Nvidia 因其架构、工程和供应链的领先,在生成式 AI 市场占据了优势地位。公司不仅资金充足,而且其 GPU 和互连技术路线图已规划至 2027 年,显示了其在推动AI革命中的雄心壮志。Nvidia 的 CEO 黄仁勋在 Computex 大会上强调了生成式 AI 的重要性,并展望了 AI 的未来以及 Nvidia 硬件的发展。
🔑 关键细节
➡️ 性能提升与能源消耗
从“Pascal” P100 GPU 到即将推出的 “Blackwell” B100 GPU,Nvidia 的GPU 性能在 8 年间提升了 1053 倍。
性能提升部分得益于将浮点精度从 FP16 降低到 FP4,这一变化使得性能增加了约 4 倍。
能耗降低是关键,因为生成大型语言模型响应所需的能量成本必须降低,以便与性能提升保持同步。
➡️ 成本与投资
GPU 的价格在过去 8 年中上涨了约 7.5 倍,但性能提升超过 1000 倍。
使用 Blackwell系 统,公司可以在约 10天 内用大约 10000 个 GPU 训练 GPT-4 1.8T MoE 模型。
一个包含 10000 个 GPU 的 Blackwell 系统成本约为 8 亿美元,而 10 天的电力成本约为 54,000 美元。
➡️ 技术路线图
- 2024 年推出的 Blackwell GPU 将配备 8 堆栈的 HBM3e 内存和 NVSwitch 5,后者具有 1.8 TB/s 的端口。
- 2025 年,Blackwell Ultra(B200)将拥有 8 堆栈更高容量的 HBM3e 内存。
- 2026 年,Rubin R100 GPU 将使用 HBM4 内存,而 2027 年的 Rubin Ultra 可能会配备更高效的内存堆栈。
➡️ 未来展望
- 2026年,Nvidia 将推出 “Vera” CPU,作为当前 “Grace” CPU 的后续产品。
- 2027年,可能会出现支持 Ultra Ethernet Consortium 的 NIC 和交换机,以及用于节点内和机架间连接 GPU 的 UALink 交换机。
NVIDIA 公布 GPU 和互连技术路线图,展望到 2027 年
在当前计算、网络和图形的发展史上,Nvidia 有许多独特之处。其中一个原因是它现在手头有大量资金,并且在生成式 AI (Generative AI) 市场上占据了领先地位,这得益于其架构、工程和供应链。因此,Nvidia 几乎可以随心所欲地制定任何路线图,只要它认为能带来进步。
Nvidia 在 2000 年代已经非常成功,本不需要扩展到数据中心计算领域。但 HPC 研究人员将 Nvidia 引入加速计算领域,随后 AI 研究人员利用 GPU 计算创造了一个全新的市场。这个市场已经等待了四十年,期望大量计算能力以合理的价格与海量数据碰撞,真正实现越来越像思维机器的愿景。
向 Danny Hillis、Marvin Minksy 和 Sheryl Handler 致敬,他们在 1980 年代创立了 Thinking Machines 推动 AI 处理,而不是传统的 HPC 仿真和建模应用。同时向 Yann LeCun 致敬,他当时在 AT&T Bell Labs 创建了卷积神经网络。他们当时既没有足够的数据,也没有足够的计算能力来实现我们现在所知道的 AI。当时 Jensen Huang 是 LSI Logic 的总监,该公司生产存储芯片,后来成为 AMD 的 CPU 设计师。当 Thinking Machines 在 1990 年代初期陷入困境并最终破产时,Huang 在圣何塞东部的 Denny’s 与 Chris Malachowsky 和 Curtis Priem 会面,并共同创立了 Nvidia。正是 Nvidia 看到了从研究和超大规模计算社区中出现的 AI 机会,并开始构建系统软件和底层大规模并行硬件,满足 AI 革命的梦想。
这 始终 是计算的终极状态,这 始终 是我们一直在走向的奇点 – 或者说是双极性。如果其他星球上有生命,那么生命 始终 会进化到拥有大规模毁灭性武器的阶段,并 始终 会创造人工智能。而且很可能是在同一时间。这取决于那个世界在那一刻之后如何使用这些技术,决定了它是否能在大规模灭绝事件中幸存下来。
这听起来可能不像是讨论芯片制造商路线图的正常介绍。的确如此,因为我们生活在有趣的时代。
在台湾台北举行的年度 Computex 贸易展上,Nvidia 的联合创始人兼首席执行官在其主题演讲中再次试图将生成式 AI 革命 – 他称之为第二次工业革命 – 置于其背景下,并让我们窥见 AI 的未来,尤其是 Nvidia 硬件的未来。我们看到了 GPU 和互连路线图的概览 – 据我们所知,这并不是计划的一部分,直到最后一刻,正如 Huang 及其主题演讲中常常发生的那样。
革命是不可避免的
生成式 AI 关乎规模,Huang 提醒我们这一点,并指出 2022 年底的 ChatGPT 时刻之所以能够发生,是由于技术和经济原因。
要达到 ChatGPT 的突破时刻,需要 GPU 性能的巨大增长,以及大量的 GPU。Nvidia 确实在性能方面取得了巨大进展,这对 AI 训练和推理都很重要,更重要的是,它大大减少了生成大语言模型 (LLM) 响应的每个 Token 的能耗。请看以下图表:

在“Pascal” P100 GPU 代与将于今年晚些时候开始出货并将在 2025 年逐步推广的“Blackwell” B100 GPU 代之间的八年间,GPU 的性能提升了 1053 倍(我们知道图表显示为 1000 倍,但这不够精确)。
其中一些性能提升是通过降低浮点精度实现的 – 从 Pascal P100、Volta V100 和 Ampere A100 GPU 中使用的 FP16 格式转向 Blackwell B100 中使用的 FP4 格式,提升了 4 倍。没有这种精度的降低 – 这可以在不显著影响 LLM 性能的情况下实现 – 性能提升仅为 263 倍。请注意,这在 CPU 市场中也是相当不错的,八年间核心性能每时钟周期提高 10% 到 15%,核心数量增加 25% 到 30%。这意味着如果升级周期为两年,CPU 吞吐量在相同八年间增加了 4 到 5 倍。
如上图所示,每单位工作的能耗减少是一个关键指标,因为如果你无法为系统供电,你就无法使用它。Token 的能耗必须降低,这意味着生成 LLM 的每个 Token 的能耗必须比性能提升得更快。
在他的主题演讲中,为了给您提供一些更深的背景,生成一个 Token 在 Pascal P100 GPU 上需要约 17,000 焦耳的能量,这大致相当于两天运行两个灯泡,而生成一个单词平均需要大约三个 Token。所以,如果你要生成大量单词,那是大量的灯泡!现在你开始明白为什么在八年前不可能以足够的规模运行 LLM,以使其在任务上表现良好。看看训练 GPT-4 混合专家 (Mixture of Experts) 大语言模型所需的功率,这个模型有 1.8 万亿参数,驱动模型的数据有 8 万亿个 Token:

对于 P100 集群来说,超过 1000 千兆瓦时是巨大的耗电量。真是令人惊叹。
Huang 解释说,使用 Blackwell GPU,公司将能够在大约十天内使用大约 10,000 个 GPU 训练这个 GPT-4 1.8T MoE 模型。
如果 AI 研究人员和 Nvidia 没有转向降低精度,那么在这八年间,性能提升将只有 250 倍。
降低能耗是一方面;降低系统成本是另一方面。在传统摩尔定律的末期,缩小晶体管尺寸每 18 到 24 个月进行一次,芯片变得更便宜和更小,这两个任务都非常困难。现在,计算复杂度已经达到掩模限度,每个晶体管变得更昂贵 – 因此,使用这些晶体管制造的设备也是如此。HBM 内存占成本的很大一部分,高级封装也是如此。
在 GPU 插槽的 SXM 系列中(不包括 PCI-Express 版本的 GPU),P100 的发布价格约为 5000 美元;V100 的发布价格约为 10,000 美元;A100 的发布价格约为 15,000 美元;H100 的发布价格约为 25,000 到 30,000 美元。据 Huang 自己今年早些时候在 CNBC 上谈到的 Blackwell 价格,预计 B100 的价格在 35,000 到 40,000 美元之间。
Huang 没有展示每一代 GPU 需要多少个来训练 GPT-4 1.8T MoE 模型,也没有展示这些 GPU 或电力的运行成本。因此我们做了一些表格计算,根据 Huang 说的使用大约 10,000 个 B100 来在大约十天内训练 GPT-4 1.8T MoE。请看:
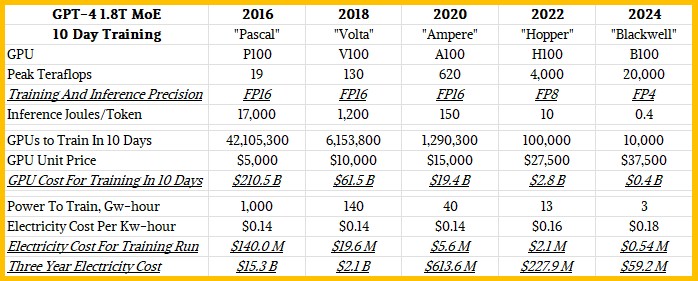
在这八年间,GPU 价格上涨了 7.5 倍,但性能却提升了超过 1000 倍。因此,现在使用 Blackwell 系统实际训练像 GPT-4 这样具有 1.8 万亿参数的大模型在十天左右是可行的,而在两年前 Hopper 代开始时,训练具有数千亿参数的模型需要几个月的时间。现在,系统成本将与该系统两年的电力成本相当。(GPU 占 AI 训练系统成本的约一半,因此购买 10,000 个 GPU 的 Blackwell 系统大约需要 8 亿美元,进行十天的训练大约需要 54 万美元的电费。如果你购买较少的 GPU,可以减少每天、每周或每月的电费,但也会相应地增加训练时间,从而再次提高电费。
你不能赢,也不能退出。
你猜怎么着?Nvidia 也不能。所以这就是现状。尽管 Huang 在 Computex 主题演讲中称 Hopper H100 GPU 平台是“历史上最成功的数据中心处理器”,但 Nvidia 仍需不断推进。
旁注:我们很想将这次 Hopper/Blackwell 投资周期与六十年前 IBM System/360 的发布进行比较,那时 IBM 创下了企业历史上最大的一次赌注,正如我们去年解释的那样。在 1961 年,当 IBM 开始其“下一代产品线”研究和开发项目时,它是一个年收入 22 亿美元的公司,并在 1960 年代花费了超过 50 亿美元。Big Blue 是华尔街的第一个蓝筹公司,正是因为它花费了两年的收入和二十年的利润来创建 System/360。是的,其中一些部分迟到且表现不佳,但它彻底改变了企业数据处理的性质。IBM 认为它可能在 1960 年代末(以 2019 年美元计)带来 600 亿美元的销售额,但它实际上带来了 1390 亿美元,利润约为 520 亿美元。
可以说,Nvidia 为数据中心计算的第二阶段创造了一个更大的浪潮。因此,现在或许一个真正的赢家将被称为绿色芯片公司?
抵抗是徒劳的
Nvidia 及其竞争对手或客户都无法抵抗未来的引力以及生成式 AI 在我们耳边不只是耳语而是从屋顶上喊出来的利润和生产力的承诺。
因此,Nvidia 将加快步伐,推动创新。拥有 250 亿美元的银行存款和预计今年超过 1000 亿美元的收入,或许还有 500 亿美元的银行存款,它可以负担得起推动创新并将我们所有人带入未来。
“在这个增长的时期,我们要确保继续提高性能,继续降低成本 – 训练成本、推理成本 – 并继续扩展 AI 能力,使每家公司都能接受。我们推高性能的越多,成本下降的越大。”
如上表所示,这一点显然是正确的。
这将我们带到了更新后的 Nvidia 平台路线图:
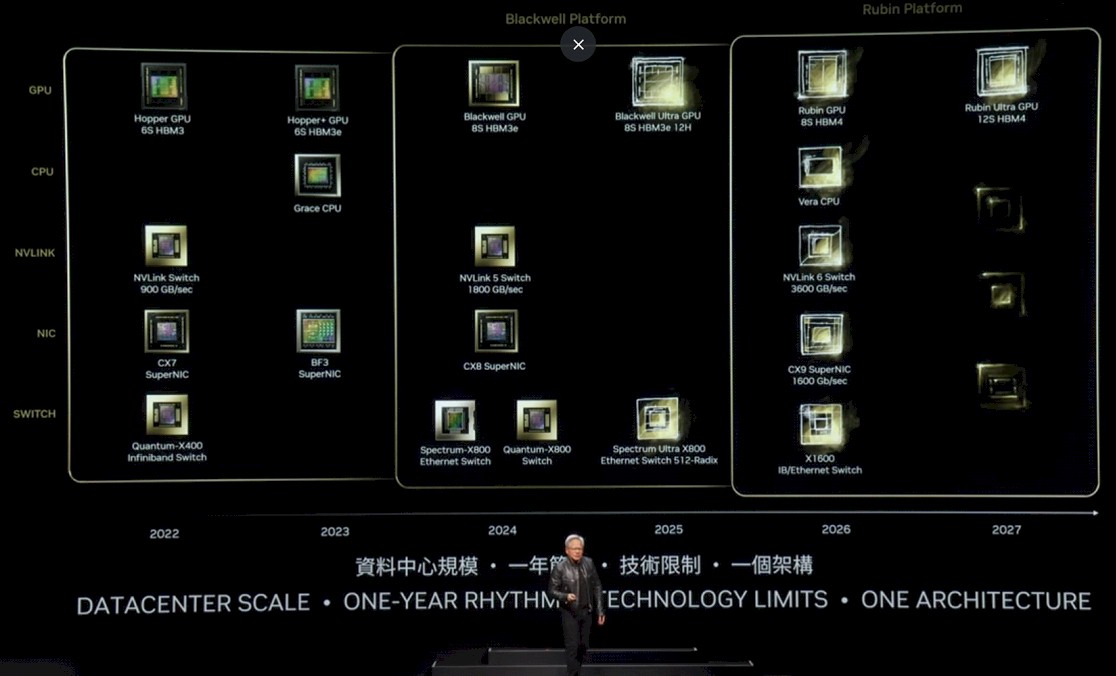
这有点难以阅读,所以让我们逐一解释。
在 Hopper 代,最初的 H100 于 2022 年推出,配备六堆 HBM3 内存,并配有带 900 GB/秒端口的 NVSwitch 以将它们连接在一起,并配有带 400 Gb/秒端口的 Quantum X400(以前称为 Quantum-2)InfiniBand 交换机和 ConnectX-7 网络接口卡。2023 年,H200 升级为六堆容量和带宽更高的 HBM3E 内存,从而提升了 H200 包中的基础 H100 GPU 的有效性能。还推出了 BlueField 3 NIC,将 Arm 核心添加到 NIC,以便它们可以执行辅助工作。
在 2024 年,Blackwell GPU 当然推出了八堆 HBM3e 内存,并配有带 1.8 TB/秒端口的 NVSwitch 5 和 800 Gb/秒 ConnectX-8 NIC 以及带 800 GB/秒端口的 Spectrum-X800 和 Quantum-X800 交换机。
我们现在可以看到,在 2025 年,B200,即上图中的 Blackwell Ultra,将配备八堆十二层高的 HBM3e 内存。据推测,B100 中的堆高为八层,因此这应代表 HBM 内存至少 50% 的容量增加,具体取决于所使用的 DRAM 容量。HBM3E 内存的时钟速度也可能更高。Nvidia 对 Blackwell 系列的内存容量有点含糊,但我们在 3 月 Blackwell 发布时推测 B100 将拥有 192 GB 内存和 8 TB/秒的带宽。对于未来的 Blackwell Ultra,我们预计会有更快的内存,并且不会感到惊讶地看到 288 GB 内存和 9.6 TB/秒的带宽。
我们认为 Ultra 变体在 SM 上的产量可能会有所提高,从而使其性能略高于非 Ultra 前代产品。这将取决于产量。
Nvidia 还将在 2025 年推出一个更高通量的 Spectrum-X800 以太网交换机,或许在一个盒子中使用六个 ASIC 创建一个无阻塞架构 正如其他交换机常用的方式 将总带宽翻倍,从而翻倍每个端口的带宽或交换机中的端口数量。
在 2026 年,我们看到“Rubin” R100 GPU,去年 Nvidia 发布的路线图中称为 X100,正如我们当时所说的,我们认为 X 是一个变量,而不是代表任何东西。事实证明是正确的。Rubin GPU 将使用 HBM4 内存,并将有八堆它,预计每堆有十二层高,而 2027 年的 Rubin Ultra GPU 将有十二堆 HBM4 内存,可能还有更高的堆(尽管路线图没有说明)。
我们在 2026 年之前没有看到 Nvidia 推出的新的 Arm 服务器 CPU,那时当前“Grace” CPU 的后续产品“Vera” CPU 将推出。NVSwitch 6 芯片与这些配对,带有 3.6 TB/秒端口和 1.6 Tb/秒端口的 ConnectX-9。而且有趣的是,还有一个叫做 X1600 IB/以太网交换机的东西,这可能意味着 Nvidia 正在融合其 InfiniBand 和以太网 ASIC,就像十年前 Mellanox 所做的那样。或者,这可能意味着 Nvidia 只是为了好玩让我们所有人猜测。有迹象表明 2027 年会有其他东西,这可能意味着对 NIC 和交换机的完全 Ultra 以太网联盟支持,以及甚至可能是 UALink 交换机 用于在节点内部和机架之间连接 GPU。
我们开玩笑的。但更奇怪的事情也发生过。
原文:https://www.nextplatform.com/2024/06/02/nvidia-unfolds-gpu-interconnect-roadmaps-out-to-2027