和FactScore基准测试中,事实性错误比o3减少了约80%。
- 在
新增 API 功能
reasoning_effort参数:新增minimal选项,可在牺牲部分推理深度的情况下实现更快的响应。verbosity参数:提供low、medium、high三个级别,用于控制模型回答的详细程度。custom tools(自定义工具):允许模型使用纯文本(plaintext)而非JSON格式调用工具,并可通过正则表达式或上下文无关文法进行约束,简化了复杂输入的处理。
模型版本与可用性
- API 模型:
gpt-5:$1.25/1M 输入token,$10/1M 输出token。gpt-5-mini:$0.25/1M 输入token,$2/1M 输出token。gpt-5-nano:$0.05/1M 输入token,$0.40/1M 输出token。
- 平台集成:
GPT-5也已在Microsoft 365 Copilot、GitHub Copilot和Azure AI Foundry等微软平台上线。
安全与可靠性
GPT-5经过专门训练,能更好地识别自身局限性,并能更准确地回答健康相关问题。- 模型在安全性和可靠性方面得到全面提升,幻觉现象显著减少,能更诚实地沟通其能力范围。
原文
引言
今天,我们在我们的 API 平台中发布了 GPT‑5——这是我们迄今为止在编码和智能体任务方面最出色的模型。
GPT‑5 在关键的编码基准测试中达到了业界顶尖(SOTA)水平,在 SWE-bench Verified 上得分 74.9%,在 Aider polyglot 上得分 88%。我们将 GPT‑5 训练成一个真正的编码协作者。它擅长生成高质量的代码,并能处理修复错误、编辑代码以及回答有关复杂代码库的问题等任务。该模型具有可引导性和协作性——它能以高精度遵循非常详细的指令,并能在工具调用之前和之间预先解释其操作。该模型在前端编码方面也表现出色,在内部测试中,其在前端网页开发方面有 70% 的时间击败了 OpenAI o3。
我们与初创公司和大型企业的早期测试者合作,在真实世界的编码任务上训练了 GPT‑5。Cursor 表示 GPT‑5 是“他们用过的最智能的模型”,并且“非常智能,易于引导,甚至具有我们在其他模型中未见过的个性。” Windsurf 分享说,GPT‑5 在他们的评估中达到了业界顶尖水平,并且“工具调用错误率是其他前沿模型的一半。” Vercel 表示“它是最好的前端 AI 模型,在美学感知和代码质量方面都达到了顶级性能,使其独树一帜。”
GPT‑5 在长期运行的智能体任务方面也表现出色——在仅两个月前发布的工具调用基准测试 τ2-bench telecom 上取得了业界顶尖(SOTA)的成绩(96.7%)。GPT‑5 改进的工具智能使其能够可靠地将数十个工具调用串联起来——无论是顺序还是并行——而不会迷失方向,这使其在端到端执行复杂的真实世界任务方面表现得更好。它还能更精确地遵循工具指令,更好地处理工具错误,并擅长长上下文内容检索。Manus 表示 GPT‑5 “在我们内部基准测试中,取得了我们从单个模型上见过的最佳性能。” Notion 表示“该模型的快速响应,尤其是在低推理模式下,使 GPT‑5 成为您需要一次性解决复杂任务时的理想模型。” Inditex 分享说“真正让 GPT‑5 与众不同的是其推理的深度:细致入微、多层次的答案反映了对主题的真正理解。”
我们在 API 中引入了新功能,让开发者对模型响应有更多控制。GPT‑5 支持一个新的 verbosity(详细度)参数(可选值:low、medium、high),以帮助控制答案是简明扼要还是详尽全面。GPT‑5 的 reasoning_effort(推理强度)参数现在可以取一个最小值,以便在没有大量预先推理的情况下更快地获得答案。我们还增加了一种新的工具类型——自定义工具——让 GPT‑5 可以用纯文本而不是 JSON 来调用工具。自定义工具支持使用开发者提供的上下文无关文法进行约束。
我们在 API 中发布了三种尺寸的 GPT‑5——gpt-5、gpt-5-mini 和 gpt-5-nano——为开发者在性能、成本和延迟之间进行权衡提供了更大的灵活性。虽然 ChatGPT 中的 GPT‑5 是一个由推理、非推理和路由模型组成的系统,但 API 平台中的 GPT‑5 是为 ChatGPT 提供最高性能的推理模型。值得注意的是,使用最低推理强度的 GPT‑5 与 ChatGPT 中的非推理模型不同,并且更适合开发者。ChatGPT 中使用的非推理模型以 gpt-5-chat-latest 的形式提供。
要了解 ChatGPT 中的 GPT‑5,并了解更多关于 ChatGPT 的其他改进,请参阅我们的研究博客。有关企业如何期待使用 GPT‑5 的更多信息,请参阅我们的企业博客。
编码
GPT‑5 是我们发布过的最强大的编码模型。它在编码基准和真实世界用例中都优于 o3,并经过微调,在 Cursor、Windsurf、GitHub Copilot 和 Codex CLI 等智能体编码产品中表现出色。GPT‑5 给我们的 alpha 测试者留下了深刻印象,在他们的许多私有内部评估中创下了记录。
关于 GPT-5 在真实世界编码任务中的早期反馈
“GPT-5 是我们用过的最智能的编码模型。我们的团队发现 GPT-5 非常智能,易于引导,甚至具有我们在任何其他模型中都未见过的个性。它不仅能捕捉到棘手的、深藏的错误,还能运行长期的、多轮的后台智能体来完成复杂的任务——这类问题过去常常让其他模型束手无策。它已经成为我们从规划和计划 PR 到完成端到端构建等所有日常工作的驱动力。”
Michael Truell, Cursor 联合创始人兼首席执行官
在基于真实世界软件工程任务的评估 SWE-bench Verified 中,GPT‑5 的得分为 74.9%,高于 o3 的 69.1%。值得注意的是,GPT‑5 以更高的效率和速度取得了高分:相对于高推理强度的 o3,GPT‑5 使用的输出 Token 减少了 22%,工具调用减少了 45%。
在 SWE-bench Verified 中,模型会获得一个代码仓库和问题描述,并且必须生成一个补丁来解决该问题。文本标签表示推理强度。我们的分数省略了 500 个问题中的 23 个,因为它们的解决方案在我们的基础设施上无法可靠地通过。GPT‑5 使用了一个简短的提示,强调要彻底验证解决方案;同样的提示对 o3 没有帮助。
在代码编辑评估 Aider polyglot 中,GPT‑5 创下了 88% 的新纪录,错误率比 o3 减少了三分之一。
在 Aider polyglot (diff) 中,模型会获得一个来自 Exercism 的编码练习,并且必须以代码 diff 的形式编写解决方案。推理模型以高推理强度运行。
我们还发现 GPT‑5 非常擅长深入研究代码库,以回答关于各个部分如何工作或相互操作的问题。在像 OpenAI 的强化学习栈这样复杂的代码库中,我们发现 GPT‑5 可以帮助我们推理和回答关于我们代码的问题,从而加速我们自己的日常工作。
前端工程
在为 Web 应用生成前端代码时,GPT‑5 更具美感、更有雄心且更准确。在与 o3 的并排比较中,我们的测试者有 70% 的时间更偏爱 GPT‑5。
以下是一些有趣的、精选的例子,展示了 GPT‑5 只需一个提示就能做什么:
提示: 请为一个服务生成一个漂亮、逼真的登陆页面。该服务为终极咖啡爱好者提供每月 200 美元的订阅,包括咖啡烘焙和制作顶级意式浓缩咖啡的设备租赁和指导。目标受众是湾区的中年人,可能在科技行业工作,受过良好教育,有可支配收入,并对咖啡的艺术和科学充满热情。优化设置为期 6 个月的注册转化率。
在我们的作品集中查看更多 GPT‑5 的例子 这里。
编码协作
GPT‑5 是一个更好的协作者,尤其是在 Cursor、Windsurf、GitHub Copilot 和 Codex CLI 等智能体编码产品中。在工作时,GPT‑5 可以在工具调用之间输出计划、更新和回顾。与我们过去的模型相比,GPT‑5 在完成宏大任务时更主动,不会停下来等待你的批准,也不会因高复杂度而退缩。
以下是一个例子,展示了 GPT‑5 在处理复杂任务(本例中是为一个餐厅创建网站)时的样子:
在用户要求为他们的餐厅创建一个网站后,GPT‑5 分享了一个快速计划,搭建了应用程序框架,安装了依赖项,创建了网站内容,运行构建以检查编译错误,总结了其工作,并提出了潜在的后续步骤。该视频已加速约 3 倍以节省您的等待时间;创建网站的完整时长约为三分钟。
智能体任务
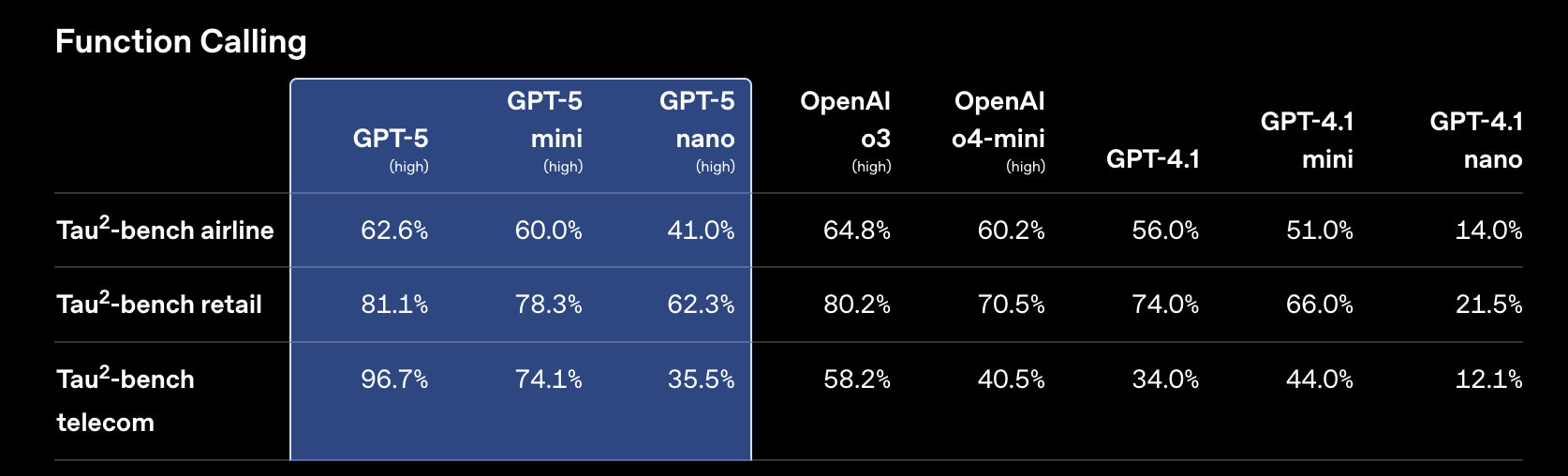
除了智能体编码,GPT‑5 在智能体任务方面也普遍表现更佳。GPT‑5 在指令遵循(在 Scale MultiChallenge 上为 69.6%,由 o3‑mini 评分)和工具调用(在 τ2-bench telecom 上为 96.7%)的基准测试中创下新纪录。改进的工具智能使 GPT‑5 能够更可靠地将多个操作串联起来,以完成真实世界的任务。
关于 GPT-5 在智能体任务上的早期反馈
“GPT-5 是一个巨大的进步。在我们内部的基准测试中,它取得了我们从单个模型上见过的最佳性能。GPT-5 在各种智能体任务中都表现出色——甚至在我们调整任何一行代码或定制一个提示之前。新的前导消息和对工具使用的更精确控制,使我们智能体的稳定性和可引导性实现了显著飞跃。”
Yichao ‘Peak’ Ji, Manus 联合创始人兼首席科学家
指令遵循
GPT‑5 比其任何前辈都更可靠地遵循指令,在 COLLIE、Scale MultiChallenge 和我们的内部指令遵循评估中得分很高。
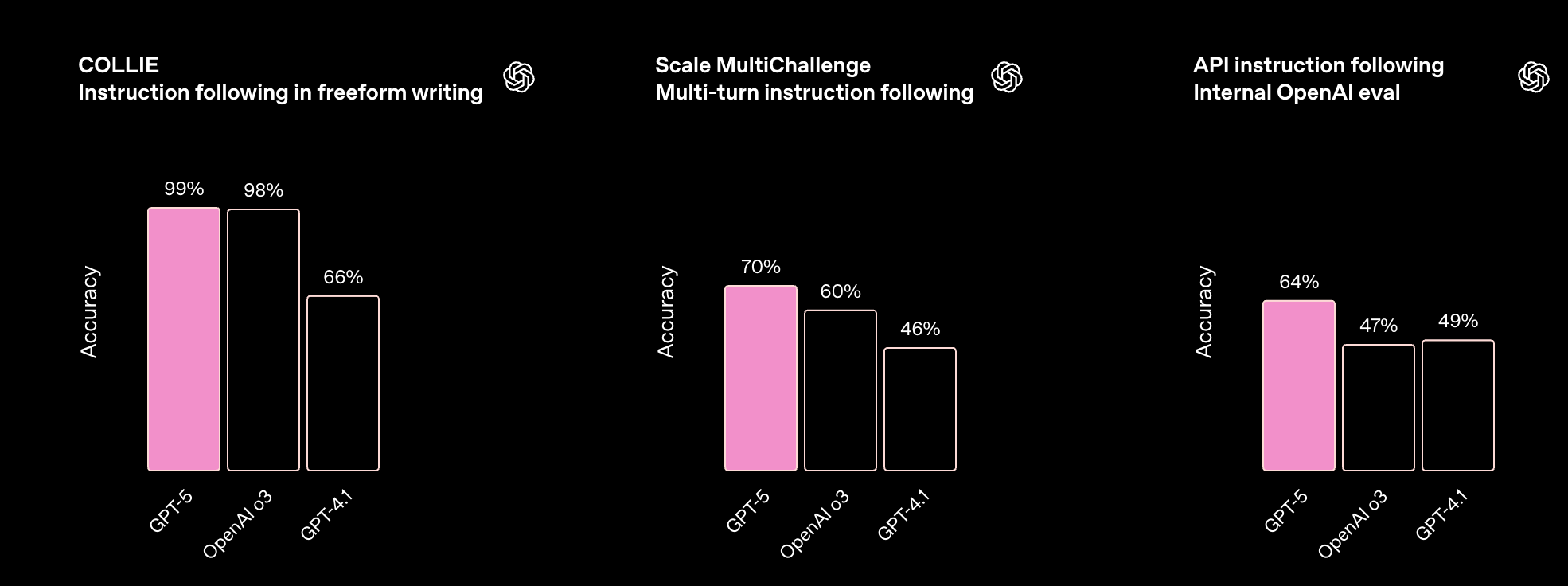
在 COLLIE 中,模型必须编写满足各种约束的文本。在 Scale MultiChallenge 中,模型在多轮对话中受到挑战,需要正确使用来自先前消息的四种类型的信息。我们的分数来自使用 o3‑mini 作为评分器,它比 GPT‑4o 更准确。在我们的内部 OpenAI API 指令遵循评估中,模型必须遵循源自真实开发者反馈的困难指令。推理模型以高推理强度运行。
工具调用
我们努力改进工具调用,以满足开发者的实际需求。GPT‑5 在遵循工具指令、处理工具错误以及主动地顺序或并行进行多次工具调用方面表现更佳。在接到指令时,GPT‑5 还能在工具调用之前和之间输出前导消息,以便在较长的智能体任务期间向用户更新进展。
两个月前,Sierra.ai 发布了 τ2-bench telecom,这是一个具有挑战性的工具使用基准测试,突显了当语言模型与可被用户改变的环境状态交互时,性能会显著下降。在他们的出版物中,没有模型的得分超过 49%。而 GPT‑5 的得分为 97%。
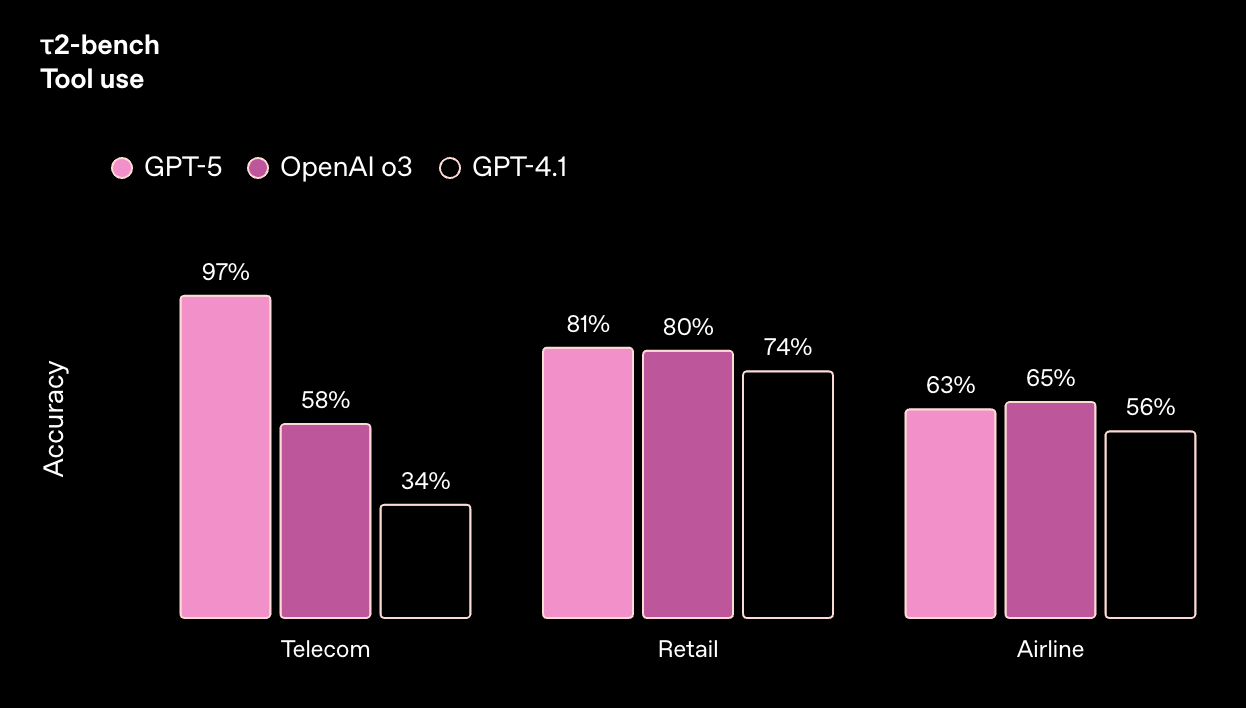
在 τ2-bench 中,模型必须使用工具来完成客户服务任务,其中可能有用户可以进行交流并对世界状态采取行动。推理模型以高推理强度运行。
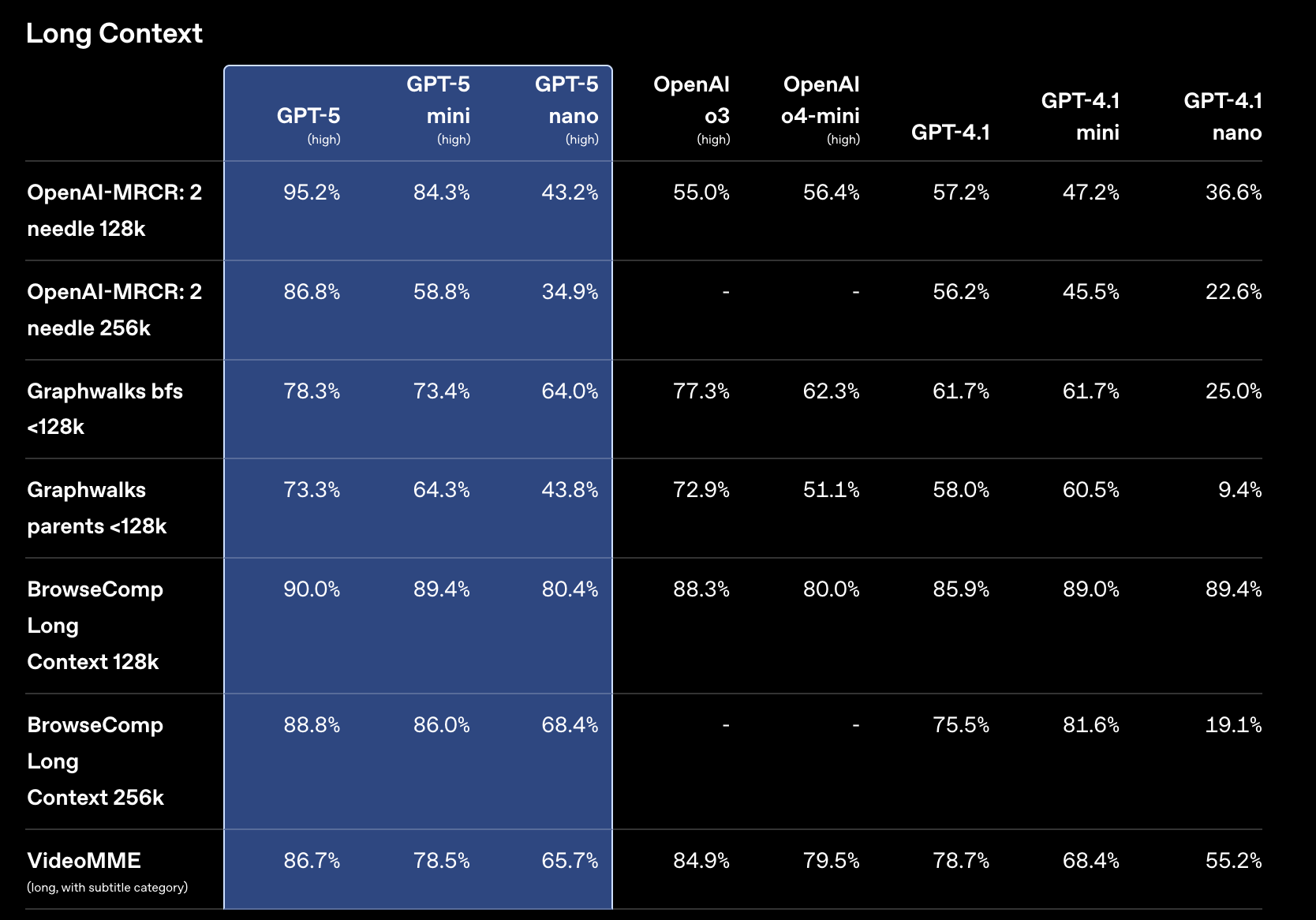
GPT‑5 在长上下文性能方面也显示出强大的改进。在衡量长上下文信息检索能力的 OpenAI-MRCR 上,GPT‑5 的表现优于 o3 和 GPT-4.1,并且随着输入长度的增加,优势愈发明显。
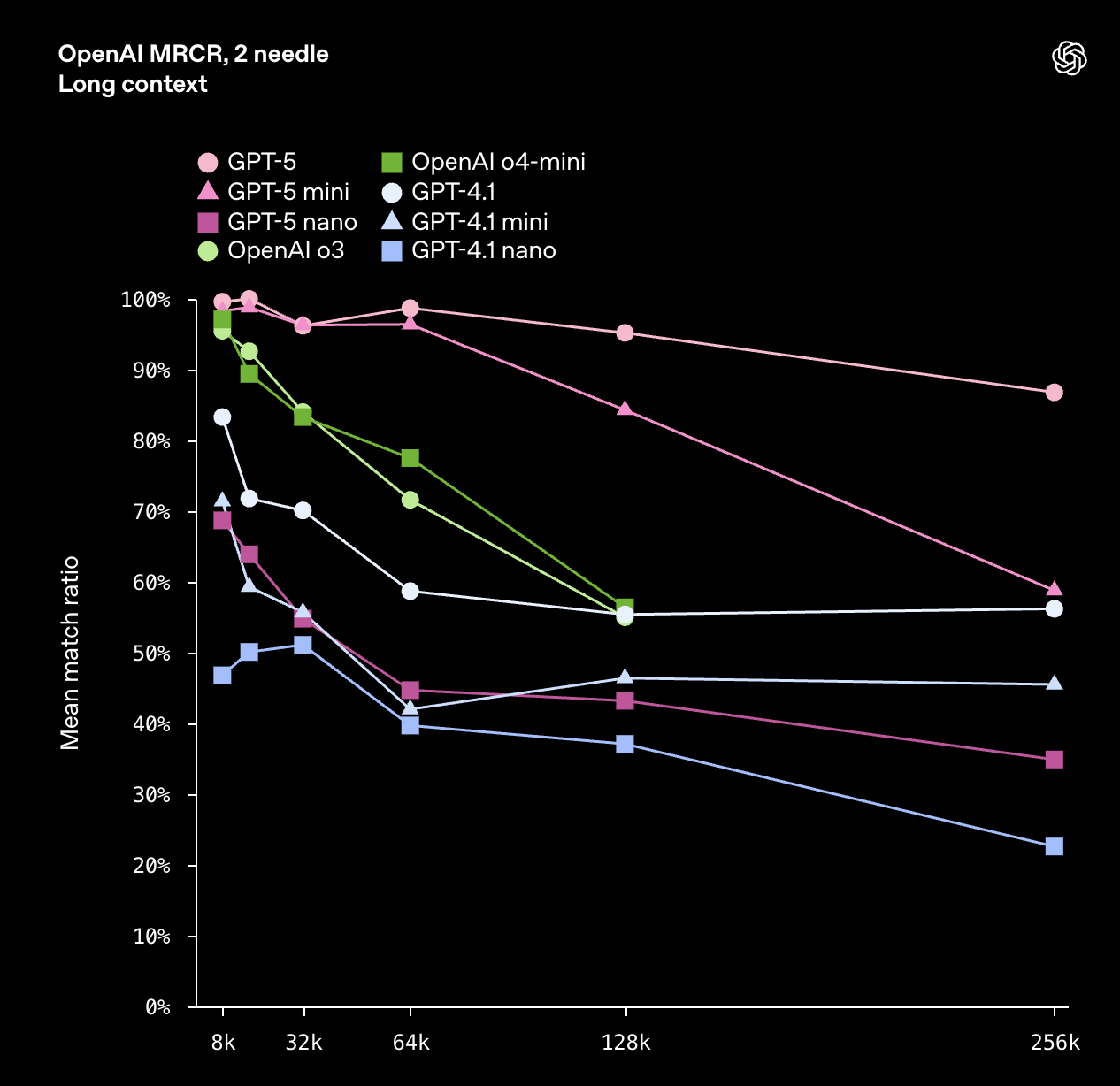
在 OpenAI-MRCR(多轮共指消解)中,多个相同的“针”(用户请求)被插入到长长的“干草堆”(相似的请求和响应)中,模型被要求复现对第 i 个针的响应。平均匹配率衡量模型响应与正确答案之间的平均字符串匹配率。256k 最大输入 Token 的点代表 128k–256k 输入 Token 的平均值,以此类推。在这里,256k 代表 256 * 1,024 = 262,114 个 Token。推理模型以高推理强度运行。
我们还开源了 BrowseComp Long Context,这是一个用于评估长上下文问答的新基准。在该基准中,模型会得到一个用户查询和一长串相关的搜索结果,并且必须根据搜索结果回答问题。我们设计 BrowseComp Long Context 的目的是使其真实、困难,并有可靠正确的标准答案。在 128K–256K Token 的输入上,GPT‑5 给出正确答案的比例为 89%。
在 API 中,所有 GPT‑5 模型最多可接受 272,000 个输入 Token,并最多可发出 128,000 个推理和输出 Token,总上下文长度为 400,000 个 Token。
事实性
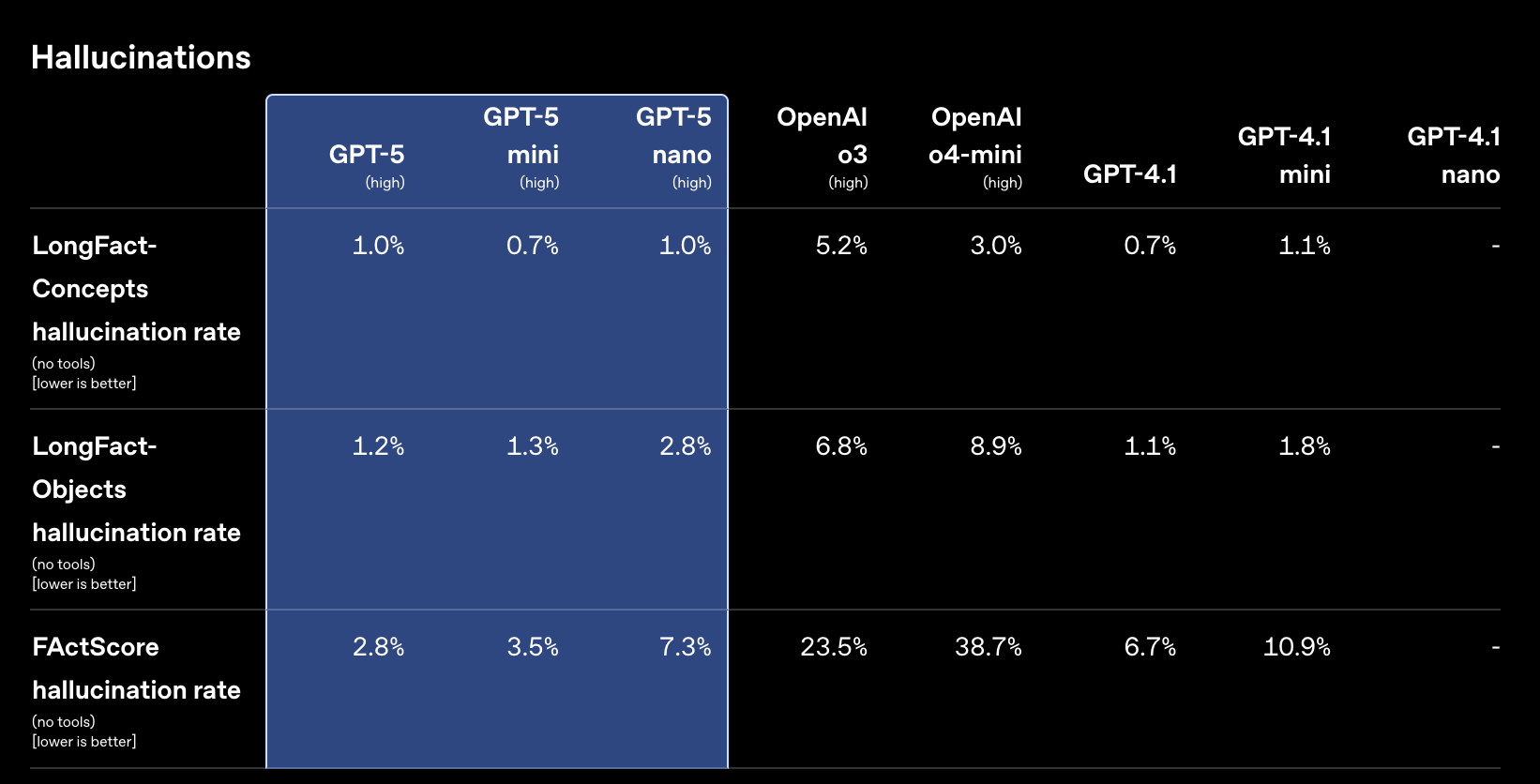
GPT‑5 比我们以前的模型更值得信赖。在来自 LongFact 和 FactScore 基准测试的提示上,GPT‑5 的事实性错误比 o3 少约 80%。这使其更适用于对正确性要求高的智能体用例——尤其是在代码、数据和决策制定方面。
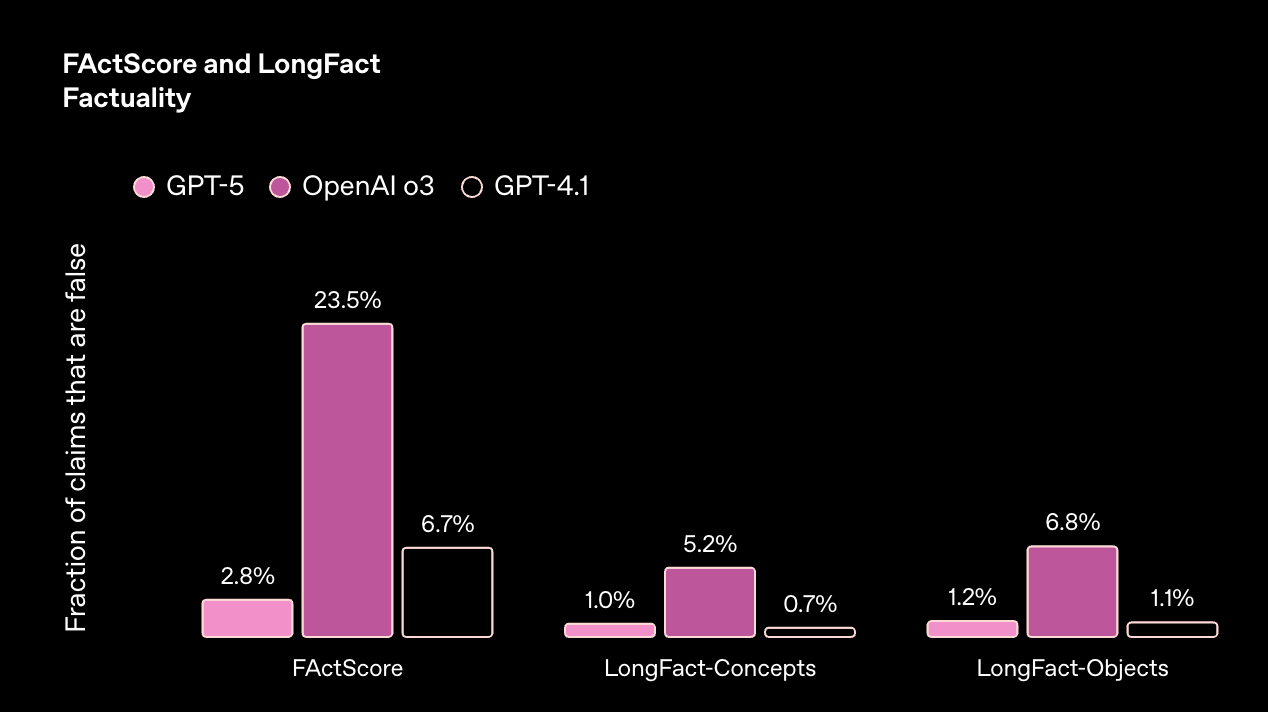
分数越高越差。LongFact 和 FActScore 包含开放式的事实寻求问题。我们使用基于 LLM 的评分器并结合浏览功能,对来自这些基准的提示的响应进行事实核查,并测量事实不正确声明的比例。实现和评分的细节可以在系统卡片中找到。推理模型使用高推理强度。搜索功能未启用。
总的来说,GPT‑5 经过训练,能更好地自我意识到自身的局限性,并能更好地处理意想不到的难题。我们还训练 GPT‑5 在健康问题上更加准确(更多信息请阅读我们的研究博客)。与所有语言模型一样,我们建议您在事关重大时验证 GPT‑5 的工作。
新功能
最低推理强度
开发者可以通过 API 中的 reasoning_effort 参数来控制 GPT‑5 的思考时间。除了之前的值——low(低)、medium(中,默认值)和 high(高)——GPT‑5 还支持 minimal(最低),它能最大限度地减少 GPT‑5 的推理,以快速返回答案。
较高的 reasoning_effort 值可以最大化质量,较低的值可以最大化速度。并非所有任务都能同等地从额外的推理中受益,因此我们建议进行实验,看看哪种设置最适合您关心的用例。
例如,高于 low 的推理对相对简单的长上下文检索任务增益不大,但对 CharXiv Reasoning(一个视觉推理基准)的得分却能增加好几个百分点。
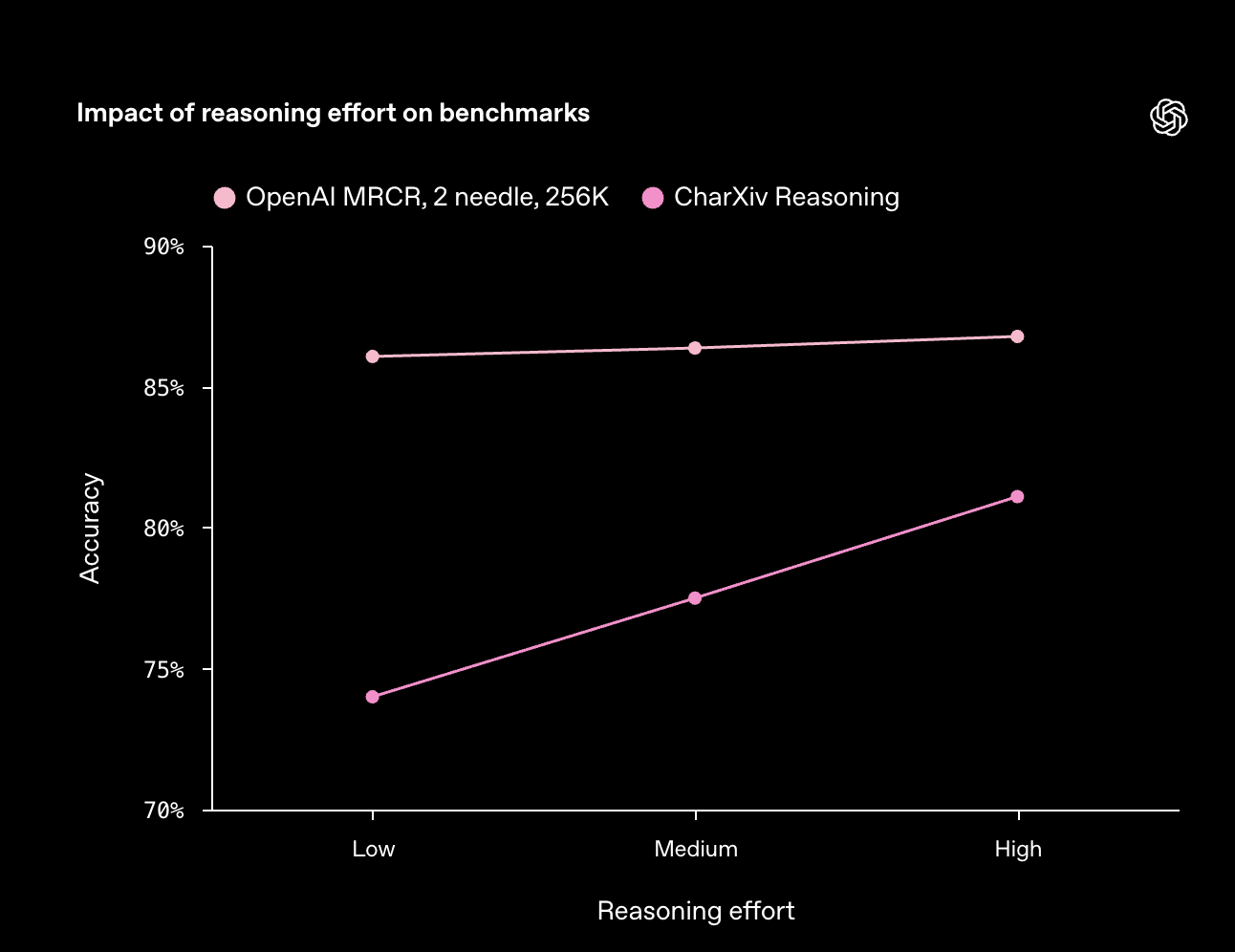
GPT‑5 的推理强度在不同任务上产生不同效益。对于 CharXiv Reasoning,GPT‑5 被赋予了使用 python 工具的权限。
详细度
为了帮助引导 GPT‑5 答案的默认长度,我们引入了一个新的 API 参数 verbosity(详细度),其可选值为 low(低)、medium(中,默认值)和 high(高)。如果明确的指令与详细度参数冲突,则以明确的指令为准。例如,如果您要求 GPT‑5 “写一篇 5 段的短文”,无论详细度级别如何,模型的响应都应该是 5 段(但段落本身可能会更长或更短)。
详细度=低
为什么天空是蓝色的?
因为瑞利散射。空气分子比可见光的波长小得多,所以它们对短波长(蓝色/紫色)的散射远比长波长(红色)的要多。被散射的蓝光从四面八方进入你的眼睛,使天空看起来是蓝色的。我们不怎么看得到紫色,因为太阳发出的紫色较少,我们的眼睛对它不太敏感,而且部分紫色在大气层上部被吸收了。在日出和日落时,光线穿过更厚的大气层,去除了更多的蓝色,使天空呈现微红色。
详细度=中
为什么天空是蓝色的?
因为瑞利散射。太阳光包含所有颜色,但空气分子对较短波长(蓝色/紫色)的散射比对较长波长(红色)的散射要强烈得多。散射强度大致与 1/(波长)^4 成正比,所以蓝光被重新定向到整个天空并进入你的眼睛。
我们看不到紫色的天空是因为:
- 太阳发出的紫色比蓝色稍少。
- 大气层上部吸收了一些紫色/紫外线。
- 人眼对紫色不太敏感。
在日出和日落时,太阳光穿过更多的大气层,沿途散射掉了大部分蓝光,留下了较长的红色/橙色波长主导视野。
详细度=高
为什么天空是蓝色的?
天空看起来是蓝色的,因为太阳光被地球大气中的微小分子散射了。这个过程被称为瑞利散射。
关键点:
- 太阳光由多种颜色(波长)组成。较短的波长,如紫色和蓝色,比像红色这样的较长波长更容易被空气分子强烈散射。散射强度随着波长变短而急剧增加。
- 当太阳光穿过大气层时,较短波长的光(尤其是蓝色)被向各个方向散射,所以无论你朝向太阳以外的任何方向看,你都会看到那种被散射的蓝光——即“蓝天”。
为什么不是紫色?
- 太阳发出的紫色比蓝色少。
- 我们的眼睛对紫色不太敏感。
- 一些紫色/紫外线在更高处被臭氧层吸收了。
综合起来,这使得我们感知到的散射光主要是蓝色的。
为什么日落是红色/橙色的?
- 在日出和日落时,太阳光穿过大气层的路径要长得多。
- 大部分蓝光在到达你的眼睛之前就被从直射路径中散射出去了,使得剩下的直射阳光富含红色和橙色。
其他影响:
- 雾霾、污染、烟雾或灰尘含有较大的颗粒,它们对光的散射选择性较小(称为米氏散射),使天空看起来更苍白或发白。
- 由于散射的几何原理,蓝天是部分偏振的,这就是为什么偏光太阳镜可以使部分天空变暗。
- 在拥有不同大气和颗粒大小的星球上(如火星),天空可能因为类似的散射原因而呈现奶油色或微红色。
如果地球没有大气层,就没有东西可以散射太阳光,天空即使在白天也会是黑色的,太阳只是一个明亮的圆盘。
工具调用前的前导消息
如果被指示,GPT‑5 将在工具调用之前和之间输出用户可见的前导消息。与隐藏的推理消息不同,这些可见的消息允许 GPT‑5 向用户传达计划和进展,帮助最终用户理解其处理方法和工具调用背后的意图。
自定义工具
我们正在引入一种新的工具类型——自定义工具——它允许 GPT‑5 使用纯文本而不是 JSON 来调用工具。为了约束 GPT‑5 遵循自定义工具的格式,开发者可以提供一个正则表达式,甚至是一个更完整的上下文无关文法。
以前,我们为开发者定义的工具设计的接口要求它们以 JSON 格式调用,这是 Web API 和开发者普遍使用的一种常见格式。然而,输出有效的 JSON 要求模型完美地转义所有引号、反斜杠、换行符和其他控制字符。尽管我们的模型经过良好训练可以输出 JSON,但在像数百行代码或 5 页报告这样的长输入上,出错的几率会增加。有了自定义工具,GPT‑5 可以将工具输入写成纯文本,而无需转义所有需要转义的字符。
在 SWE-bench Verified 上,使用自定义工具代替 JSON 工具,GPT‑5 的得分大致相同。
安全性
GPT‑5 在安全性方面推动了前沿,是一个更健壮、可靠和有帮助的模型。与我们以前的模型相比,GPT‑5 产生幻觉的可能性显著降低,能更诚实地向用户传达其行为和能力,并在尽可能提供最有帮助的答案的同时,仍然保持在安全边界内。您可以在我们的研究博客中阅读更多内容。
可用性与定价
GPT‑5 现在已在 API 平台中提供,有三种尺寸:gpt-5、gpt-5-mini 和 gpt-5-nano。它可在 Responses API、Chat Completions API 上使用,并且是 Codex CLI 中的默认模型。GPT‑5 的定价为每百万输入 Token 1.25 美元,每百万输出 Token 10 美元;GPT‑5 mini 的定价为每百万输入 Token 0.25 美元,每百万输出 Token 2 美元;GPT‑5 nano 的定价为每百万输入 Token 0.05 美元,每百万输出 Token 0.40 美元。
这些模型支持 reasoning_effort 和 verbosity API 参数以及自定义工具。它们还支持并行工具调用、内置工具(网页搜索、文件搜索、图像生成等)、核心 API 功能(流式传输、结构化输出等)以及节省成本的功能,如提示缓存和 Batch API。
ChatGPT 中使用的 GPT‑5 的非推理版本在 API 中以 gpt-5-chat-latest 的形式提供,定价也为每百万输入 Token 1.25 美元和每百万输出 Token 10 美元。
GPT‑5 也正在微软的各个平台上推出,包括 Microsoft 365 Copilot、Copilot、GitHub Copilot 和 Azure AI Foundry。
查看 GPT‑5 的文档、定价详情 和提示指南 以开始使用。
详细基准测试
智能
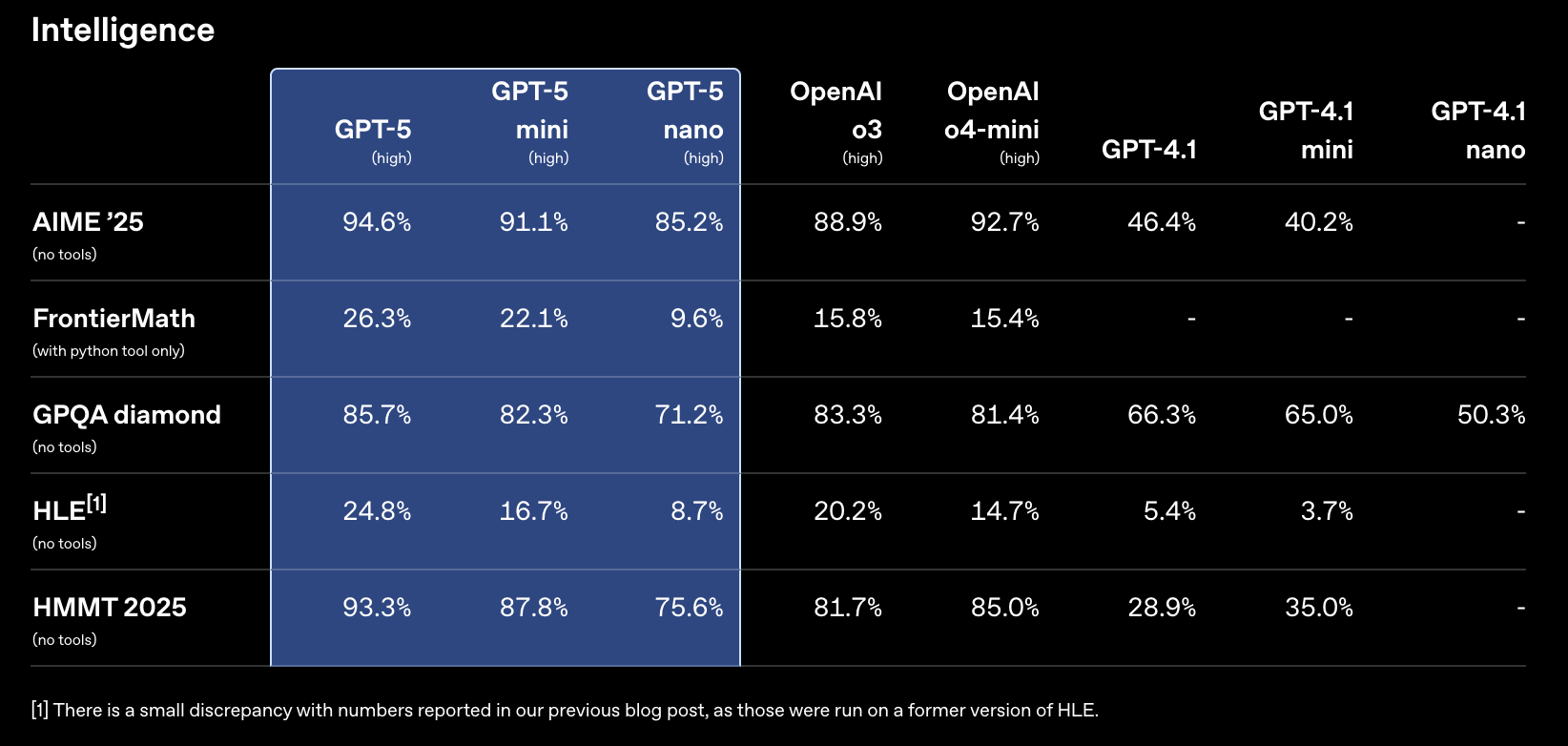
[1] 与我们之前博客文章中报告的数字有微小差异,因为那些是在 HLE 的旧版本上运行的。
多模态
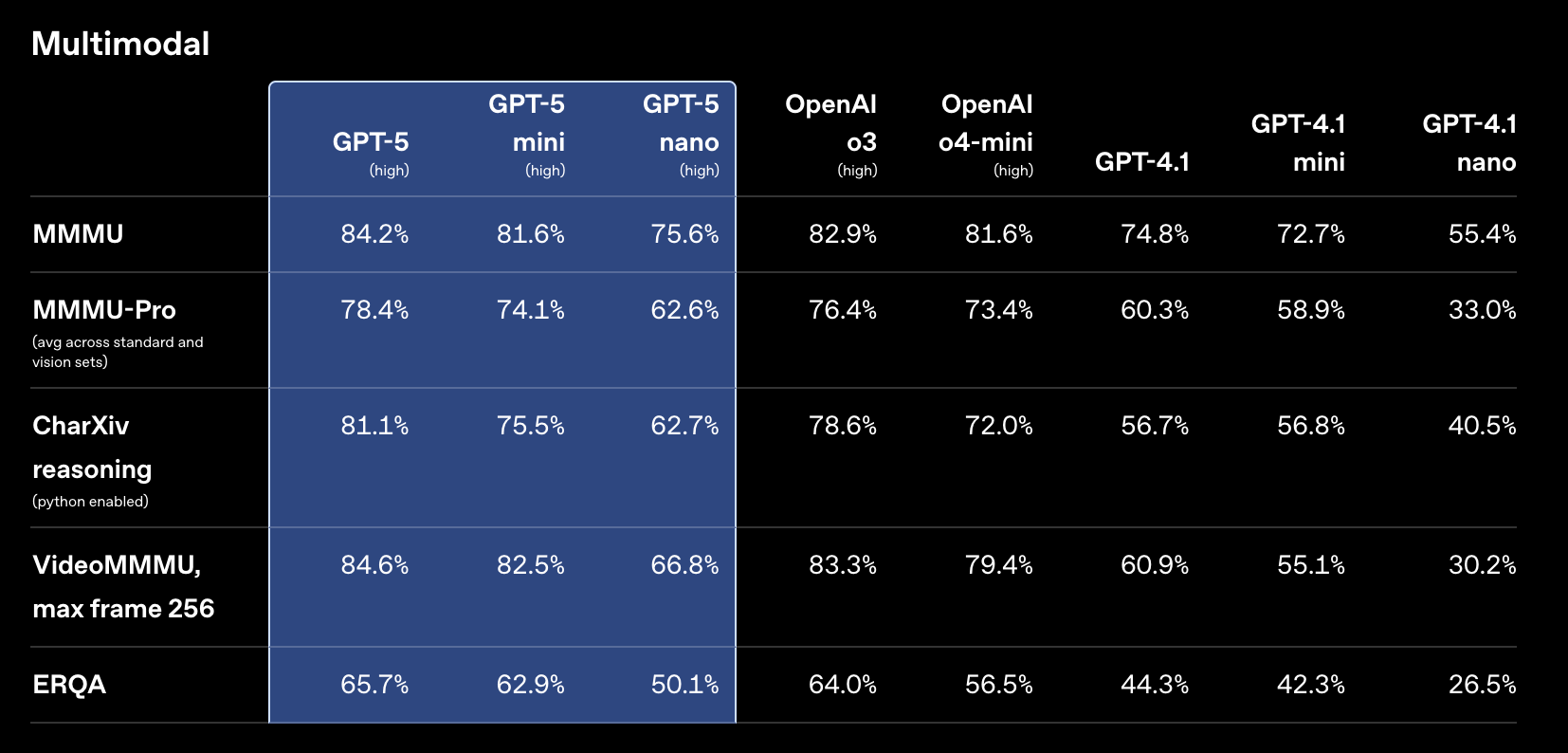
编码
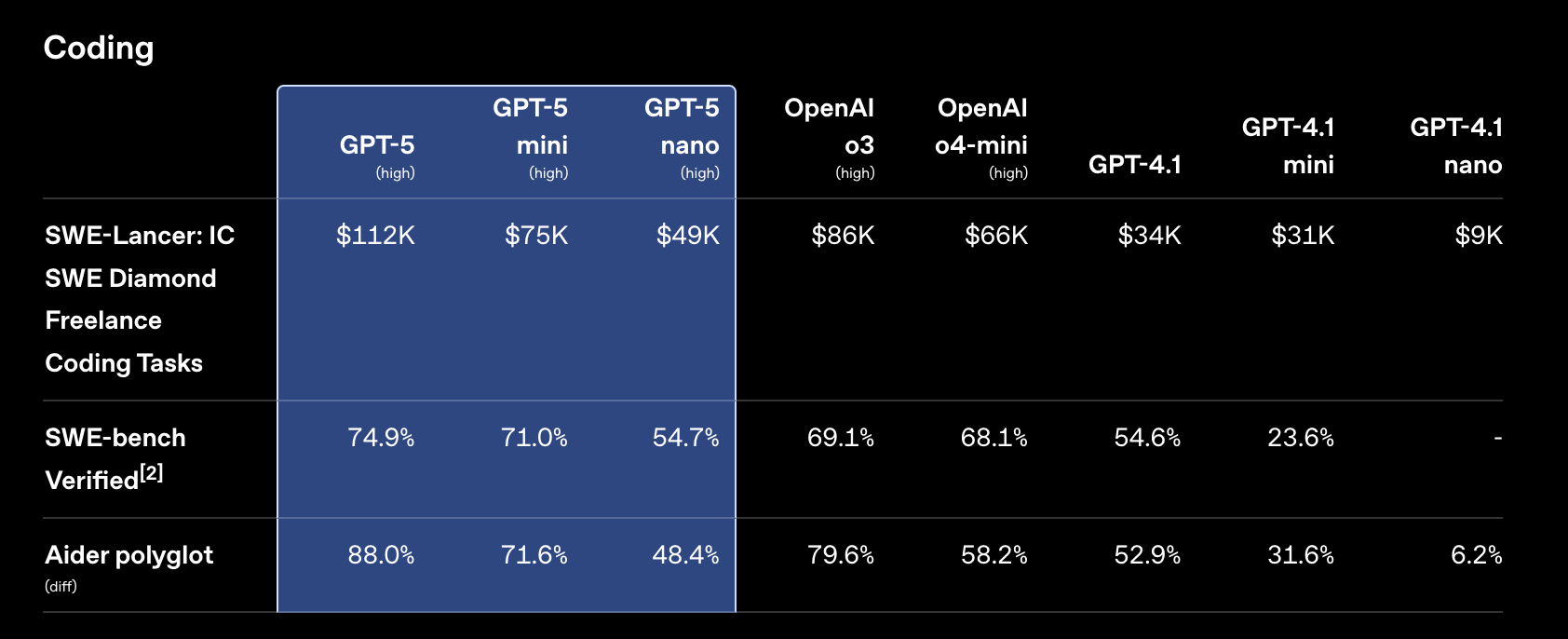
[2] 我们省略了 500 个问题中无法在我们基础设施上运行的 23 个。省略的 23 个任务的完整列表是 ‘astropy__astropy-7606’, ‘astropy__astropy-8707’, ‘astropy__astropy-8872’, ‘django__django-10097’, ‘django__django-7530’, ‘matplotlib__matplotlib-20488’, ‘matplotlib__matplotlib-20676’, ‘matplotlib__matplotlib-20826’, ‘matplotlib__matplotlib-23299’, ‘matplotlib__matplotlib-24970’, ‘matplotlib__matplotlib-25479’, ‘matplotlib__matplotlib-26342’, ‘psf__requests-6028’, ‘pylint-dev__pylint-6528’, ‘pylint-dev__pylint-7080’, ‘pylint-dev__pylint-7277’, ‘pytest-dev__pytest-5262’, ‘pytest-dev__pytest-7521’, ‘scikit-learn__scikit-learn-12973’, ‘sphinx-doc__sphinx-10466’, ‘sphinx-doc__sphinx-7462’, ‘sphinx-doc__sphinx-8265’, 和 ‘sphinx-doc__sphinx-9367’。
指令遵循
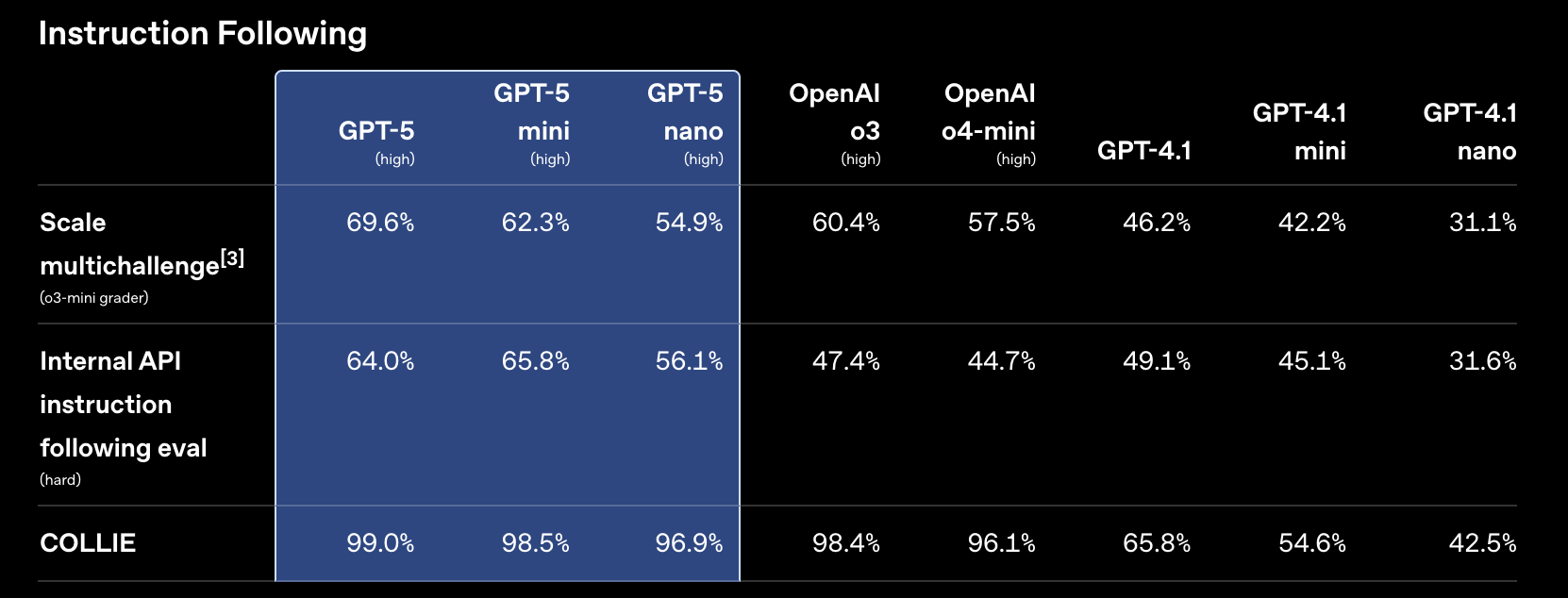
[3] 注意:我们发现 MultiChallenge 中的默认评分器(GPT-4o)经常错误地评分模型响应。我们发现将评分器更换为推理模型,如 o3-mini,能显著提高我们检查过的样本的评分准确性。
函数调用
长上下文
幻觉