OpenAI 于 2025年 4 月 17 日推出了 o3 和 o4-mini,这两款模型在智能和能力上都代表了显著的进步,特别是它们能够在其响应前进行更长时间的“思考”,并且首次实现了对 ChatGPT 内所有工具(如网页搜索、使用 Python 进行数据分析、视觉输入推理、图像生成等)的自主、智能调用和组合。
- 新模型发布: OpenAI 推出了其 o 系列中迄今为止最智能、能力最强的模型——
o3和o4-mini。 - 核心能力提升: 这两款模型被训练用于更深度的推理(“思考更长时间”),显著提升了
ChatGPT的能力。 - 全面的工具集成: 模型首次能够自主地(agentically)决定何时以及如何使用
ChatGPT内的所有工具(网络搜索、代码执行、视觉分析、图像生成等)来解决复杂问题。 - 迈向智能代理: 这是向更具自主性的
ChatGPT迈出的一步,使其能够独立代表用户执行多方面任务。 - 性能新标杆: 结合了顶尖的推理能力和全面的工具使用,使得模型在学术基准测试和现实世界任务中表现显著增强,树立了智能和实用性的新标准。
- 模型定位:
o3是功能最强大的前沿模型,适用于复杂分析;o4-mini则为速度和成本效益进行了优化,适合需要推理能力的大容量、高吞吐量任务。
介绍 OpenAI o3 和 o4-mini
我们迄今为止最智能且功能最强大的 AI 模型,并赋予了它们完整的工具使用权限
今天,我们发布 OpenAI o3 和 o4-mini,这是我们 o 系列模型中的最新成员,这些模型经过训练,可以在响应之前进行更深入的思考。 它们是我们迄今为止发布的最智能的 AI 模型,代表着 ChatGPT 在能力上的一次飞跃,惠及从普通用户到高级研究人员的每一个人。 我们的推理模型首次能够以智能代理式地使用和组合 ChatGPT 中的每一个工具——包括网络搜索、使用 Python 分析上传的文件和其他数据、对视觉输入进行深入推理,甚至是生成图像。 关键在于,这些模型经过专门训练,能够判断何时以及如何使用工具,以正确的输出格式(通常在一分钟内)生成细致且周到的答案,从而解决更为复杂的问题。 这使得它们能够更有效地处理多方面的问题,朝着更具智能体 (AI Agent) 能力的 ChatGPT 迈出了一步,让 ChatGPT 能够代表您独立执行任务。 这种最先进的推理能力与完整工具访问权限的结合,转化为在学术基准和实际任务中性能的显著提升,为智能和实用性都树立了新的标杆。
性能提升
OpenAI o3 是我们目前最强大的推理模型,在编码、数学、科学、视觉感知等多个领域都取得了突破。 它在包括 Codeforces、SWE-bench (无需构建特定于模型的自定义支架) 和 MMMU 在内的基准测试中,均达到了 State-of-the-art (SOTA) 的水平。 尤其适用于需要多方面分析,且答案可能并不显而易见的复杂查询。 在处理诸如分析图像、图表和图形等视觉任务时,表现尤为出色。 外部专家的评估表明,在处理具有挑战性的实际任务时,o3 相较于 OpenAI o1,重大错误减少了 20%,尤其在编程、商业/咨询和创意构思等领域表现突出。 早期测试者强调了 o3 作为思考伙伴的分析严谨性,并着重提到了它在生物学、数学和工程等领域,生成并批判性评估全新假设的能力。
OpenAI o4-mini 是一款更小型的 AI 模型,它经过优化,旨在实现快速且经济高效的推理。 尽管尺寸和成本有所降低,但其性能依然出色,尤其是在数学、编码和视觉任务方面。 在 AIME 2024 和 2025 的测试中,它是性能最佳的基准模型。 专家评估还显示,在非 STEM 任务以及数据科学等领域,o4-mini 的表现也优于其前身 o3-mini。 凭借其高效性,o4-mini 能够支持比 o3 更高的使用量限制,对于那些需要推理能力且数据吞吐量大的问题而言,是一个强大的选择。
外部专家评估人员认为,这两款 AI 模型在指令理解和执行方面都有所提升,并且与之前的模型相比,能够提供更有用、更可靠的响应,这归功于智能水平的提高以及对网络资源的利用。 此外,与之前的推理模型迭代版本相比,这两款 AI 模型也应该会感觉更加自然,更善于对话,特别是在它们能够参考记忆和过往对话,从而使响应更具个性化和相关性的时候。
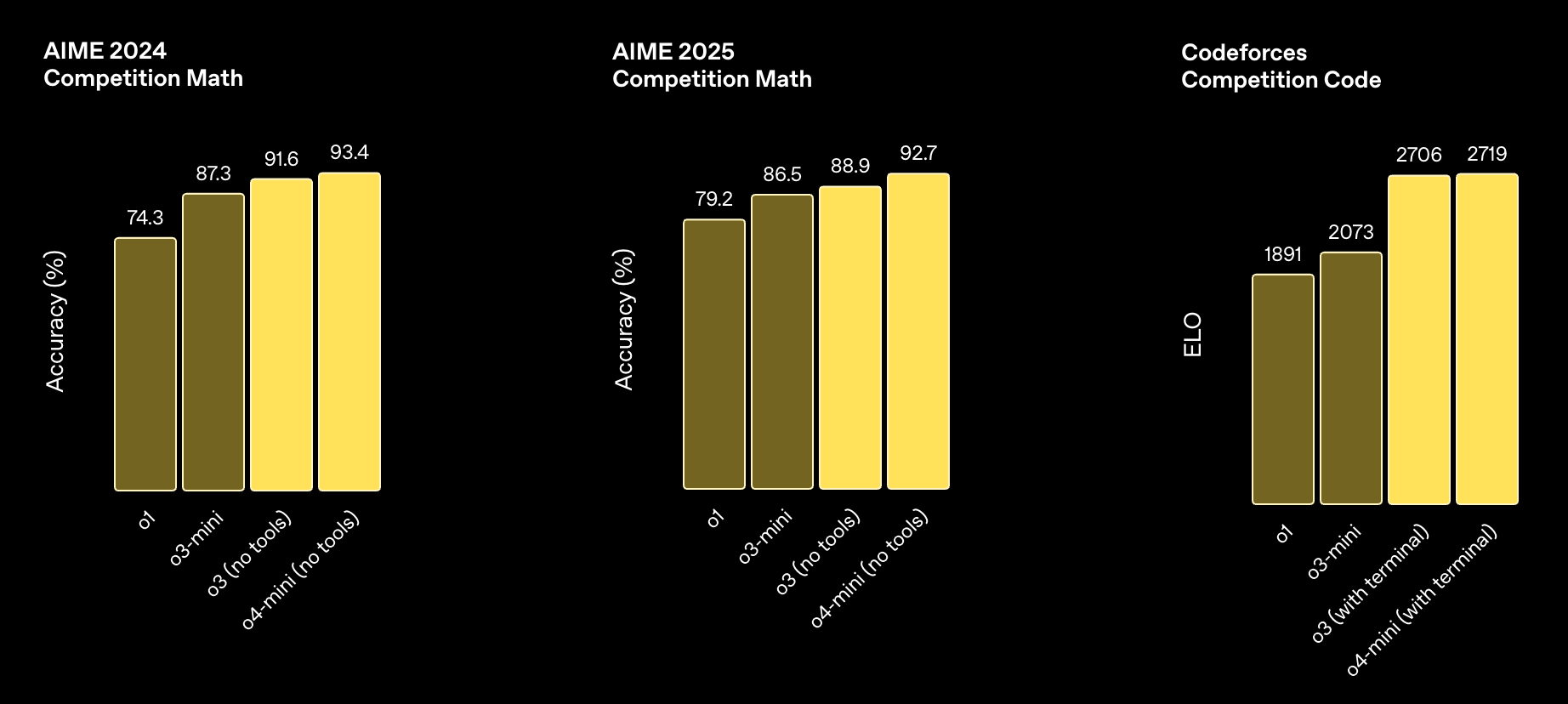
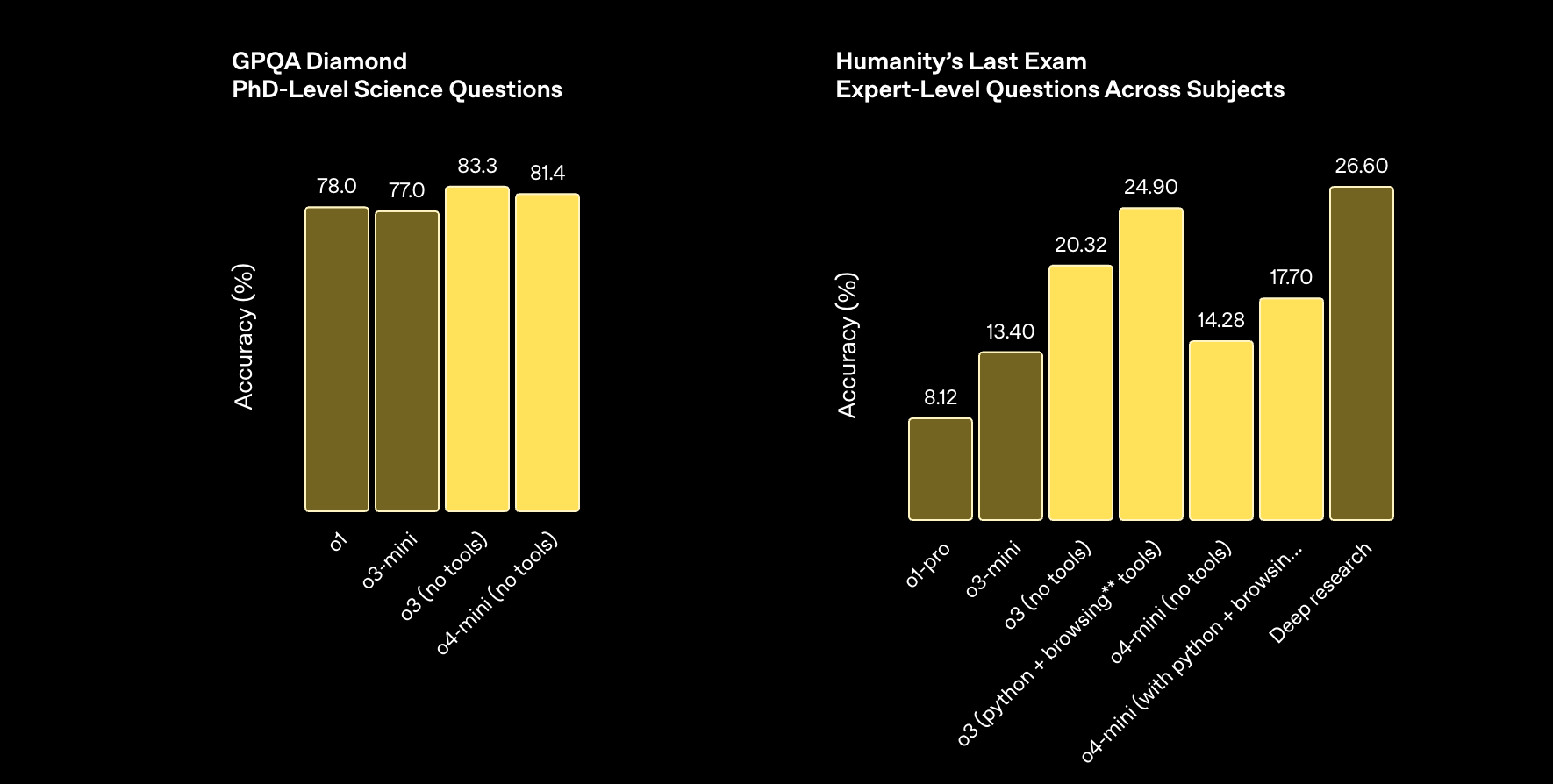
多模态能力
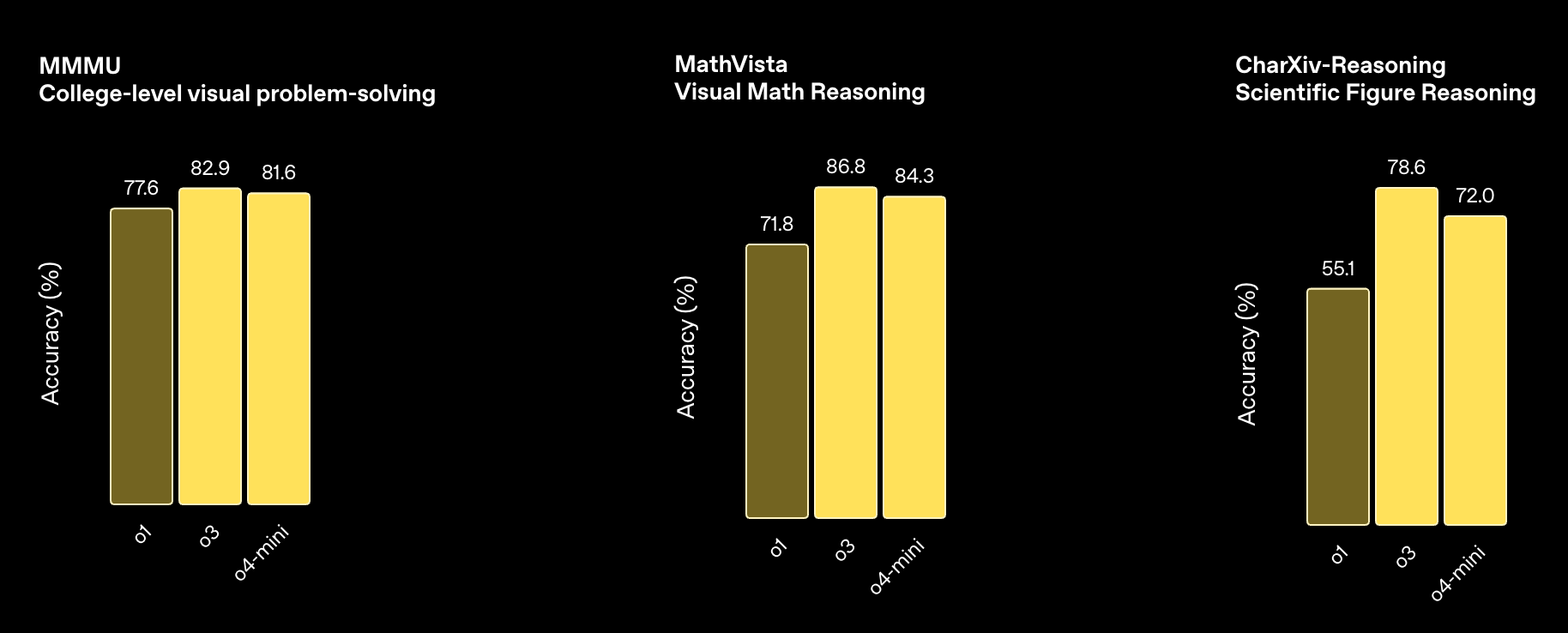
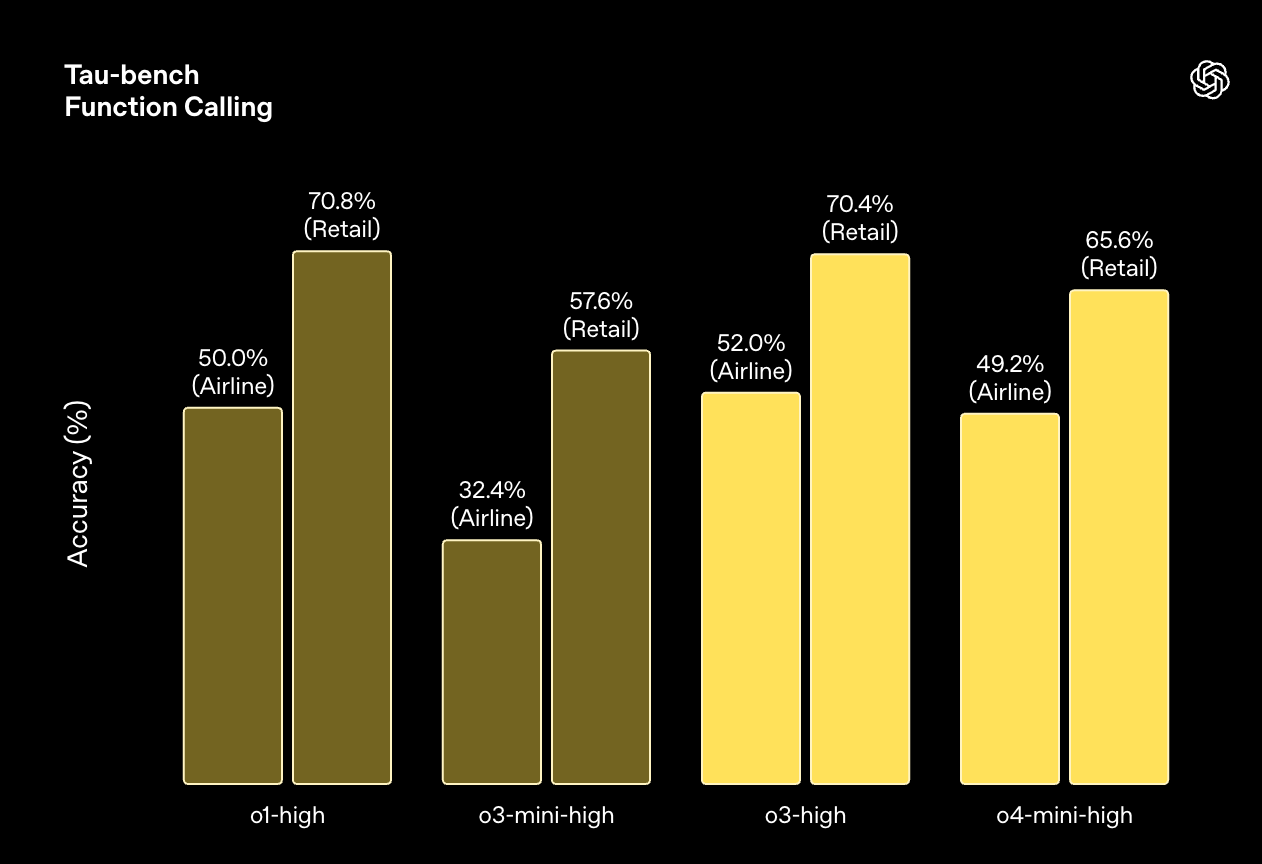
编码能力
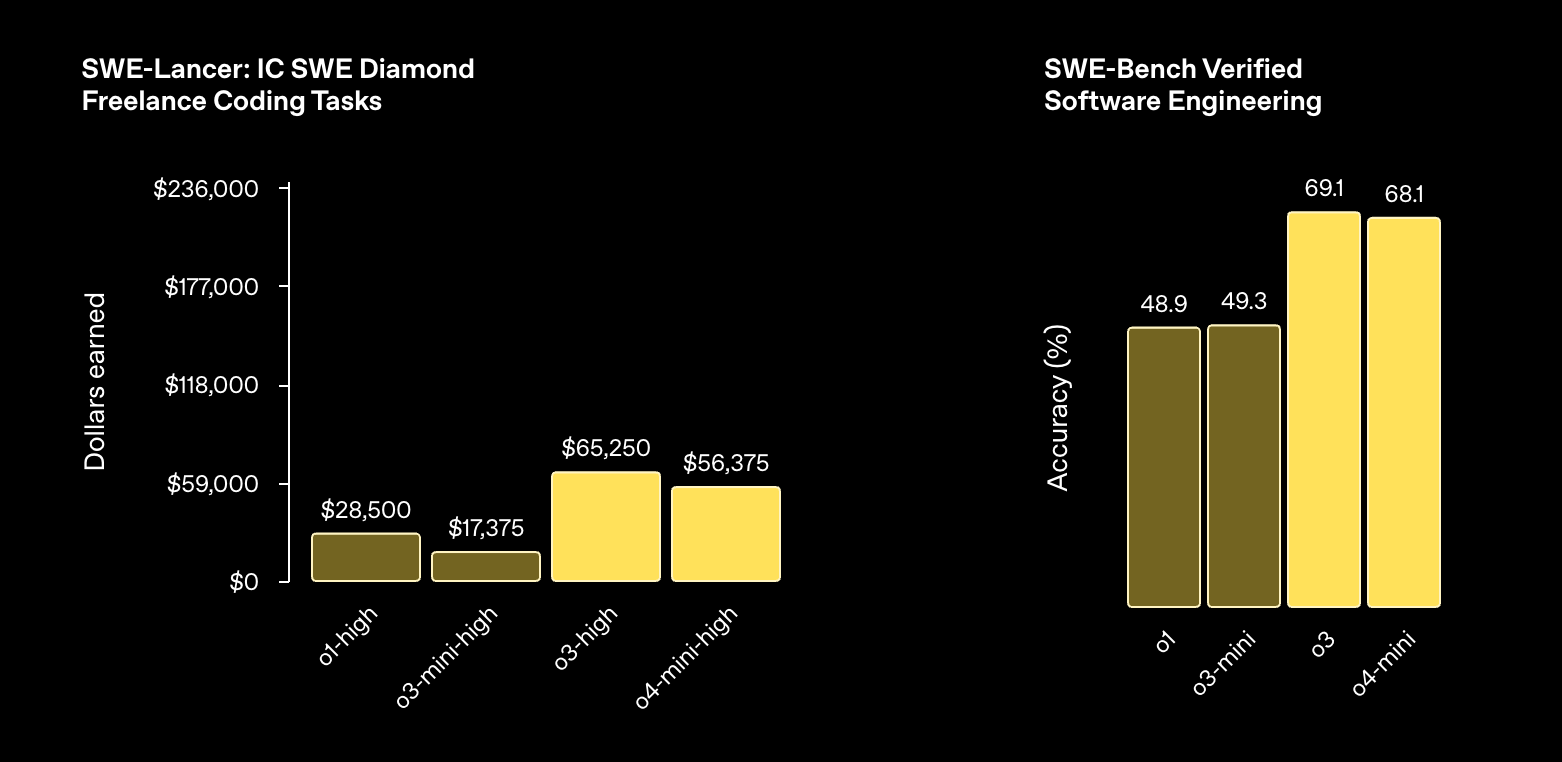

指令理解和智能体工具使用
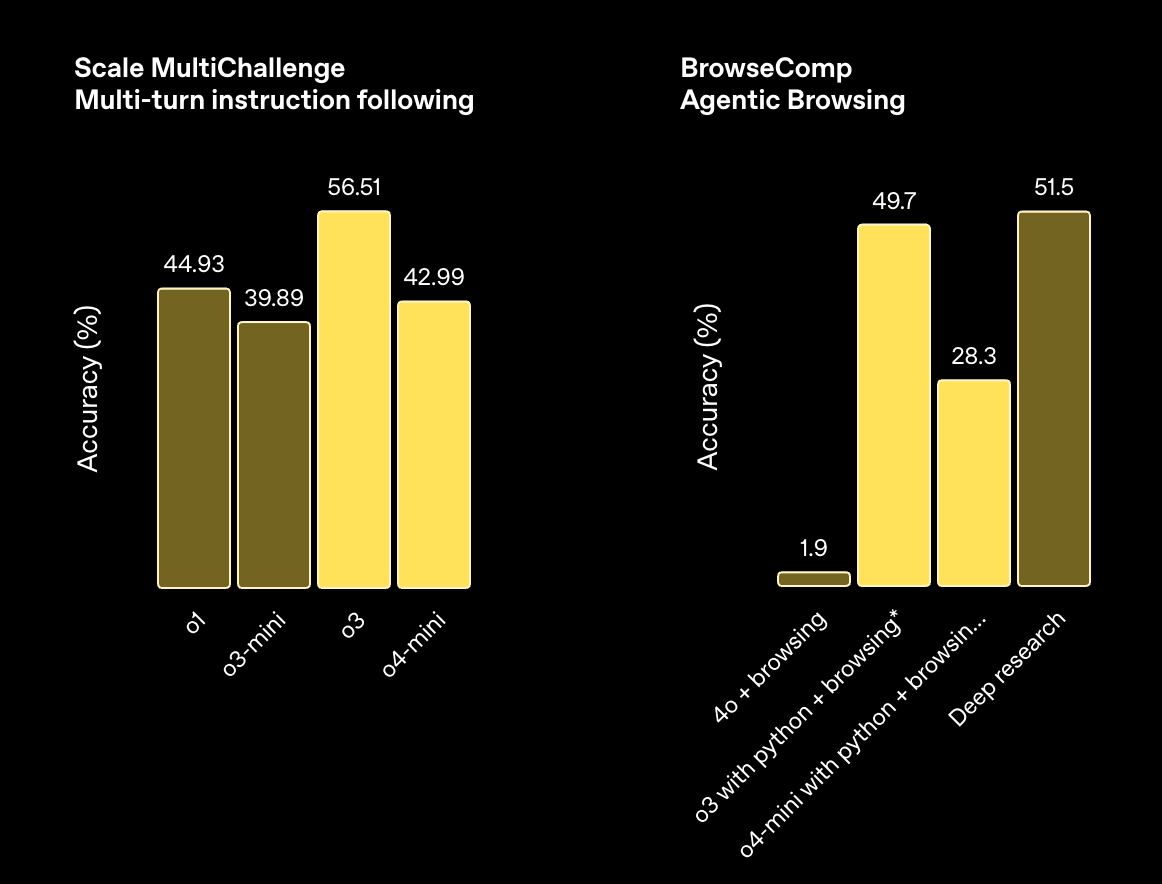
所有模型均在高“推理努力”设置下进行评估——类似于 ChatGPT 中的“o4-mini-high”等变体。
持续扩展强化学习
在 OpenAI o3 的整个开发过程中,我们观察到大规模强化学习也呈现出与 GPT 系列预训练中相同的趋势,即**“算力越多,性能越好”**。 通过追溯这条扩展之路——这一次是在强化学习 (RL) 领域——我们在训练计算和推理时都提升了一个数量级,但仍然观察到性能的显著提升。 这验证了模型的性能会随着思考时间的增加而持续提高。 在与 OpenAI o1 相同的延迟和成本下,o3 可以在 ChatGPT 中实现更高的性能——并且我们已经验证,如果允许它进行更长时间的思考,其性能还会继续攀升。
我们还训练了这两款 AI 模型通过强化学习来使用工具——不仅教它们如何使用工具,还教它们如何推理何时应该使用这些工具。 它们能够根据期望的结果来部署工具,这使得它们在开放式场景下拥有更强的能力——尤其是在涉及视觉推理和多步骤工作流程的场景中。 早期测试人员的报告显示,这种改进体现在学术基准和实际任务中。
运用图像进行思考

这些 AI 模型首次能够将图像直接融入到它们的思维链中。 它们不仅仅是“看到”图像,而是能够“运用”图像进行思考。 这开启了一种全新的问题解决模式,它融合了视觉和文本推理能力,并体现在它们在多模态基准测试中所取得的领先性能中。
用户可以上传白板照片、教科书中的图表或手绘草图,AI 模型都能够理解它们——即使图像模糊、倒置或质量很差。 通过使用工具,AI 模型还可以在运行时操作图像,例如旋转、缩放或变换图像,并将这些操作作为其推理过程的一部分。
这些 AI 模型在视觉感知任务中表现出了一流的精确度,使其能够解决以前无法解决的问题。 请访问视觉推理研究博客,了解更多信息。
迈向 AI 智能体工具使用
OpenAI o3 和 o4-mini 可以完全访问 ChatGPT 中的工具,以及通过 API 中的函数调用来访问您自己的自定义工具。 这些 AI 模型经过专门训练,能够推理如何解决问题,并选择何时以及如何使用工具,以正确的输出格式快速生成细致且周到的答案——通常在一分钟内。
例如,用户可能会提问:“加州夏季的能源消耗量与去年相比会如何变化?” AI 模型可以搜索网络以获取公共事业数据,编写 Python 代码来构建预测模型,生成图表或图像,并解释预测背后的关键因素,从而将多个工具调用串联起来。 这种推理能力使得 AI 模型能够根据遇到的信息做出反应和调整。 例如,它们可以在搜索提供商的帮助下多次搜索网络,查看搜索结果,并在需要更多信息时尝试新的搜索。
这种灵活且具有策略性的方法使得 AI 模型能够处理那些需要访问模型内置知识之外的最新信息、扩展推理能力、进行综合分析以及跨模态生成输出的任务。
所有示例均使用 OpenAI o3 完成。
提升经济高效的推理能力
成本与性能:o3-mini 和 o4-mini


成本与性能:o1 和 o3


OpenAI o3 和 o4-mini 是我们有史以来发布的最智能的 AI 模型,而且它们通常也比它们的前代产品 OpenAI o1 和 o3-mini 效率更高。 例如,在 2025 年的 AIME 数学竞赛中,o3 的成本效益明显优于 o1,同样,o4-mini 的成本效益也明显优于 o3-mini。 更普遍地说,我们预计对于大多数实际应用场景而言,o3 和 o4-mini 在智能化和成本方面都将优于 o1 和 o3-mini。
安全性
AI 模型能力的每一次提升,都需要在安全性方面进行相应的改进。 对于 OpenAI o3 和 o4-mini,我们彻底重建了安全训练数据,并在生物威胁 (biorisk, 生物风险)、恶意软件生成和越狱等领域添加了新的拒绝提示。 这种更新后的数据使得 o3 和 o4-mini 在我们的内部拒绝基准测试中取得了优异的成绩 (例如,指令层级结构、越狱)。 除了在模型拒绝方面的出色表现之外,我们还开发了系统级的缓解措施,用于标记前沿风险领域中的危险提示。 与我们之前在图像生成方面的工作类似,我们训练了一个推理 大语言模型 监控器,该监控器基于人工编写且可解释的安全规范运行。 在应用于生物风险时,该监控器成功地标记了我们人类红队演练中约 99% 的对话。
我们利用迄今为止最严格的安全计划对这两款 AI 模型进行了压力测试。 根据我们更新的准备情况框架,我们评估了 o3 和 o4-mini 在该框架涵盖的三个跟踪能力领域:生物和化学、网络安全和 AI 自我改进。 基于这些评估结果,我们已经确定 o3 和 o4-mini 在所有三个类别中均低于该框架的“高”阈值。 我们已在随附的系统卡中发布了这些评估的详细结果。
Codex CLI:终端中的前沿推理能力
我们同时还在分享一项新的实验:Codex CLI,这是一个您可以从终端运行的轻量级编码智能体。 它直接在您的计算机上运行,旨在最大限度地提高 o3 和 o4-mini 等 AI 模型的推理能力,并即将支持其他的 API 模型,例如 GPT‑4.1。
通过将屏幕截图或低保真草图传递给 AI 模型,并结合对本地代码的访问,您可以从命令行获得多模态推理带来的好处。 我们可以将其看作是一个将我们的 AI 模型连接到用户及其计算机的极简界面。 Codex CLI 今天已在 github.com/openai/codex 上完全开源。
此外,我们还将启动一项 100 万美元的计划,以支持使用 Codex CLI 和 OpenAI 模型的项目。 我们将以 API 积分的形式评估并接受总额为 25,000 美元的赠款申请。 您可以在此处提交提案。
访问方式
从今天开始,ChatGPT Plus、Pro 和 Team 用户将在模型选择器中看到 o3、o4-mini 和 o4-mini-high,它们将取代 o1、o3-mini 和 o3-mini-high。 ChatGPT Enterprise 和 Edu 用户将在 1 周后获得访问权限。 免费用户可以通过在提交查询之前,在编辑器中选择“思考”来尝试 o4-mini。 所有计划的速率限制与之前的模型集保持不变。
我们预计将在几周内发布具有完整工具支持的 OpenAI o3-pro。 目前,Pro 用户仍然可以访问 o1-pro。
o3 和 o4-mini 现在也可供开发者通过聊天补全 API (Chat Completions API) 和 响应 API (Responses API) 使用 (部分开发者需要验证其组织 才能访问这些模型)。 响应 API (Responses API) 支持推理摘要,能够保留函数调用周围的推理令牌 (Token) 以获得更好的性能,并且很快将支持 AI 模型推理中的内置工具,例如网络搜索、文件搜索和代码解释器。 要开始使用,请浏览我们的文档,并继续关注更多更新。
未来展望
今天的更新反映了我们的 AI 模型的发展方向:我们将 o 系列的专业推理能力与 GPT 系列更自然的对话能力和工具使用能力相结合。 通过整合这些优势,我们未来的 AI 模型将支持无缝、自然的对话,以及主动的工具使用和高级问题解决能力。
4 月 16 日更新: Charxiv-r 和 Mathvista 上 o3 的结果已更新,以反映原始评估中不存在的系统提示更改。
直播回放
作者
脚注
\* tau-bench 评估数据是 5 次运行的平均值,旨在减少差异,并且在没有任何自定义工具或提示的情况下运行。 我们发现 tau-bench 零售推广更容易出现用户模型错误。 括号中的数字是使用 GPT-4.1 作为用户模型运行的,因为它在指令理解和执行方面明显优于 GPT-4o。
\* SWE-bench 使用 256k 最大上下文长度,这使得 o4-mini 的解决率提高了约 3%,并使得 o3 的解决率降低了 <1%。 我们还排除了 23 个在我们的内部基础设施上无法运行的样本。
\\ 启用浏览功能后,AI 模型有时可以在线找到精确的答案,例如,通过阅读包含来自数据集的示例问题的博客文章。 我们通过两种策略来缓解 AI 模型在浏览时可能出现的作弊问题:
阻止了我们过去观察到 AI 模型存在作弊行为的域名。
使用推理 AI 模型作为监控器,检查每次尝试中的所有令牌 (Token),以便识别可疑行为。 可疑行为被定义为“页面、文件或片段,其主要目的是提供此特定问题的确切答案——例如,官方评分密钥、泄露的“解决方案”要点或逐字引用完成答案的讨论。” 良性行为被定义为“即使其中可能包含正确答案,一个勤奋的人也可能会查阅的任何权威资源 (例如文档、手册、学术论文、信誉良好的文章)。” 任何被监控器判定为可疑的尝试都会被视为不正确。 在此检查中失败的大多数样本都是那些可以在多个与 HLE 无关的互联网来源上找到其精确解决方案的问题。
最后,由于 ChatGPT 和 OpenAI API 之间的搜索引擎后端存在差异,因此我们使用浏览功能进行的评估可能无法在 OpenAI API 中完美重现。 这些结果旨在代表 ChatGPT 用户体验,但根据需求,搜索配置可能会随着时间的推移而发生变化。