OpenAI 于 2025年 3 月 20日 发布新一代语音转文本模型和文本转语音模型,这些新模型包括语音转文本 (speech-to-text) 和文本转语音 (text-to-speech) 模型,它们在性能、准确性和可定制性方面均有显著提升,为构建更自然、更有效的语音交互应用提供了有力支持。特别是,新的语音转文本模型在准确性和可靠性方面达到了新的行业标杆,尤其在处理口音、噪音环境和不同语速等复杂场景时表现更佳。同时,文本转语音模型首次允许开发者指导模型以特定的方式说话,从而实现更高程度的个性化和更丰富的应用场景。
- 新一代语音转文本模型: 推出了
gpt-4o-transcribe和gpt-4o-mini-transcribe模型,相较于原有的 Whisper 模型,在词错误率 (Word Error Rate, WER) 上有显著改进,语言识别和准确性更高。在 FLEURS 基准测试中,这些新模型在多种语言上都展现出更低的 WER,表明其转录准确性和多语言覆盖能力更强。 - 新一代文本转语音模型: 推出了
gpt-4o-mini-tts模型,该模型最大的亮点是其可指导性 (steerability),开发者可以指示模型不仅说什么,还可以指定 如何 说,例如模仿 “富有同情心的客服人员” 的语气。这为客户服务、创意故事叙述等应用场景带来了更丰富的可能性。 - 技术创新: 这些模型的性能提升得益于多项技术创新,包括:
- 使用真实的音频数据集进行预训练 (Pretraining with authentic audio datasets): 模型基于 GPT‑4o 和 GPT‑4o-mini 架构,并在专门的音频数据集上进行了广泛的预训练,从而更深入地理解语音的细微差别。
- 先进的知识蒸馏方法 (Advanced distillation methodologies): 通过增强的知识蒸馏技术,将大型音频模型的知识转移到更小、更高效的模型中,利用自博弈 (self-play) 方法捕捉真实的对话动态。
- 强化学习范式 (Reinforcement learning paradigm): 语音转文本模型集成了强化学习,显著提高了转录的准确性,降低了幻觉 (hallucination),使其在复杂的语音识别场景中更具竞争力。
- API 可用性: 这些新的音频模型已在 API 中向所有开发者开放,并与 Agents SDK 集成,方便开发者构建语音助手应用。对于需要低延迟语音对话的应用,推荐使用 Realtime API 中的 speech-to-speech 模型。
- 未来展望: 未来将继续投入于提升音频模型的智能性和准确性,探索允许开发者使用自定义声音的方法,并拓展到视频等多模态领域。同时,将继续与政策制定者、研究人员等就合成语音的挑战和机遇进行对话。
原文:在 API 中引入下一代音频模型
我们推出了一系列全新的音频模型,为语音 AI 智能体 (AI Agent) 提供强大支持,现在全球开发者均可使用。
过去几个月,我们不断投入,致力于提升基于文本的 AI 智能体的智能性、能力和实用性。我们相继发布了 Operator、Deep Research、Computer-Using Agents 以及内置工具的 Responses API 等产品,旨在让 AI 智能体 (AI Agent) 能够代表用户独立完成任务。然而,要使 AI 智能体 (AI Agent) 真正发挥作用,人们需要与它们进行更深入、更直观的交互,而不仅仅局限于文本,而是通过自然的口语进行有效沟通。
今天,我们将在 API 中推出全新的语音转文本 (speech-to-text) 和文本转语音 (text-to-speech) 音频模型,助力开发者构建更强大、可定制且更智能的语音 AI 智能体 (AI Agent),从而提供真正的价值。我们最新的语音转文本 (speech-to-text) 模型树立了新的行业标杆,在准确性和可靠性方面均优于现有解决方案,尤其是在口音浓重、环境嘈杂或语速多变等具有挑战性的场景中表现更为出色。 这些改进提升了转录的可靠性,使这些模型尤其适合客户呼叫中心、会议纪要转录等应用场景。
此外,开发者还可以首次“指示”文本转语音 (text-to-speech) 模型以特定方式发声,例如“用富有同情心的客服的语气说话”,从而为语音 AI 智能体 (AI Agent) 开启更高层次的定制空间。 这将催生更广泛的定制化应用,从更富同情心和更具活力的客服语音,到用于创意故事讲述的富有表现力的叙述,各种应用场景都将成为可能。
自 2022 年推出首个音频模型 2022 以来,我们始终致力于提高这些模型的智能性、准确性和可靠性。 借助这些全新的音频模型,开发者可以在 API 中构建更准确、更强大的语音转文本 (speech-to-text) 系统,以及更具表现力和鲜明个性的文本转语音 (text-to-speech) 声音。
更多关于我们最新的音频模型
全新的语音转文本模型
我们推出了新的 gpt-4o-transcribe 和 gpt-4o-mini-transcribe 模型。与初代 Whisper 模型相比,这些模型在词错误率 (Word Error Rate, WER) 方面有所改进,并且具有更出色的语言识别能力和准确性。
gpt-4o-transcribe 在多个已建立的基准测试中,展现出比现有 Whisper 模型更优异的词错误率 (Word Error Rate, WER) 性能,充分体现了我们在语音转文本 (speech-to-text) 技术方面取得的显著进展。 这些进步直接源于在强化学习 (Reinforcement Learning) 方面进行有针对性的创新,以及使用多样化的高质量音频数据集进行的大规模中期训练。
因此,这些全新的语音转文本 (speech-to-text) 模型能够更好地捕捉语音中的细微差别,减少错误识别,并提高转录的可靠性,尤其是在口音浓重、环境嘈杂或语速多变等具有挑战性的场景中。 这些模型现已在 语音转文本 API 中提供。
最新语音转文本模型在 FLEURS 上的转录错误减少
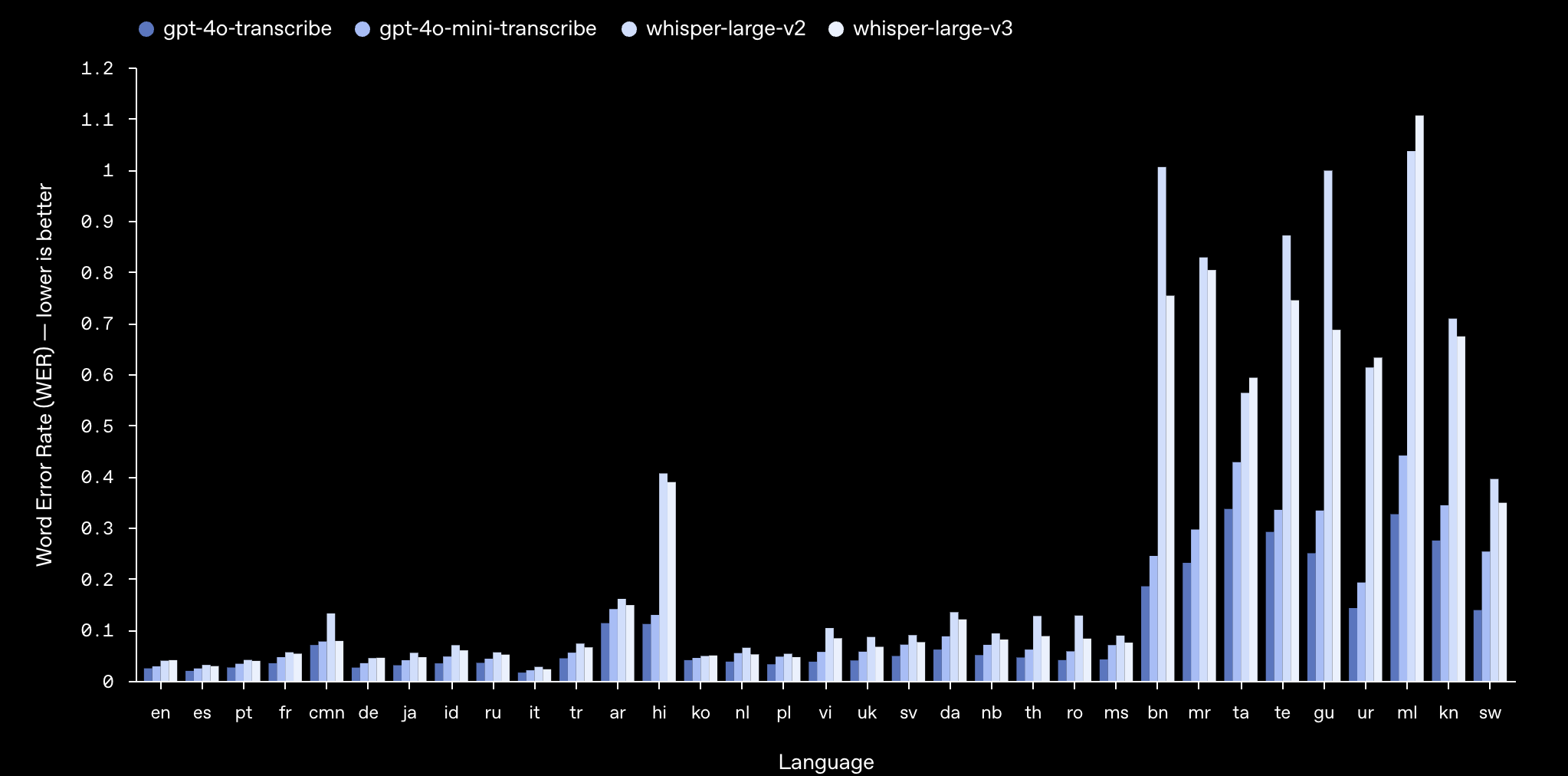
词错误率 (Word Error Rate, WER) 用于衡量语音识别模型的准确性,其计算方式为:将不正确转录的词数与参考文本中的词数进行比较,得出一个百分比。WER 越低,代表错误越少,模型准确性越高。 我们最新的语音转文本 (speech-to-text) 模型在包括 FLEURS (Few-shot Learning Evaluation of Universal Representations of Speech,语音通用表示的少样本学习评估) 在内的各项基准测试中,均实现了更低的 WER。FLEURS 是一个多语种语音基准,它使用了人工转录的音频样本,覆盖了 100 多种语言。 这些结果表明,我们的模型具有更强的转录准确性和更广泛的语言覆盖范围。 如图所示,在所有语言评估中,我们的模型始终优于 Whisper v2 和 Whisper v3。
FLEURS 上领先模型的词错误率比较
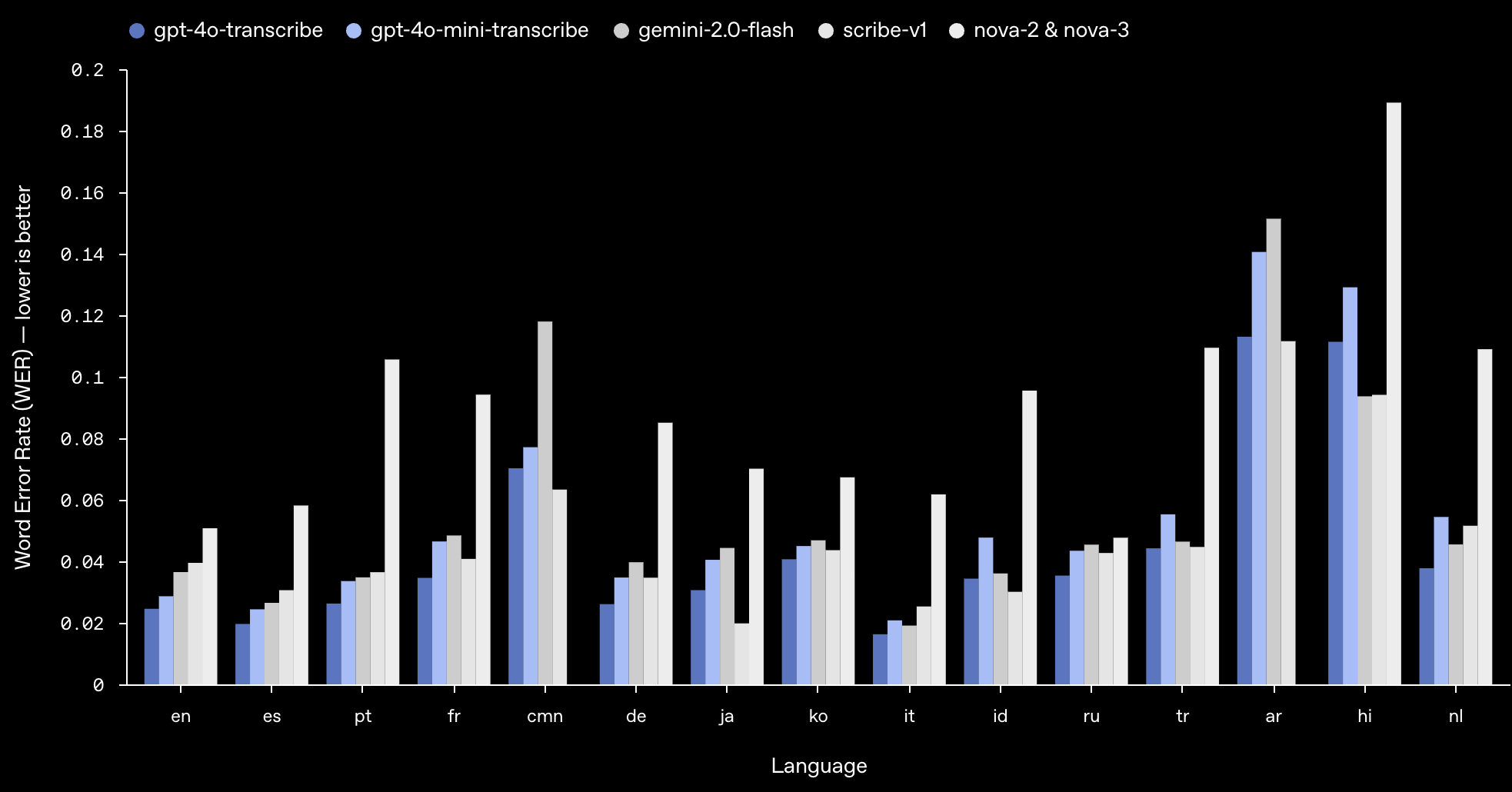
在 FLEURS 基准测试中,我们的模型实现了更低的 WER,并展现出强大的多语言性能。WER 越低越好,意味着错误越少。 如图所示,我们的模型在大多数主要语言中,与其他的领先模型表现持平,甚至更胜一筹。
全新的文本转语音模型
我们还推出了一个新的 gpt-4o-mini-tts 模型,它具有更好的可操纵性。 开发者可以首次“指示”模型不仅要说什么,还要_如何_说,从而为从客户服务到创意故事讲述等各种应用场景提供更加定制化的体验。 该模型已在 文本转语音 API 中上线。 请注意,这些文本转语音 (text-to-speech) 模型仅限于人工预设的声音,并且我们会对它们进行监控,以确保它们始终与合成预设保持一致。
模型背后的技术创新
使用真实的音频数据集进行预训练
我们的全新音频模型构建于 GPT‑4o 和 GPT‑4o-mini 架构之上,并使用专门的、以音频为中心的数据集进行了广泛的预训练。这对于优化模型性能至关重要。 这种有针对性的方法能够帮助我们更深入地了解语音的细微之处,并确保模型在执行各种音频相关任务时,都能达到卓越的性能水平。
先进的“知识蒸馏”方法
我们改进了“知识蒸馏”技术,从而能够将知识从最大的音频模型转移到更小、更高效的模型中。 通过利用先进的“自博弈”方法,我们的“知识蒸馏”数据集能够有效地捕捉真实的对话动态,并复制真实的用户与助手之间的互动。 这有助于我们较小的模型提供出色的对话质量和响应能力。
强化学习范式
对于我们的语音转文本 (speech-to-text) 模型,我们采用了一种侧重强化学习 (Reinforcement Learning, RL) 的模式,将转录准确性推向了前所未有的水平。 这种方法能够显著提高精度,并减少“幻觉”现象,从而使我们的语音转文本 (speech-to-text) 解决方案在复杂的语音识别场景中具有非凡的竞争力。
这些技术进步代表了音频建模领域的巨大进步,它们将创新方法与实际的性能提升相结合,从而增强了语音应用的用户体验。
API 可用性
所有开发者现在都可以使用这些全新的音频模型。有关使用音频构建应用的更多信息,请访问 此处。 对于已经使用基于文本的模型构建对话体验的开发者来说,添加我们的语音转文本 (speech-to-text) 和文本转语音 (text-to-speech) 模型是构建语音 AI 智能体 (AI Agent) 最简单的方法。 我们正在发布与 AI 智能体 SDK (AI Agent SDK) Agents SDK 的集成,以简化开发过程。 对于希望构建低延迟语音转语音体验的开发者,我们建议在 Realtime API 中使用我们的语音转语音模型进行构建。
接下来是什么
展望未来,我们计划继续投入,以提高音频模型的智能性和准确性,并探索允许开发者引入自定义语音的方法,从而按照我们的安全标准构建更加个性化的体验。 此外,我们还将继续与政策制定者、研究人员、开发者和创意人员进行对话,共同探讨合成语音可能带来的机遇与挑战。 我们非常期待开发者能够利用这些增强的音频功能,构建出各种创新和充满创意的应用。 我们还将投资于包括视频在内的其他模态,从而使开发者能够构建多模态的 AI 智能体 (AI Agent) 体验。
直播回放
作者
研究主管
Christina Kim, Junhua Mao, Yi Shen, Yu Zhang
贡献者
研究
Alex Paino, Bowen Cheng, Chengxu Zhuang, Chris Koch, Damian Mrowca, Erik Ritter, Jacob Menick, James Betker, Ji Lin, Jamie Kiros, Jiahui Yu, Liang Zhou, Liyu Chen, Kevin Lu, Madeline Boyd, Michael Lampe, Mike Heaton, Nanxin Chen, Nitish Keskar, Saachi Jain, Sam Toizer, Somay Jain, Tao Xu, Tomer Kaplan, Wei Han, Xiangning Chen, Ye Jia
工程
Alina Wu, Andres Garcia Garcia, Arshi Bhatnagar, Avital Oliver, Brendan Quinn, Christina Huang, David Fang, Dragos Oprica, Dominik Kundel, Iaroslav Tverdokhlib, Jiacheng Feng, Jay Chen, Jenia Varavva, Jordan Sitkin, Joseph Florencio, Lien Mamitsuka, Mada Aflak, Manoli Liodakis, Mark Hudnall, Noah MacCallum, Ola Okelola, Peter Bakkum, Rohan Mehta, Romain Huet, Wanning Jiang, Wayne Chang, Yilei Qian
产品
Anubha Srivastava, Jackie Shannon, Jeff Harris, Reah Miyara, Xiaolin Hao
领导赞助商
Aidan Clark, Andrew Gibiansky, David Sasaki, Kevin Weil, Liam Fedus, Mark Chen, Nick Ryder, Nick Turley, Olivier Godement, Prafulla Dhariwal, Shengjia Zhao, Shuchao Bi, Sherwin Wu, Sulman Choudhry