本文是 Andrew Ng 在 Deeplearning.AI 官方网站发布的一篇文章,主要探讨了近期 AI 领域的几个重要趋势和进展,涵盖了中国在生成式 AI 领域的快速发展、开源模型的影响、强化学习在提升语言模型推理能力方面的作用、AI 智能体在计算机应用中的兴起,以及美国 AI 政策的新动向和利用合成数据进行模型微调的优化方法。文章的核心论点包括:
中国 AI 追赶:
- DeepSeek 发布的 DeepSeek-R1 模型,在基准测试中性能与 OpenAI 的 o1 相当,并以 MIT 许可证开源发布。
- DeepSeek-R1 的发布引发市场对中国 AI 进步的关注,甚至导致 Nvidia 等美国科技公司股价短暂下跌 (“DeepSeek selloff”)。
- 中国的 Qwen、Kimi、InternVL 等模型也显示出中国在生成式 AI 领域的快速发展。
- 开源模型对于 AI 供应链至关重要,美国若限制开源,可能导致中国在这一领域占据主导地位。
开源模型商品化:
- DeepSeek R1 的 token 价格远低于 OpenAI 的 o1 (DeepSeek R1 为 $2.19 / 百万 tokens,o1 为 $60 / 百万 tokens),价格差异近 30 倍。
- 训练基础模型并提供 API 访问的商业模式面临挑战,而基于基础模型构建应用则有巨大的商业机会。
算法创新降低成本:
- DeepSeek 团队通过算法优化,在性能相对较弱的 H800 GPU 上训练出了高性能模型,计算成本低于 $600 万美元。
- 即使计算成本降低,对智能和算力的需求长期来看依然巨大。
强化学习提升推理:
- DeepSeek-R1、Kimi k1.5 和 o1 都利用强化学习改进模型的推理链 (Chain of Thought, CoT)。
- 强化学习奖励模型生成正确的推理步骤序列,而非仅仅是逐个 token 的反馈。
- 强化学习有助于模型学习解决问题的策略,例如双重检查答案,并优化生成回复的长度。
AI 智能体应用:
- OpenAI 的 Operator 智能体可以在 ChatGPT 内部模拟浏览器环境,自动执行在线购物、订票、填写表格等任务。
- Operator 基于名为 Computer-Using Agent (CUA) 的新模型,该模型使用强化学习在模拟和真实浏览器场景中进行训练。
- CUA 在 WebVoyager 和 OSWorld 等基准测试中表现出色,成功率分别达到 87% 和 38.1%。
- 其他 AI 智能体包括 ChatGPT Tasks、Anthropic 的 Computer Use、DeepMind 的 Project Mariner 和 Perplexity Assistant。
美国 AI 政策转向:
- 特朗普总统签署行政命令,旨在制定 AI 行动计划 (AI Action Plan),以提升国家安全、经济竞争力和美国在 AI 领域的领导地位,并设定了 180 天的期限。
- 行动计划要求 “维持和增强美国在全球 AI 领域的主导地位,以促进人类繁荣、经济竞争力和国家安全”。
- 行政命令指示各机构暂停或取消拜登政府 2023 年的行政命令中可能与提升美国 AI 主导地位和国家安全相冲突的政策。
- 美国政府宣布与 OpenAI、Oracle 和 SoftBank 合作启动 Stargate 项目,计划投资 $1000 亿美元用于 AI 计算基础设施,并在四年内投资 $5000 亿美元。
- 美国宣布国家能源紧急状态,旨在支持 Stargate 等能源密集型 AI 项目。
优化合成数据微调:
- Cohere 的研究人员提出了 active inheritance 方法,用于选择具有理想特征的合成数据进行模型微调。
- 该方法通过生成多个回复,并根据社会偏见、毒性、词数、词汇多样性和校准等指标评估回复质量,选择最佳回复进行微调。
- 使用 active inheritance 方法微调 Mixtral 8x7B 和 Llama 2 7B 模型,可以有效降低模型的毒性,并在某些情况下提升模型性能。
原文
亲爱的朋友们,
本周 DeepSeek 引起的广泛关注,让许多人清晰地认识到一些早已存在的趋势:(i) 中国在生成式 AI 领域正迅速赶上美国,这将对 AI 供应链产生深远影响。(ii) 开源权重模型正将基础模型层推向大众化,为应用开发者带来前所未有的机遇。(iii) AI 进步并非只有扩大规模一条路。尽管算力备受瞩目和追捧,但算法创新正在快速降低训练成本。
大约一周前,中国公司 DeepSeek 发布了DeepSeek-R1,这款卓越的模型在基准测试中的表现足以匹敌 OpenAI 的 o1。更令人称道的是,它以宽松的 MIT 许可证开源发布。上周在达沃斯,许多非技术出身的商业领袖纷纷向我询问有关这款模型的问题。而本周一,股市更是出现了“DeepSeek 抛售”:英伟达等美国科技公司的股价应声下跌(撰写本文时,股价已有所回升)。
我认为,DeepSeek 的出现让人们意识到以下几点:
中国在生成式 AI 领域正迎头赶上美国。 2022 年 11 月 ChatGPT 问世时,美国在生成式 AI 领域明显领先于中国。人们的固有印象总是难以快速改变,即使最近我还听到中美两地的朋友认为中国落后了。但事实上,这种差距在过去两年中已迅速缩小。有了 Qwen(我的团队已使用数月)、Kimi、InternVL 和 DeepSeek 等来自中国的模型,中国显然一直在奋起直追,甚至在视频生成等领域,中国已经展现出领先的势头。
我非常高兴看到 DeepSeek-R1 以开源权重模型的形式发布,并附带详细的技术报告。反观一些美国公司,却一味鼓吹人类灭绝等虚无缥缈的 AI 威胁,试图通过监管来扼杀开源。现在,开源/开放权重模型已然成为 AI 供应链不可或缺的一部分:众多公司都将依赖它们。如果美国继续压制开源,中国将主导这一供应链环节,许多企业最终将不得不使用更能反映中国价值观的模型,而非美国的价值观。
开源权重模型正在加速基础模型层的大众化。 正如我之前撰文指出的,大语言模型 (LLM) 的 token 价格正在飞速下降,而开源权重模型无疑加剧了这一趋势,并为开发者提供了更多选择。OpenAI 的 o1 模型每百万输出 token 的成本为 60 美元,而 DeepSeek R1 的成本仅为 2.19 美元。近 30 倍的巨大价格差异让更多人注意到了价格下降的趋势。

训练基础模型并销售 API 接口是一项极具挑战的业务。该领域的许多公司仍在苦苦寻求收回模型训练所耗费的巨额成本。《AI 的 6000 亿美元问题》一文对此进行了深入剖析(需要明确的是,我认为基础模型公司的工作非常出色,我衷心希望他们能够取得成功)。相比之下,在基础模型之上构建应用则蕴藏着巨大的商业机会。现在,既然其他公司已投入数十亿美元训练这些模型,你只需花费少许成本就能使用它们,构建出客户服务聊天机器人、邮件摘要工具、AI 医生、法律文档助手等等。
AI 进步并非只有扩大规模一条路。 人们一直热衷于通过扩大模型规模来推动 AI 进步。平心而论,我本人也曾是扩大模型规模的早期拥护者。许多公司通过宣传“只要投入更多资金,就能(i)扩大模型规模,并(ii)稳定提升模型性能”而筹集了数十亿美元。因此,人们将目光过多地放在了扩大规模上,而忽略了其他同样重要的进步途径。由于美国对 AI 芯片的出口管制,DeepSeek 团队不得不进行多项创新优化,以便在性能相对较弱的 H800 GPU 上运行,而非 H100 GPU。最终,他们仅用不到 600 万美元的计算成本(不包括研发成本)就完成了模型的训练。
但这是否真的会减少对算力的需求,目前还不得而知。有时,降低单位商品成本反而会刺激整体消费。我认为,长期来看,对智能和算力的需求几乎没有上限。所以我仍然坚信,即使智能变得越来越便宜,人类对智能的使用也会只增不减。
我在社交媒体上看到了人们对 DeepSeek 进展的各种解读,仿佛这是一场罗夏墨迹测试,每个人都在其中投射了自己的理解。我认为,DeepSeek-R1 的出现具有深远的地缘政治影响,其影响还有待进一步观察。同时,这对 AI 应用开发者来说也是一个重大利好。我的团队已经开始集思广益,探索新的可能性,而这些可能性都得益于我们现在可以轻松访问一个开放的高级推理模型。现在,仍然是进行 AI 开发的大好时机!
继续学习,
安德鲁
来自 DEEPLEARNING.AI 的消息

探索 Anthropic 的全新功能 - 计算机使用 - 它允许基于大语言模型的智能体直接与计算机界面交互。在这门免费课程中,你将学习如何利用图像推理和函数调用来“使用”计算机:模型会处理屏幕截图,分析内容以理解当前状态,并通过鼠标点击和键盘输入来操作计算机。立即开始!
新闻
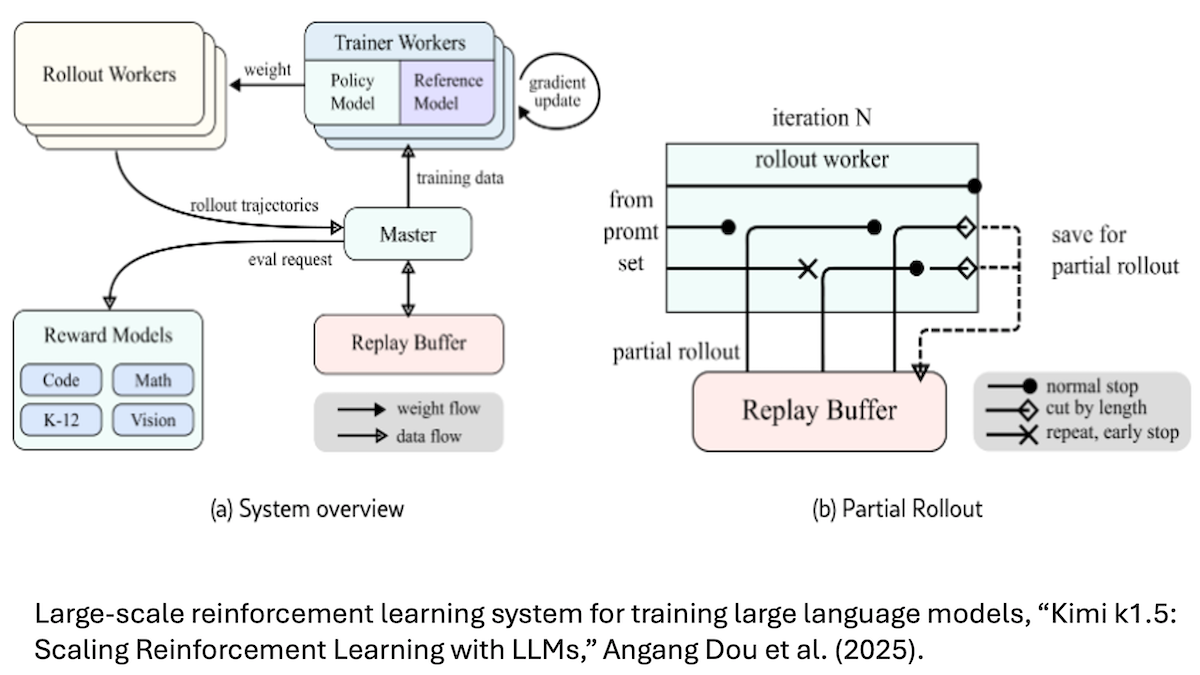
强化学习正逐渐成为构建具备高级推理能力的大语言模型的有效途径。
最新进展: 近期,两款高性能模型 DeepSeek-R1(及其变体 DeepSeek-R1-Zero)和 Kimi k1.5,都通过强化学习来提升模型自身的推理能力。o1 模型在去年就率先采用了这种方法。
强化学习 (RL) 的基本原理: 强化学习会根据模型执行特定操作或实现特定目标的情况,给予奖励或惩罚。与监督学习和无监督学习不同,强化学习不会直接告知模型应该输出什么,而是让模型在初始阶段随机行动,并通过对自身行为的奖励来逐步学习到期望的行为模式。因此,强化学习在训练游戏 AI 和机器人控制等领域的机器学习模型时非常受欢迎。
工作原理: 为了改进大语言模型 (LLM) 生成的 思维链 (CoT),强化学习会鼓励模型生成数学、编程、科学等已知答案的问题的正确解。与传统的大语言模型训练方式不同(模型只是逐个 token 生成输出,并接收 token 级别的反馈),这种方法会奖励模型生成一系列推理步骤,最终得出正确的结论。即使模型需要在提示和答案之间生成多个中间 token(例如制定计划、检查结论或反思方法),只要推理步骤能得出正确答案,模型都会受到奖励,而无需事先对推理步骤进行明确训练。
- DeepSeek 团队发现,在预训练之后,仅使用强化学习进行微调就足以让 DeepSeek-R1-Zero 学习到诸如双重检查答案等问题解决策略。然而,该模型也表现出了一些奇怪的行为,例如在输出中混合使用不同语言。为了解决这些问题,DeepSeek 团队在进行强化学习之前,先对少量长思维链的例子进行了监督微调,最终推出了 DeepSeek-R1 模型。
- 同样,Kimi k1.5 团队发现,在强化学习之前对模型进行长思维链的微调,能够让模型自行探索出问题解决策略。事实证明,这种方式生成的长回答更加准确,但同时计算成本也更高。因此,该团队又进行了第二轮强化学习,以鼓励模型生成更短的回答。在 AIME 2024 高级数学题基准测试中,这种方法使得平均回答的 token 数量减少了约 20%;而在 MATH-500 基准测试中,平均输出 token 数量则减少了约 10%。
- OpenAI 官方披露 的关于如何训练 o1 模型的信息有限,但团队成员透露,他们使用了强化学习来提升模型的思维链能力。
新闻背后: 尽管强化学习一直是训练游戏 AI 和 机器人控制 模型的主要技术,但它在开发大语言模型方面的作用一直仅限于对齐人类偏好。在 直接偏好优化 技术出现之前,通过强化学习来匹配人类的判断(从人类反馈中进行强化学习,即 RLHF)或 AI 的判断(宪法 AI,即从 AI 反馈中进行强化学习,即 RLAIF)是鼓励大语言模型与人类偏好保持一致的主要方法。
重要意义: 强化学习在训练大语言模型进行推理方面展现出惊人的实用性。随着研究人员推动模型在数学、编程、动画图像等更为复杂的任务中发挥作用,强化学习正逐渐成为一条重要的发展道路。
我们的思考: 不到三年前,强化学习还被认为过于难以驾驭 而不值得投入。如今,它已成为语言建模的关键方向。机器学习领域总是充满着令人意想不到的惊喜!

计算机使用功能渐入佳境
OpenAI 发布了一款 AI 智能体,可代表用户执行简单的网络任务。
最新进展: Operator 智能体可以在 ChatGPT 内部的浏览器式环境中操作网页,自动执行诸如购买商品、预订机票和填写表格等在线任务。目前,该功能已面向 ChatGPT Pro 订阅用户开放桌面研究预览版(每月 200 美元)。OpenAI 承诺将进一步扩大用户范围,并提供底层模型的 API 访问,同时还将增强其协调跨不同供应商的日历进行多步骤任务(如安排会议)的能力。
工作原理: Operator 采用名为 计算机使用智能体 (CUA) 的新型模型,该模型接受文本输入,并返回相应的网页操作指令。
- 用户在 ChatGPT 中输入指令。CUA 将这些输入转化为结构化的操作指令,并通过直接与网页元素(如按钮、菜单和文本框)交互来执行这些指令。OpenAI 没有透露 CUA 的具体架构和训练方法,但表示该模型是通过强化学习,在模拟和真实浏览器场景中训练而成。
- 在 OpenAI 执行的测试中,CUA 在部分指标上表现出色。在评估网络任务的 WebVoyager 测试中,CUA 的成功率达到了 87%。在 OSWorld 测试中,该基准测试用于评估多模态智能体在执行涉及真实世界网络和桌面应用程序的复杂任务时的能力,CUA 的成功率为 38.1%。在 Kura 和 Anthropic 公司进行的独立测试中,Kura 在 WebVoyager 测试中取得了 87% 的成功率,而 DeepMind 的 Mariner 智能体则取得了 83.5% 的成功率。在 OSWorld 测试中,具有计算机使用能力的 Claude Sonnet 3.5 模型取得了 22% 的成功率。
- Operator 智能体被限制与未经授权的网站互动,且在未获得用户同意的情况下不得共享敏感数据。它还配备了内容过滤器,并且有一个单独的模型实时监控 Operator 的行为,一旦发现可疑行为,就会立即暂停智能体的运行。
新闻背后: Operator 的出现正值自动化日常任务的智能体浪潮兴起之时。上周,OpenAI 推出了 ChatGPT Tasks 功能,用户可以通过该功能设置提醒和警报,但该功能尚不支持网页互动。(早期用户抱怨说,Tasks 功能存在缺陷,且需要用户提供过于精确的指令。) Anthropic 公司的计算机使用 功能专注于基本的桌面自动化,而 DeepMind 的 Project Mariner 则是一款基于 Gemini 2.0 构建的网络浏览助手。Perplexity Assistant 则可以自动化移动应用程序,例如在安卓手机上预订 Uber。
重要意义: 早期的用户反馈 表明,Operator 有时执行任务的效率不如人类。尽管如此,AI 智能体正在逐步进入消费市场,Operator 有望成为许多人的首次体验。它将为个人和企业提供各种各样的 AI 辅助,并且和 ChatGPT 对其他大语言模型开发者所起到的作用一样,它也将成为下一代产品的灵感来源。
我们的思考: 计算机使用功能正日趋成熟,其发展势头十分明显。AI 开发者应该将其纳入自己的工具箱。

白宫颁布强硬 AI 政策
在美国新总统的领导下,美国一改此前对 AI 监管的态度,转而通过减少限制来争取全球领导地位。
最新进展: 上周刚刚就任的特朗普总统签署 了一项行政命令,要求在 180 天内制定出 AI 行动计划。该命令旨在提升国家安全、经济竞争力以及美国在人工智能领域的领导地位。
工作原理: 该行政命令 指定由三位政府要员负责制定 AI 行动计划:总统科学技术助理(前 Scale AI 董事总经理)Michael Kratsios、新任 AI 和加密货币特别顾问(风险投资家)David Sacks 以及国家安全顾问 Michael Waltz。
- AI 行动计划必须“维持和加强美国在全球 AI 领域的主导地位,以促进人类发展、经济繁荣和国家安全。”
- 该命令还指示各机构负责人暂停或废除拜登总统在 2023 年颁布的行政命令 下制定的任何可能与提升美国 AI 领导地位和国家安全相冲突的政策。特朗普总统已撤销了拜登的行政命令。
- 美国公司开发的 AI 系统应“避免意识形态偏见或人为设定的社会议程”,这反映了本届政府认为 AI 系统中存在自由主义政治偏见的观点。
- 该命令还指示联邦管理和预算办公室将政府合同授予那些符合本届政府提升美国竞争力和国家安全优先事项的 AI 公司。
- 大多数条款都为负责制定行动计划的团队留下了很大的自由裁量权,使得他们对政策的解读和执行具有较大的不确定性。
AI 基础设施建设: 除了行政命令外,特朗普总统还宣布了一项名为 Stargate 的合资项目,该项目由 OpenAI、Oracle 和软银共同参与。这三家公司计划投资 1000 亿美元用于 AI 计算基础设施(例如下一代数据中心),并在未来四年内投资 5000 亿美元。此外,政府还宣布 美国能源供应进入国家紧急状态,并颁布命令,加速国内能源生产。这些举措旨在通过清除联邦土地上石油、天然气和可再生能源项目建设的监管障碍,从而为像 Stargate 这样能源密集型的 AI 项目提供支持。
重要意义: 特朗普政府认为,拜登政府 2023 年的法规“繁琐且不必要”,扼杀了创新,并危及了美国在 AI 领域的领导地位。新的行政命令减少了对 AI 开发的官僚监管,创造了更为宽松的监管环境(意识形态偏见除外)。
我们的思考: 拜登政府 2023 年的行政命令旨在防范假设而非实际存在的 AI 风险。该命令引入了用于训练模型的算力阈值作为衡量风险的指标,但这是一个欠考虑的替代方案。公平地说,美国国家标准与技术研究院下属的 AI 安全研究所并没有像一些人担心的那样阻碍 AI 的发展,但总的来说,该命令对 AI 创新或安全并无益处。我们很高兴看到新政府将重点放在 AI 进步而非假设性风险上。
微调的精妙之处
使用合成数据微调模型的做法正日渐普及。然而,即使合成训练数据能够很好地代表训练任务,也可能包含毒性等负面特征,从而导致模型产生不希望的输出,或者无法稳定输出目标长度等期望的特征。研究人员开发了一种方法,可以减少生成数据中不需要的特征,同时保留所需的特征。
最新进展: Cohere 公司的 Luísa Shimabucoro 及其同事提出了一种名为主动继承 的微调方法,该方法可以自动选择具有期望特征的合成训练样本。
核心思想: 生成合成微调数据的一种简单方法是向模型输入提示,收集模型的输出,并将其用作微调数据集。但是,合成数据的生成成本较低,因此我们可以更加挑剔。通过为每个提示生成多个响应,我们可以选择最符合我们要求的响应。
工作原理: 研究人员使用了 Llama 2 7B 和Mixtral 8x7B 模型,并以不同的方式将它们组合作为教师和学生。他们使用了来自Alpaca 数据集的 52,000 个提示来引导模型,然后利用自动化方法,从社会偏见、毒性、字数、词汇多样性和校准度 (模型预测概率与其准确性之间的匹配程度)等方面评估模型的输出。
- 对于每个提示,研究人员生成了 10 个响应。
- 对于每个响应,他们使用 StereoSet、CrowS-Pairs 和 Bias Benchmark for Question-Answering 基准来衡量社会偏见,使用 Perspective API 和他们自己的代码来衡量毒性,使用 HELM 来衡量校准度,并使用 TextDescriptives 计算文本相关指标。
- 他们分别在以下三种情况下对模型进行了微调:(i)初始响应;(ii)每个提示随机选择一个响应;(iii)每个提示选择最大化期望特征的最佳响应。
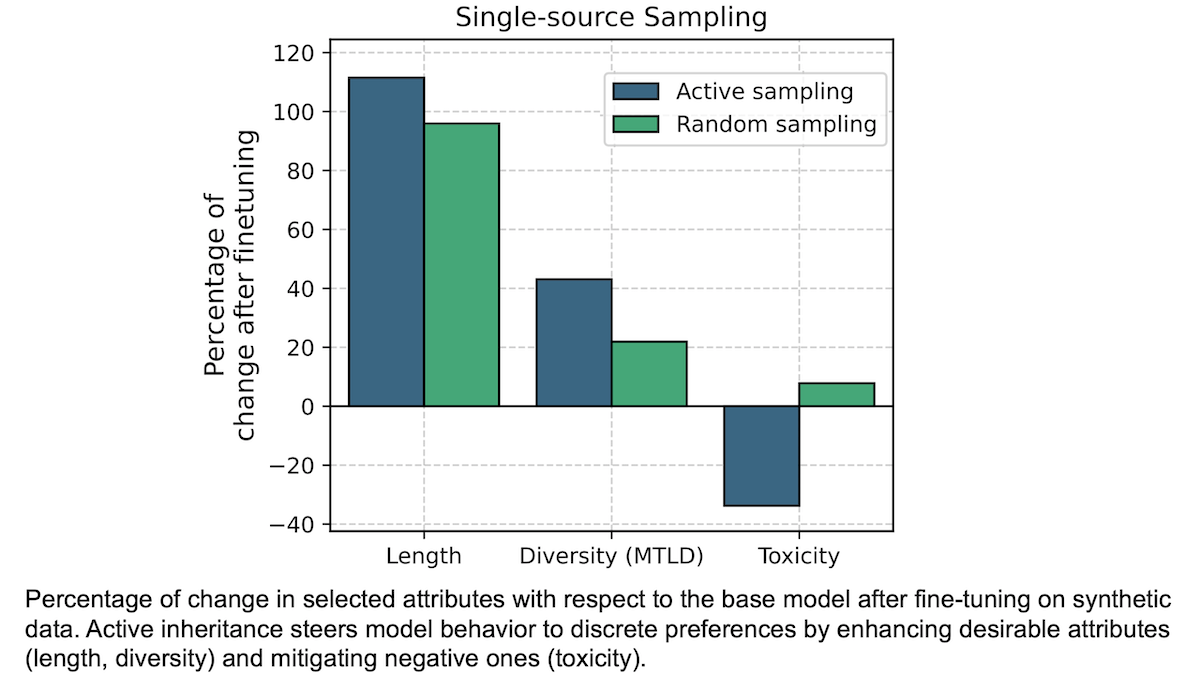
实验结果: 在每个特征的最佳响应上进行微调,模型在该特征上的性能均优于使用初始输出或随机选择输出的情况。
- 研究人员的方法有助于 Mixtral 8x7B 模型生成毒性更低的响应。例如,在微调之前,该模型的预期最大毒性 测量值为 65.2(数值越低越好)。在使用 Llama 2 7B 模型生成的毒性最低的响应进行微调之后,Mixtral 8x7B 模型的预期最大毒性降至 43.2。相反,在使用 Llama 2 7B 模型生成的随机响应进行微调之后,该模型的预期最大毒性则升至 70.3。
- 该方法还有助于 Llama 2 7B 模型降低毒性。在微调之前,该模型的预期最大毒性为 71.7。在使用自身生成的毒性最低的响应进行微调之后,预期最大毒性降至 50.7。而在随机响应上进行微调后,该模型的预期最大毒性降至 68.1,降幅较小。
- 研究人员还考察了该方法对更常见的性能指标的影响。结果表明,在毒性最小的响应上进行微调与在随机响应上进行微调,在七个基准测试中,模型表现出的效果大致相同。在使用 Llama 2 7B 模型自身生成的毒性最小的响应进行微调之后,该模型在七个基准测试上的平均准确率从 59.97% 提高到 60.22%。而在随机响应上进行微调,其平均准确率则从 59.97% 提高到 61.05%。
- 然而,在某些情况下,该过程反而会降低模型的性能。在使用 Llama 2 7B 模型生成的毒性最小的响应对 Mixtral-8x7B 模型进行微调之后,该模型在七个问题回答和常识推理基准测试中的平均准确率从 70.24% 降至 67.48%。而在 Llama 2 7B 模型生成的随机响应上进行微调后,其平均准确率则从 70.24% 降至 65.64%。
重要意义: 使用合成数据进行训练正变得越来越普遍。尽管前景广阔,但数据生成的最佳实践仍在探索之中。研究人员的这种方法可以通过自动引导模型生成更理想的响应,减少负面特征并加强正面特征,从而帮助改善模型训练的效果。
我们的思考: 近期,知识蒸馏技术使得模型的性能更高,模型体积更小。而这种方法则为知识蒸馏技术增加了精细控制的杠杆。