Minimax 昨天发布全球最强 TTS:Speech-02-HD 模型 技术报告,注意,本技术报告说的 MiniMax-Speech 均指 Speech-02-HD 模型。这里我说它全球最强,不是我随便说的,也不是他们自己的评测指标来的,而是来自于国际权威的Artificial Analysis TTS 榜单,通过全球用户测评。你也可以直接在官网进行体验。
快速看下模型的亮点
- 一个可学习的说话人编码器,该编码器无需转录即可从参考音频中提取音色特征,从而实现高表现力的零样本语音克隆。在 零样本 (zero-shot) 方式下生成与参考音频音色高度一致且富有表现力的语音,同时在 单样本 (one-shot) 语音克隆方面也能达到极高的相似度。
- 采用潜在流匹配模型作为 decoder,该模型基于创新的 Flow-VAE 模块。传统的 VAE 假设潜在空间为标准正态分布,而 Flow-VAE 引入流模型,通过一系列可逆映射更灵活地学习表达能力更强的后验分布,更准确地捕获复杂数据模式。
- 支持 32 种语言和卓越的多语言/跨语言能力
- 在多个客观和主观评估指标上取得了 最优 (SOTA) 结果。在 Seed-TTS test set 的客观语音克隆评估中,词错误率 (WER) 和 说话人相似度 (SIM) 均达到 SOTA。在公共 TTS Arena 排行榜上名列前茅
- 得益于说话人编码器提供的鲁棒且解耦的表示,该模型无需修改基础模型即可扩展到多种应用,例如:通过 LoRA 实现任意语音情感控制;通过从文本描述直接合成音色特征实现 文本转语音 (T2V);以及通过额外数据微调音色特征实现 专业语音克隆 (PVC)。
一些细节
架构

主要包含三个部分:
- 分词器(tokenizer)
- 自回归 Transformer(AR Transformer)
- 潜在流匹配模型(包含流匹配模块和 Flow-VAE 模块)
文本分词器采用字节对编码 (BPE),而音频分词器则采用 Encoder-VQ-Decoder 架构 (Van Den Oord 等人,2017; Betker,2023) 对梅尔谱图进行 25 个 token/秒的量化,并使用连接时序分类 (CTC) 监督。该语音分词器实现了高压缩率,同时有效地保留了丰富的声学细节和语义信息。
使用自回归 Transformer 架构 (Vaswani 等人,2017) 从文本输入生成离散音频 tokens。该系统擅长高保真度说话人克隆,尤其是在零样本语音克隆方面,它仅需一个未经转录的音频片段即可合成模拟目标说话人独特音色和风格的语音。
- 可学习说话人编码器: 这是 MiniMax-Speech 的关键特性,与使用预训练固定说话人编码器的模型不同,MiniMax-Speech 的说话人编码器与自回归 Transformer 联合训练。它仅从参考音频波形中提取说话人特征(如音色、韵律风格),无需文本转录,支持 零样本 (zero-shot) 克隆,避免了文本-语音不匹配问题,并促进了跨语言和多语言合成。它为韵律和风格生成提供了更灵活的解码空间,提高了语音的自然度和多样性。
- 零样本 vs 单样本 克隆: MiniMax-Speech 的核心优势是 零样本 (zero-shot) 语音克隆,仅使用参考音频定义声音特征。单样本 (one-shot) 克隆则通过提供额外的文本-音频配对示例来增强克隆保真度。零样本 (zero-shot) 在 词错误率 (WER) (清晰度) 和自然度上表现更优,而 单样本 (one-shot) 在 说话人相似度 (SIM) 上表现略优。

Flow-VAE 模块 也是 MiniMax-Speech 中的一项创新,结合了 VAE 和流模型。它用于优化潜在特征提取模块,通过可逆变换学习更具表现力的后验分布,从而增强 VAE 编码器的信息表达能力。与基于 mel-spectrogram 的传统方法不同,Flow-VAE 直接建模连续语音特征,减少了信息瓶颈,进一步提高了音频质量和说话人相似度。

评估结果
- 客观评估 (WER, SIM): 在 Seed-TTS-eval 数据集上, MiniMax-Speech 的 零样本 (zero-shot) 和 单样本 (one-shot) 克隆在 词错误率 (WER) 上均优于 Seed-TTS 和 CosyVoice 2。在 说话人相似度 (SIM) 上, 零样本 (zero-shot) 与 Ground Truth 相当, 单样本 (one-shot) 则与 Seed-TTS 持平并优于 CosyVoice 2。
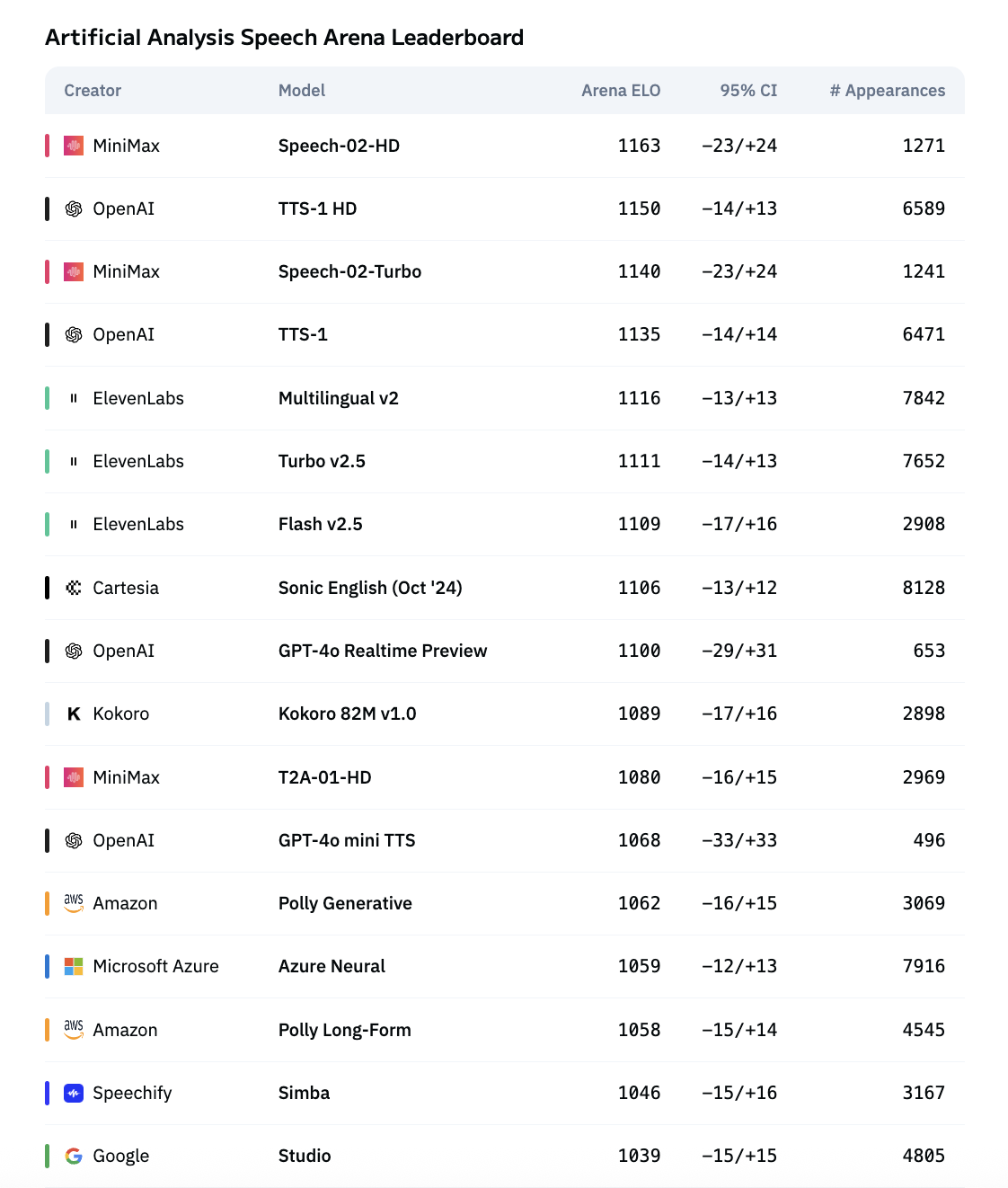
- 主观评估 (TTS Arena): 在公共 TTS Arena 排行榜上, MiniMax-Speech (Speech-02-HD) 排名第一,用户偏好度高于 OpenAI、 ElevenLabs、 Google、 Microsoft 和 Amazon 等模型,尤其在自然度和表现力方面。这证明了其 零样本 (zero-shot) 克隆能力达到了极高的质量水平。
- 多语言评估: 在包含 24 种语言的多语言测试集上, MiniMax-Speech 在 词错误率 (WER) 上与 ElevenLabs Multilingual v2 相当,但在 说话人相似度 (SIM) 上显著优于后者。
- 跨语言评估: MiniMax-Speech 的说话人编码器支持跨语言合成。在跨语言测试中, 零样本 (zero-shot) 方法在 词错误率 (WER) 上显著低于 单样本 (one-shot) 方法,显示出更好的跨语言发音准确性。
- 消融研究: 可学习说话人编码器在 词错误率 (WER) 和 说话人相似度 (SIM) 之间提供了最佳平衡,优于使用预训练 SpkEmbed 或仅依赖 Prompt 的方法。 Flow-VAE 在语音重建和 TTS 合成指标上均优于 VAE。
应用示例
- 情绪控制: 利用 LoRA 技术实现对合成语音的精确情绪控制,通过针对不同情绪训练独立的 LoRA 模块,并在推理时动态加载。中性或随机情绪的参考音频更有利于解耦说话人身份与情感。
- 文本到声音 (T2V): 基于自然语言描述和结构化标签信息生成任意和多样的音色,结合 AR Transformer 和 Flow Matching 模型提取的音色表示,通过一个紧凑的音色生成模型实现。
- 专业语音克隆 (PVC): 一种参数高效的微调方法,通过将特定说话人的条件 embedding 视为可学习参数进行优化,以提高针对特定说话人的合成质量和保真度。这种方法比 SFT 或 LoRA 更高效,适合对大量说话人进行适配。