文本来自于 Jason Wei 在斯坦福 AI 俱乐部上的分享。Jason Wei 是一位杰出的 AI 研究员,目前在 Meta Superintelligence 实验室工作。在加入 Meta 之前,Jason 帮助在 OpenAI 共同创建了 o1 模型和 Deep Research 产品。他也是思维链 (Chain of Thought) 推理的发明者之一,并在 Google Brain 记录了关于涌现现象的重要研究。
当我们谈论AI将如何改变世界时,常常会听到两种截然不同的声音。一边是我那位做量化交易的朋友,他觉得ChatGPT虽然酷,但离他工作中真正需要的复杂技能还差得远。另一边,一位顶尖AI实验室的研究员却告诉我,他觉得我们人类“打工人”的好日子可能只剩下两三年了。
巨大的认知差异背后,是我们对AI本质理解的偏差。
Jason Wei,这位曾在Google Brain推动了“思维链(Chain of Thought)”、在OpenAI共同创造了Q*和深度研究(Deep Research)、如今在Meta超级智能实验室工作的AI大牛,为我们提供了一个更清晰的思考框架。他认为,要看清2025年乃至未来的AI图景,你只需要理解三个简单又深刻的观点。
这三个观点,就像三把钥匙,能帮我们打开对AI未来的认知大门,看清哪些是触手可及的现实,哪些又是遥远的幻想。
趋势一:智能将变得像水电一样,随取随用
想象一下,AI的发展有两个阶段。
第一阶段是“开疆拓土”。在这个阶段,AI还无法很好地完成某项任务,研究人员的目标是努力解锁新能力。就像我们在过去几年看到的,AI在MMLU(一个衡量多任务语言理解能力的通用基准)上的得分逐年攀升,这就是在不断拓展能力的边界。
第二阶段则是“商品化”。一旦某个能力被AI攻克,获取这项能力的成本就会急剧下降,最终趋近于零。我们可以看到一个清晰的趋势:要达到MMLU某个固定的分数,每一年所需要花费的计算成本(美元)都在断崖式下跌。
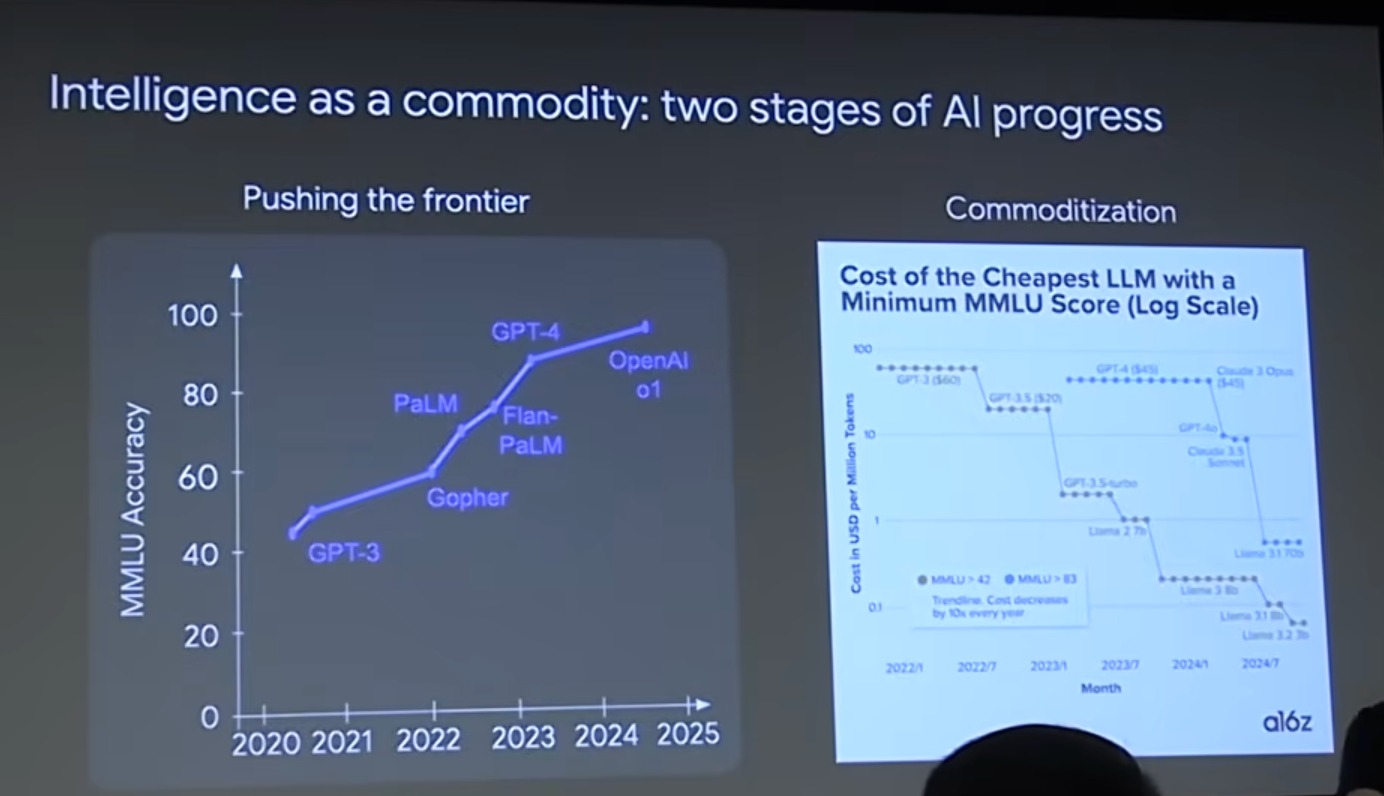
为什么这个趋势会持续下去?一个关键原因是**“自适应计算”(Adaptive Compute)**的成熟。在过去,无论问题多简单(比如“加州的首都是哪里?”)还是多复杂(比如一道奥数题),模型处理它花费的计算量基本是固定的。但现在,我们可以根据任务的难度动态调整计算资源。简单的任务用小模型或少量的计算就能解决,这使得“智能”的成本可以无限逼近于零。
这个趋势最直接的体现,就是**“即时知识”**的实现。获取公开信息的门槛正在被彻底踏平。
不妨用一个例子来感受一下:
问题1:1983年釜山的人口是多少?
- 前互联网时代:你可能得花几小时开车去图书馆,翻阅一堆百科全书。
- 互联网时代:几分钟的搜索和网页浏览。
- 聊天机器人时代:几乎是瞬间得到答案。
问题2:1983年釜山有多少对新人结婚?
- 前互联网时代:这可能需要你飞到韩国,去政府档案馆翻阅几十本尘封的记录簿,耗时数周。
- 互联网时代:如果你不懂韩语,可能要在无数网站中大海捞针,花上好几个小时。
- AI智能体时代:像OpenAI的Operator这样的工具,可以通过访问KOSIS(韩国统计信息服务)数据库,经过一系列点击和查询,在几分钟内找到答案。
问题3:1983年,亚洲人口最多的30个城市,按当年的结婚数量排序?
- 前互联网时代:这几乎是个不可能完成的任务,可能需要耗费数月甚至几年。
- AI智能体时代:虽然现在可能还需要几小时,但已经从“不可能”变成了“可能”。
这对我们意味着什么?
- 知识壁垒的消融:像编程、个人健康管理这些过去因知识门槛而显得“高大上”的领域,将被大众化。以前你想搞点“生物黑客”实验,医生可能只会给你一些标准建议;现在,ChatGPT能给你提供不亚于一个优秀医生的专业信息。
- 私人信息的价值提升:当所有公开信息的获取成本都趋近于零时,那些未公开的、私人的、内幕的信息(比如市场上还没挂出来的待售房源)的相对价值就会飙升。
- 个性化互联网的到来:未来,我们访问的可能不再是千人一面的公共互联网,而是一个为你量身定制的、能即时解答你任何疑问的“私人互联网”。
趋势二:验证者定律——AI能做什么,取决于我们能多容易地评判它
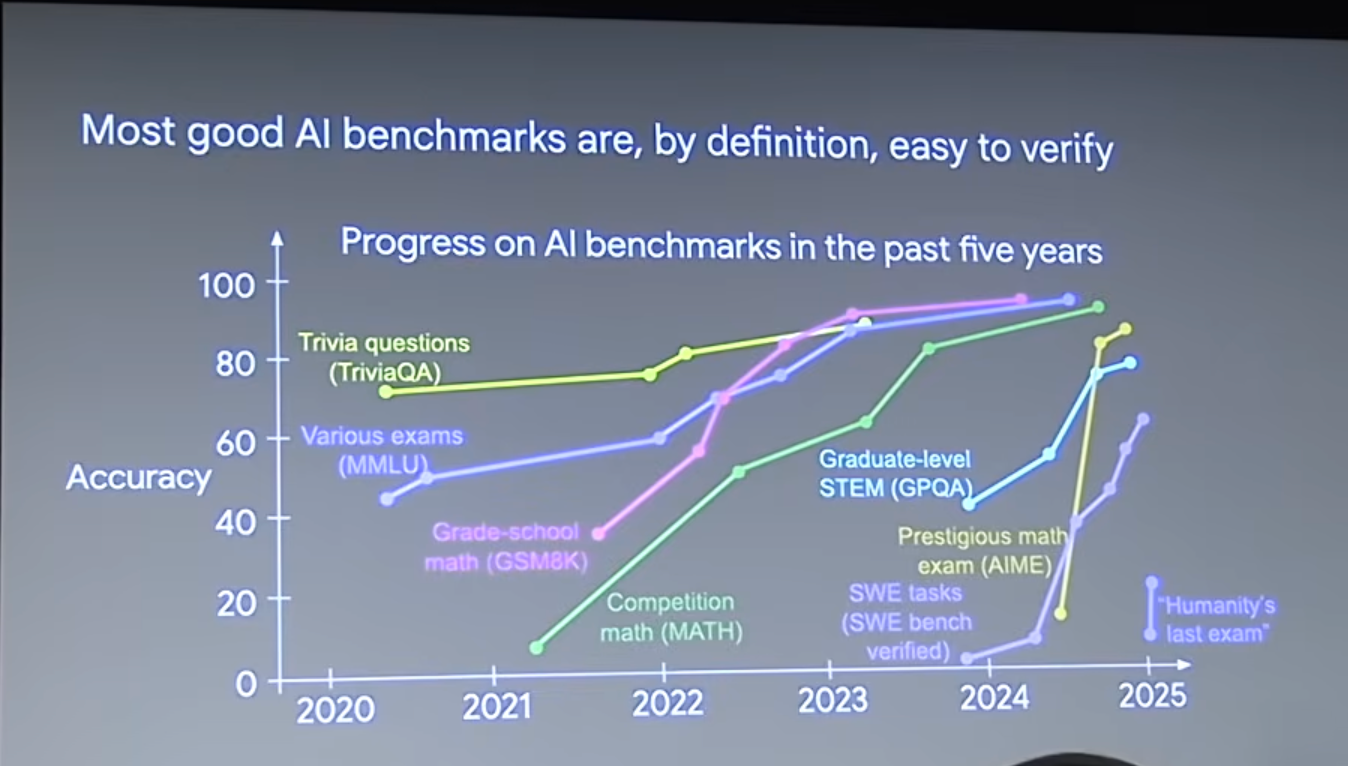
在计算机科学中,有一个很经典的概念叫**“验证不对称性”**(Asymmetry of Verification),说白了就是:对于某些任务,验证一个答案是否正确,远比从零开始找出这个答案要容易得多。
我们可以把各种任务放到一个二维坐标系里,X轴代表“生成难度”,Y轴代表“验证难度”:
- 数独:生成(解决)很难,但验证(检查)非常容易。
- 编写Twitter的代码:生成极其困难(需要数千工程师),但验证相对简单(打开网站点几下看看功能是否正常)。
- 奥数题:有时生成和验证的难度差不多。
- 写一篇充满事实的论文:生成一篇看起来煞有其事的文章很容易,但要逐一核实每个事实(Fact-checking)却极其耗时和困难。
- 提出一种新的饮食法:我花10秒钟就能声称“只吃野牛是最好的饮食法”,但要科学地验证这个说法的真伪,可能需要长达数十年的大规模、低噪音的实验。

基于此,Jason提出了一个他称之为**“验证者定律”(Verifier’s Law)**的观点:
我们训练AI解决某个任务的能力,与我们能多容易地验证该任务的成果成正比。任何一个可被轻易、快速、准确验证的任务,最终都将被AI攻克。
什么叫“容易验证”?它通常包含以下几个要素:
- 客观性:有明确的对错标准。
- 速度快:能迅速判断结果好坏。
- 可扩展:能同时并行验证成千上万个结果。
- 低噪音:每次验证的结果都一样,不会变来变去。
- 连续奖励:不仅能判断“通过/不通过”,还能给出“好一点”或“差一点”的量化评分。
DeepMind的AlphaEvolve就是利用这个定律的绝佳案例。他们选择了一些像“如何用11个六边形拼成一个能被最小外部六边形包裹的形状”这类问题。这类问题生成答案很难,但验证非常容易(计算一下外部六边形的面积就行)。
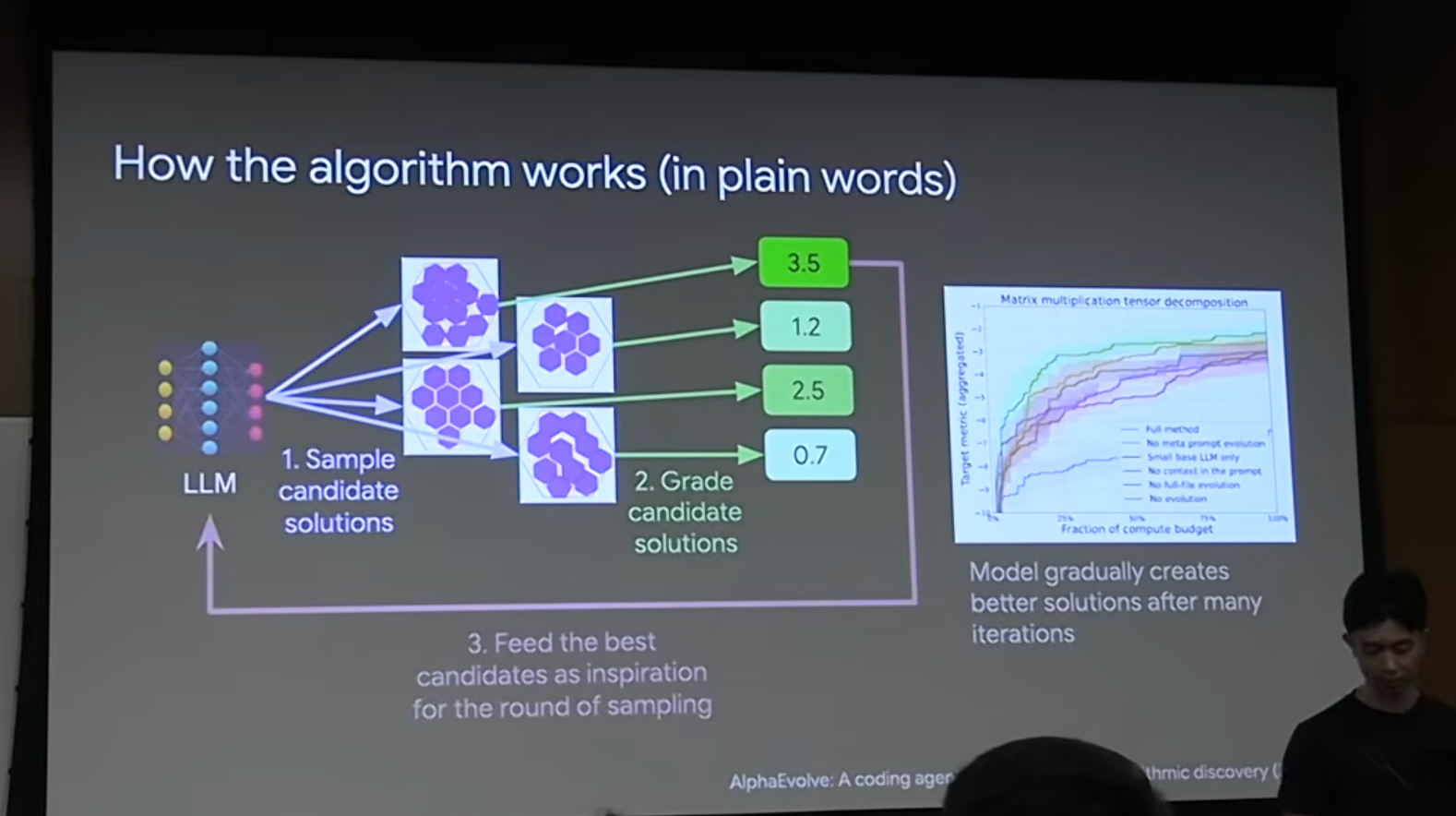
AlphaEvolve的算法大致是:
- 用大语言模型生成一大堆候选解决方案。
- 用一个客观的评分程序(验证器)给所有方案打分。
- 把最高分的方案作为“灵感”和“榜样”,再喂给模型,让它在下一轮生成更好的方案。
- 不断重复这个“生成-验证-反馈”的循环。
通过投入巨大的算力进行迭代,AI最终找到了比人类已知最优解还要好的答案。它们巧妙地绕开了“泛化”这个难题,专注于解决一个“训练和测试是同一个问题”的特定场景。
这对我们意味着什么?
- 最先被自动化的工作:那些工作成果极易被量化和验证的岗位,将是第一批被AI深刻改变的。
- “丈量世界”的价值:创造新的、更精准的“度量衡”本身,将成为一个巨大的商业机会。因为一旦某样东西可以被衡量,它就可以被AI优化。
趋势三:智能的锯齿边界——告别“奇点”幻想,AI的发展并不均衡
很多人担心一个“快速起飞”(Fast Takeoff)或“智能爆炸”的场景:AI在某一天跨过某个临界点,突然在所有方面都远超人类。
Jason认为,这种情况大概率不会发生。
AI的自我提升,不会是一个“昨天还不行,今天突然就可以了”的二进制开关。它更可能是一个渐进的过程:
- 第1年,AI连训练代码都跑不起来。
- 第2年,AI可以自主训练了,但效果还不如人类顶尖研究员。
- 第3年,AI可以做得和人类一样好,但偶尔还需要人工干预一下。
- …
更重要的是,AI的能力版图并不是一块平滑的、齐头并进的面板,而是一条**“锯齿状的边界”(Jagged Edge of Intelligence)**。
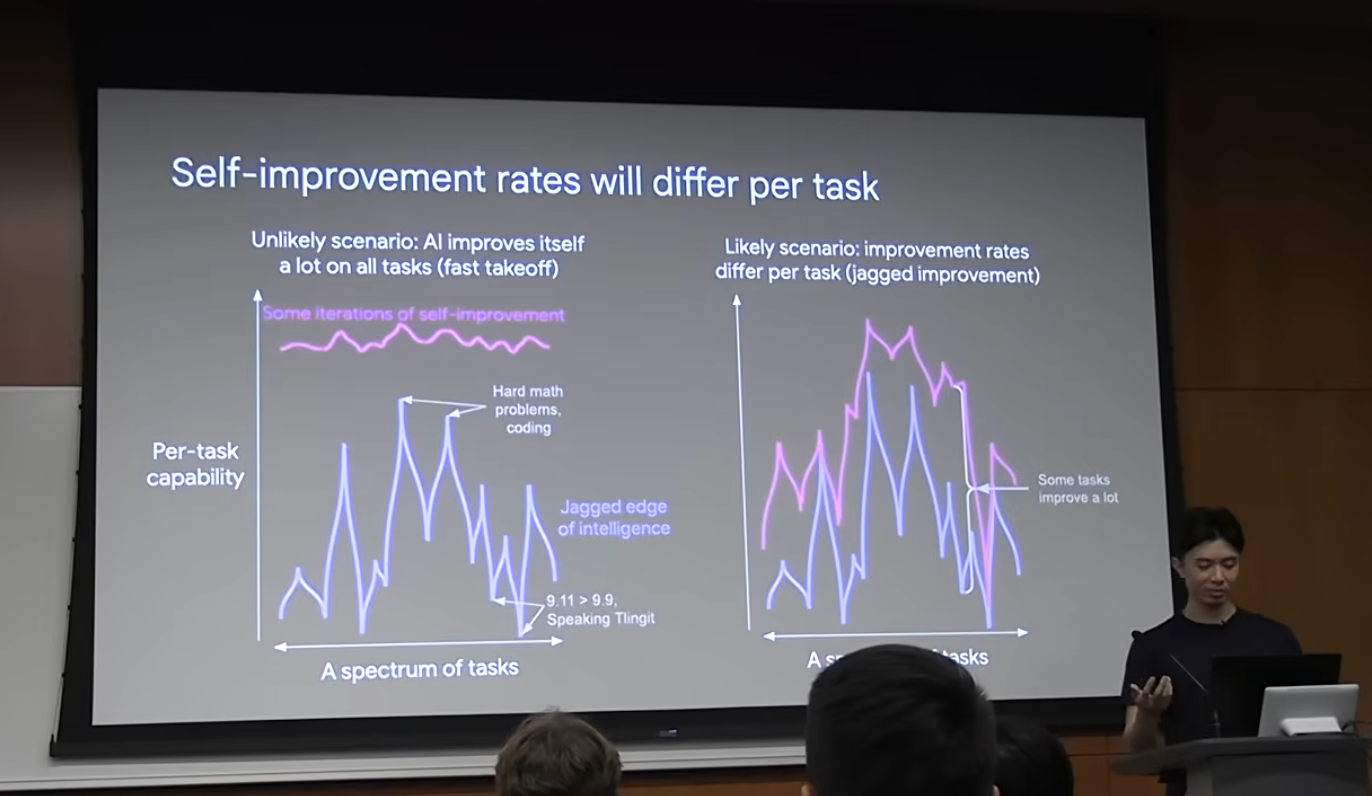
在这条边界上,有高耸的山峰,也有深邃的峡谷:
- 山峰:AI已经表现超群的领域,比如复杂的数学题、部分编程竞赛。
- 峡谷:AI依然表现很差的领域,比如那些只有几百人使用的濒危语言(如特林吉特语),或者是一些非常微妙的人类常识问题(比如很长一段时间里,ChatGPT都认为9.11比9.9大)。
AI的进步更像是右图的样子:不同任务的提升速度完全不同。那些容易验证、数据充足的任务(比如数学和编程)会飞速攀升;而那些受限于物理世界、数据稀缺的任务(比如学习特林吉特语,这需要有人去印第安人保留地做实地记录),进步速度会慢得多。
那么,如何预测AI在某个特定任务上的进步速度呢?Jason给出了几个简单的经验法则:
- 数字世界 vs. 物理世界:AI在纯数字任务上进步神速,因为迭代速度极快。而在需要与物理世界交互的机器人领域,每一次实验都受限于物理定律和现实环境,迭代速度慢得多。
- 数据丰富度:数据越多的地方,AI就越强。一个清晰的例子是,AI在不同语言上的数学能力,与其训练数据中该语言的语料数量呈明显的正相关。
- 人类难度:通常对人类来说越容易的任务,对AI也越容易(当然也有例外)。
基于这几个法则,Jason风趣地给出了一个未来AI能力达成时间的预测表:
| 任务 | 人类难度 | 数字任务 | 数据易得性 | AI搞定时间预测 |
|---|---|---|---|---|
| 翻译全球Top50语言 | 容易 | 是 | 是 | 已完成 |
| 调试基础代码 | 中等 | 是 | 是 | ~2023 |
| 竞赛级数学题 | 困难 | 是 | 是 | ~2024 |
| 进行AI研究 | 困难 | 是 | 较难 | ~2027 |
| 进行化学研究 | 困难 | 否(需实验) | 较难 | >2027 |
| 制作一部电影 | 非常困难 | 是 | 是 | ~2029 |
| 预测股市 | 非常困难 | 是 | 是 | ? (天知道) |
| 翻译特林吉特语 | 困难 | 是 | 否 | 可能性很低 |
| 修理你家的水管 | 中等 | 否 | 不一定 | 很久以后 |
| 理发 | 中等 | 否 | 否 | 非常困难 |
| 织一张波斯地毯 | 非常困难 | 否 | 否 | 短期内没戏 |
| 带女友去一次她满意的约会 | 不可能 | 否 | 否 | 别想了 |
这对我们意味着什么?
这份有趣的表格揭示了一个深刻的道理:AI的影响将极不均衡。软件开发等纯数字领域会被AI彻底颠覆和加速,而像理发、管道维修这类与物理世界深度绑定的手艺活,在很长一段时间内可能都不会受到太大影响。
结语
所以,我们该如何看待AI的未来?
Jason Wei的这三个观点——智能商品化、验证者定律和智能的锯齿边界——为我们提供了一个极其有用的思维框架。
它告诉我们,智能和知识正以前所未有的速度变得廉价和普及;AI的进步方向将由我们衡量和验证世界的能力所引导;AI的发展不会是一场席卷一切的革命,而是一场在不同领域以不同速度展开的、不均衡的变革。
有了这个框架,我们就能更好地分辨哪些是AI带来的真正机遇,哪些只是被夸大的炒作,从而在充满变化和不确定性的未来中,找到自己的位置。