BosonAI 联合创始人、亚马逊前首席科学家,人工智能框架 MXNet 的作者之一:李沐,今年8月份在母校上海交大做了一场演讲,主要分享了他对大语言模型(LLM)的技术现状、未来趋势的预测以及个人职业生涯的感悟。因为他的创业方向是为客户做定制的LLM,他应该是我们熟知的大牛中离LLM最近的人之一,包括数据准备/清晰、预训练、后训练、LLM部署、机房建设、提供 serving、GPU/带宽/电力瓶颈等等。所以,他的演讲会给出很多有关LLM的一线认知,这里我摘出了其中他提到的一些核心认知。
核心认知
语言模型可以分为三块:算力、数据和算法。所以语言模型也好,整个机器学习模型也好,本质上就是把数据通过算力和算法压进中间那个模型里面,使得模型有一定的能力,在面对一个新的数据时,它能够在原数据里面找到相似的东西,然后做一定的修改,输出你要的东西。
这一次(浪潮里)的语言模型和上一次深度学习(浪潮里)的模型有一个比较大的区别 —— 上一次是,我炼一个什么丹就治一个什么病,这次我希望这个东西炼出来会有灵魂在里面,它能解决你很多问题,这其实是技术一代代往前进。
硬件
带宽:让芯片靠得更近一些
- 因为就现在的模型训练而言,很难让一个机器搞定所有事情,所以要做分布式训练,通常瓶颈就在带宽上。
- 我们现在的带宽是一根光纤承载 400Gigabits,下一代就是 double,变成 800Gigabits。
- 英伟达的 GB200 这个卡就可以把 GPU 都放一起,那么它们之间的通讯会变得更好一些。你可以理解成:之前我们做多核,把单核封装到一个芯片里面,现在是说多核不够,我要做多卡,多卡以前是分布在一个房间里面,现在是多卡也要尽量放在一起,这是一个趋势。就是一块芯片那么大,早就做不上去了,这是台积电等面临的工艺难题,现在是尽量把这些东西弄得近一些。
- 还有一个通讯是 GPU 和 CPU 之间的 PCIe,它每几年也在翻倍,但是确实会慢一些。
内存:制约模型尺寸的一大瓶颈
- 现在的语言模型,核心是把整个世界的数据压进模型里面,那模型就被搞得很大,几百 GB 的样子。在运行的时候,它的中间变量也很大,所以它就需要很多的内存。现在我们可以做到一个芯片里面封装近 192 GB 的内存。下一代带宽会更高一点。
- 很有可能在未来几年之内,一个芯片就 200GB 内存,可能就走不动了。这个要看工艺有没有突破。
- 内存大小会是模型上限的一个制约,而不是算力。内存不够,模型就做不大。在这一块,虽然英伟达是领先者,但其实英伟达是不如 AMD 的,甚至不如 Google 的 TPU。
算力:长期来看会越来越便宜
- 机器学习好的一点是,你可以用 4 位浮点数,硬件会变小,它对带宽的利用率也会变低,因为每次计算它只有那么多浮点数在里面。所以我们最近几代优化都来自浮点数的精度的降低。这是它给硬件带来的好处。
- 当你把模型做得更大的时候,你会发现资源是问题,就是供电。
- 最大的一个芯片要耗一千瓦,一千块芯片就是一兆瓦,整个校园都未必能用上一兆瓦的电。
- 关于算力价格。从理论上来说,在公平的市场里面,每次算力翻倍,价格会保持不变。但因为英伟达垄断的原因,短期内算力翻倍,价格可能会有1.4倍的提升。长期来看算力会变得越来越便宜。
- 算力这块,你可以用别的芯片,但是这些芯片用来做推理还 OK,做训练的话还要等几年的样子,英伟达还是处在一个垄断的地位。
- 今天训练一个模型,一年之后它的价值会减半。很多时候,大家不要去想我现在能搞多大的模型,一年之后,这个模型会贬值。我想说,大模型不是特别有性价比的东西。你要想清楚,从长期来看,你的模型能带来什么价值,让你能够保值。
模型
- 我觉得语言模型已经达到了较高的水平,大约在 80 到 85 分之间。
- 音频模型在可接受的水平,处于能用阶段,大约在 70-80 分之间。
- 但在视频生成方面,尤其是生成具有特定功能的视频尚显不足,整体水平大约在 50 分左右。
语言模型:100B 到 500B 参数会是主流
- 每次预训练,无论是 OpenAI 还是别的模型,基本都是用 10T 到 50T token 做预训练。开源的话基本也在 10T token 以上。这个数据量我觉得差不多了,不会再往一个更大的尺寸去发展。原因是,人类历史上的数据比这个多是多,但是看多样性、质量的话,我觉得 10T 到 50T 这个规模就差不多了。
- 我觉得比较好的一线的模型就是 500B,超过 500B 不是训练不动,而是做 serving 很难。在谷歌历史上,他们就没有让 500B 以上的模型上过线。OpenAI 没有对外说,但我觉得 OpenAI 历史上没有上线过有效大小超过 500B 的模型。当然 MoE 不算,我是说换算成稠密模型的话
语音模型:延迟更低、信息更丰富
- GPT-4o 出来之后,大家对于语音模型产生了浓厚的兴趣。端到端的方案有两个优点: 1. 信息更丰富 ;2. 延迟更短,大概300毫秒。传统方案大约1秒(ASR->llm->TTS)
- 还有一点就是说,它能够通过语言模型对整个输出做很多控制。可以让你用文本定制化一个什么样的声音出来。
音乐模型:不是技术问题,而是商业问题
- 它的技术其实比语音麻烦一点,因为音乐比人说话更复杂一点。
- 实际上它还是一个版权的问题。现在大家开始慢慢解决版权的问题 —— 大公司去买版权,小公司想反正我光脚不怕穿鞋的,我就上。
图像模型:生成的图越来越有神韵
- 图片应该是整个 AIGC 领域做得最早的,也是效果最好的。
- 现在大家可以做到 100 万以上像素的图片的生成。
- 大家说得最多的是图片要有灵魂。之前你去看那些文生图的工具,它的风格还是很假,但现在你会看到跟真的很接近,当然它还缺那么一点点灵魂,不过这一块说不定很快就有了。
视频模型:尚属早期
- 实际上还算比较早期,通用的 video 生成还是非常贵,因为 video 数据特别难弄。
- 视频模型的训练成本很有可能低于数据处理的成本,所以你没有看到市面上有特别好的开源模型出来。
- 问题在于生成一张图片容易,但生成一连串连贯的图片,并保持一致性是很难的。
多模态模型:整合不同模态信息
- 这样做有两大好处:一是可以借助强大的文本模型进行泛化。另一个优点是可以通过文本来定制和控制其他模态的输出,比如用简单的文本指令控制图片、视频和声音的生成,而不再需要专业的编程技能或工具。
killer app
- 所谓的 killer APP 就是说一个技术的出现,可能会涌现出一个非常受欢迎的应用形态。
- 大家知道手机的 killer APP 是什么吗?短视频。
- 上一波的顶级 AI 公司基本上快死得差不多了,包括 Character.AI、Inflection 被卖了,Adept 也被卖了,还剩一个 Perplexity 搜索还在支撑着。但是下一代 killer APP 是什么大家不知道。可能等技术变成熟,大家的不习惯慢慢地过去了,这个东西会涌现出来。
应用:AI 离变革世界还有很多年
在应用层面,AI 本质上是去辅助人类完成任务,给人类提供无限的人力资源。我将应用分成三类:
- 文科白领:白领是用自然语言去跟人、跟世界打交道,包括写文章或者其他。我认为在这方面做的比较好的领域包括个人助理、Call centers、文本处理、游戏和舆论以及教育。一个文科白领可能一小时完成的事情,我们的模型还是能够完成百分之八九十的。
- 工科白领:AI 在编程等领域的应用仍有很大提升空间,短期内难以取代人类。
- 蓝领工作:除了自动驾驶和特定场景(比如工厂,场景变化不大,也能采集大量数据)外,AI 连简单任务都做不了,完成复杂任务更难。。AI 理解蓝领的世界,包括和这个世界互动可能需要至少 5 年时间。
但是放眼整个世界,蓝领是最主要的成员,因此技术对这个世界做出巨大的变革还需要很多年。未来 10 年、 20 年,大家还是有机会参与进来的。
创业与职业生涯的感悟
- 预训练与后训练:李沐认为预训练已经从技术问题转变为工程问题,而后训练才是技术创新的关键。
- 垂直模型与通用知识:即使是垂直领域的模型,也需要具备一定的通用能力。就是说没有真正的垂直模型,就算是一个很垂直领域的模型,它的通用能力也是不能差的。比如说你要在某一个学科里面拿第一,你别的科目也不能差到哪里去。
- 评估很难,但很重要:评估模型效果的难度在于实际应用场景的复杂性,好的评估方法能够显著提升模型的优化效率。有一个好的评估可以解决 50% 的问题。因为一旦评估解决了,那你就能够进行优化。
- 数据决定模型上限:数据决定了模型的上限,算法决定了模型的下限。就目前来说,我们离 AGI 还很远, AGI 能够做自主的学习,我们目前的模型就是填鸭式状态。目前看来 Claude 3.5 做的还不错,一个相对来说不那么大的模型,能在各种榜单上优于 GPT-4 ,并且在使用上确实还不错。他们花了很大的力气来做数据,在数据上用了很多年。所以,想让模型在某一个方面做得特别好,需要先把相关数据准备好。大家还是用了 70-80% 时间在数据上。
- 算力: 就是买 GPU,自建机房不会比租 GPU 便宜太多,原因是大头被英伟达吃掉了, 英伟达的利润是 90%。一块卡是 3, 000 美金的成本,他卖你 3 万块钱。但自建的好处是能节省 CPU 的算力,以及你的存储和网络带宽。这些方面,自建就很便宜,但云就会很贵,因为这块在过去十年没有太大技术变革。比如说我用 AWS,存一年的数据成本等价于我把存这个东西的硬件买回来,而且能够容量变 10 倍。当你数据量增长很大的时候,自建是有意义的。
- 如果你去看语言模型,它就是一个机器学习模型,换了一个架构,只是更大了,带来很多困难,但它本质上还是可以用传统的机器学习那一套去理解的。它还是吃数据,评估还是很重要,所以很多之前的经验还是能用过来的。
- 在预训练方面,我觉得现在已经变成一个因为大而导致很多工程问题的困难,这其实还是算法上探索不够,得清楚如何改进算法。
个人提升与未来展望
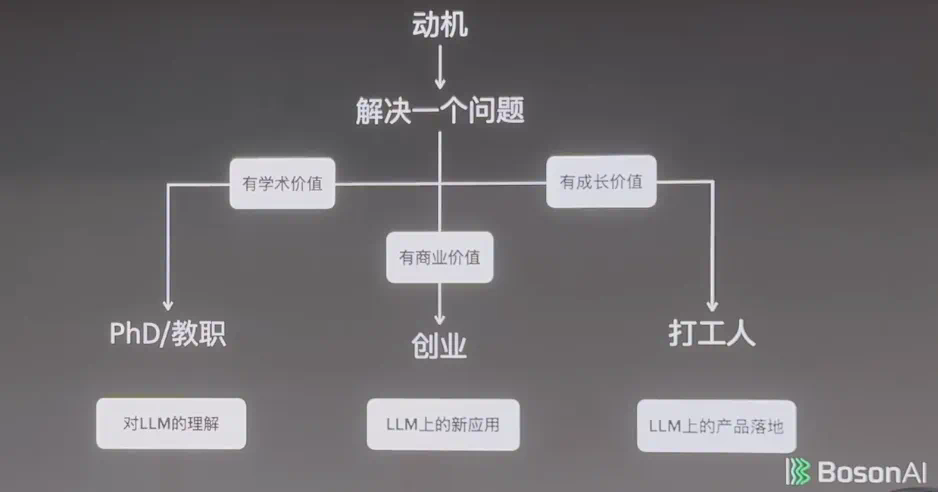
从最基本的目标来说,去大公司,是为了升职加薪;读 PhD ,你要保证自己能毕业;而创业的目标是要能推出产品,要么上市,要么卖掉,这是每天都需要思考的。
- 在大公司,你要解决问题。大家一定要想清楚:我要在公司干什么,公司今年准备干什么,最好两者保持一致。如果干的事情是自己喜欢的,但不是公司追求的,这就会让人很难受。
- 创业公司面临很多问题,用户会付钱吗?投资人会付钱吗?要是都没人付钱就糟糕了。
- 成立创业公司的动机就要更高一点,不然你熬不下来。
- 持续自我提升:李沐建议通过定期总结和反思来持续提升自我,选择比努力更重要,但前提是明确目标。
- 时代机遇与挑战:当前是技术快速发展的时代,虽然机会多,但需要付出更多努力才能抓住这些机会。
原文PPT