swyx 在此:我们很荣幸地推出 2025 年的第一篇客座文章1!这篇文章在 gdb、<Ben 和 Dan 的社交媒体页面上引发了热烈的讨论。
自从 o1 在 10 月份发布,以及 o1 pro/o3 在 12 月份宣布以来,许多人都在努力理解它们,既有积极的评价,也有负面的反馈。在 我们强烈支持的立场下,我们曾关注 o1 Pro 评价最低谷的时期,并分析了 OpenAI 要推出每月 2000 美元的 AI 智能体产品可能需要做些什么 (据传将在未来几周内发布)。此后,o1 在所有 LMArena 排行榜上都稳居第一 (正如我们在播客中讨论的,它很快将拥有默认的 风格控制)。
我们一直关注 Ben Hylak 在 Apple VisionOS 上的工作,并邀请他在世界博览会上发表演讲。他随后推出了 Dawn Analytics,并持续分享他对 o1 的真实想法。他最初是持强烈怀疑态度,后来逐渐成为 o1 的日常用户。我们很欣赏那些能够改变自己看法的人,并且认为当人们尝试从聊天模式过渡到推理和像 Devin 这样每月几百美元的专业 AI 产品的新领域时,全球各地都在发生同样的讨论 (Devin 在世界博览会上有过演讲,并且已经 正式发布 (GA))。以下是我们的一些想法。
我是如何从讨厌 o1 到每天使用它来解决最重要问题的?
我学会了如何正确使用它。
当 o1 pro 发布时,我毫不犹豫地订阅了。为了使每月 200 美元的价格显得合理,它只需要每月节省 1-2 个工程师的工作时间 (我们在 dawn 雇佣的工程师越少越好!)
然而,在尝试了一整天,想要让模型正常工作后,我得出的结论是,这玩意儿就是垃圾。
每次我提出一个问题,都要等待 5 分钟,然后得到的却是一大堆自相矛盾的胡言乱语,外加一些我没要求的架构图和优缺点列表。
我忍不住在 推特上吐槽,许多人表示赞同。但更有意思的是,有些人却强烈反对,他们对 o1 的强大能力感到震惊。
当然,在 OpenAI 发布新产品后,人们通常会变得非常兴奋(这可是仅次于负面评价的第二大走红策略)。
但这次的感觉有所不同,这些观点都来自那些真正深入研究过 o1 的人。
我与那些不同意我看法的人交流得越多,就越意识到我完全误解了 o1:
我一直像使用聊天模型一样使用 o1,但 o1 并不是一个聊天模型。
如果 o1 不是聊天模型,那它到底是什么呢?
我把它看作是一个“报告生成器”。如果你提供足够的上下文,并明确告诉它你希望得到什么样的输出,它通常能够一次性给出正确的解决方案。
swyx 提示:OpenAI 确实发布了一些关于如何提示 o1 的建议,但我们认为这些建议并不完整。从某种意义上说,你可以把这篇文章看作是关于如何在实践中使用 o1 和 o1 pro 的“缺失的手册”。
你需要提供大量的上下文。无论你认为的“大量”是多少,都请在此基础上乘以 10 倍。

当你使用像 Claude 3.5 Sonnet 或 4o 这样的聊天模型时,你通常会从一个简单的问题和一些背景信息开始。如果模型需要更多信息,它通常会主动向你索取 (或者从输出结果中能明显看出来)。
你会与模型反复交流,修正错误并添加需求,直到得到期望的输出。这就像在制作陶器。聊天模型本质上是通过这种反复的交流从你那里获取上下文信息。随着时间的推移,我们提问的方式会变得更快、更随意——只要能得到好的结果,我们就会尽可能地“偷懒”。
然而,o1 会直接接受这种随意的问题,并不会主动尝试从你这里获取更多信息。相反,你需要尽可能多地将上下文信息“推送”给 o1。
即使你只是在问一个简单的工程问题,也应该:
详细说明所有你尝试过但没有成功的方法。
提供所有数据库模式的完整转储。
解释你的公司是做什么的,规模有多大(并解释公司内部的专业术语)。
简而言之,把 o1 当作新入职的员工对待。请注意,o1 的一个问题在于它在推理“应该推理多少”时也可能会犯错。有时候,它对任务难度的判断并不准确。例如,如果任务非常简单,它可能会毫无理由地陷入冗长的推理过程。值得注意的是,o1 的应用程序接口 (API) 允许你指定低、中、高三种推理强度,但 ChatGPT 用户无法使用此功能。
让 o1 更容易理解上下文的小技巧
我建议在你的 Mac 或手机上使用语音备忘录应用程序。我通常会用一两分钟的时间描述整个问题,然后把语音转录的文本粘贴进去。
我甚至有一个专门的笔记,用来存储可以重复使用的长段上下文信息。
swyx:我使用的是 LS Discord 社区的 Sarav 开发的Careless Whisper。
许多产品内置的 AI 助手也可以帮助你提取上下文。例如,如果你使用 Supabase,可以尝试让 Supabase 助手导出并描述所有相关的表、远程过程调用 (RPC) 等信息。
一旦你尽可能多地为模型提供了上下文,接下来就应该专注于明确你希望它输出什么内容。
我们使用大多数模型时,通常被训练成告诉模型我们希望它如何回答。例如,“你是一名资深的软件工程师,请缓慢而仔细地思考”。
但我在使用 o1 时发现,成功的方法恰恰相反。我不会指导它如何做,而只是告诉它做什么。然后,让 o1 自己接管,计划并执行解决问题的步骤。这正是自主推理能力的用途,而且实际上可能比你作为“人在回路中”手动审查和沟通要快得多。
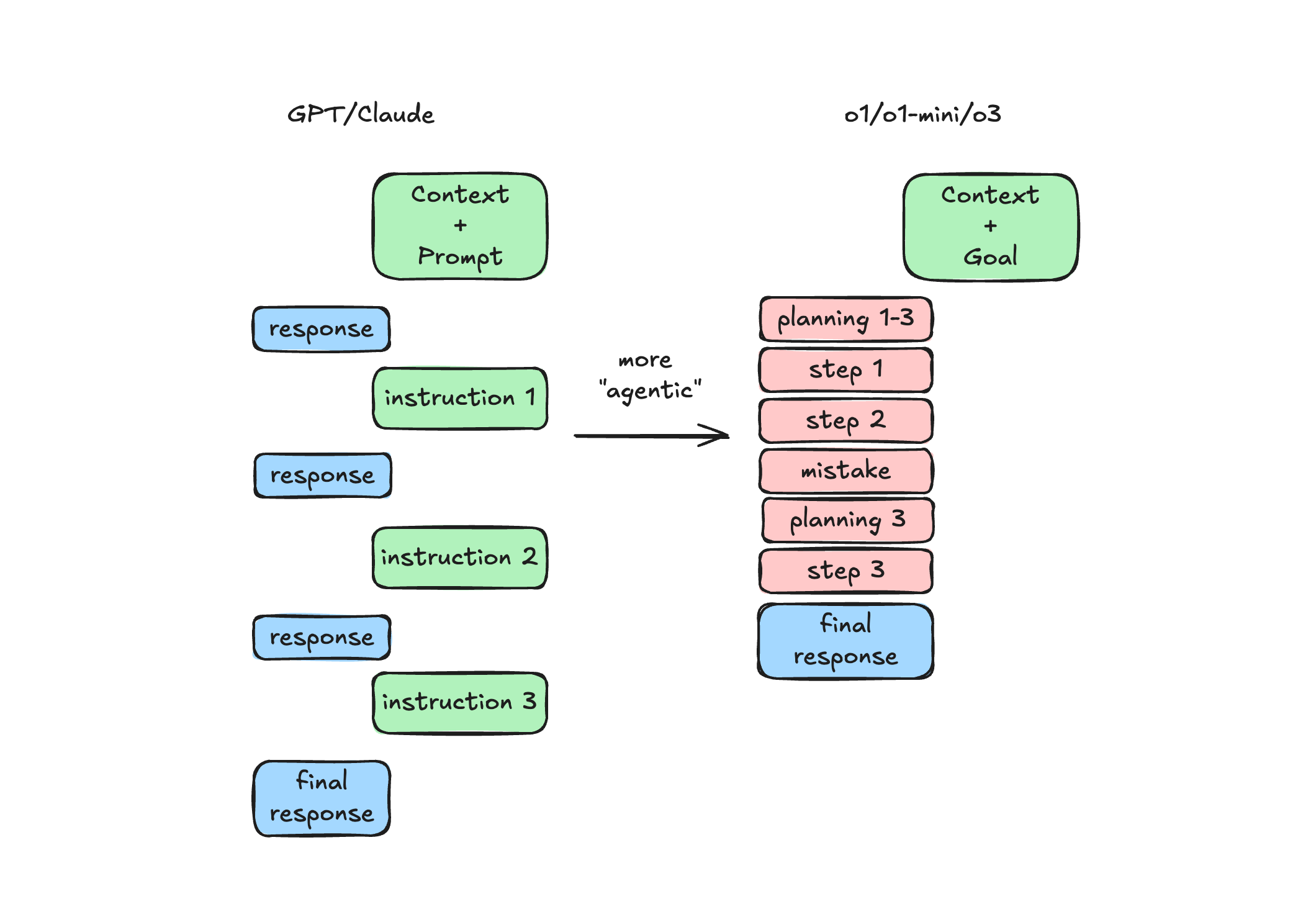
swyx 的专业建议:为 “好” 与 “坏” 制定清晰的标准,可以帮助你让模型能够评估自己的输出,并自我改进和修复错误。本质上,你是将大语言模型 (LLM) 作为评判者的能力融入到提示中,并让 o1 在需要时运行它。
此外,当你正式发布 (GA) 强化学习微调 (Reinforcement Finetuning) 功能时,这将为你提供可以使用的 “大语言模型 (LLM) 评判者”。
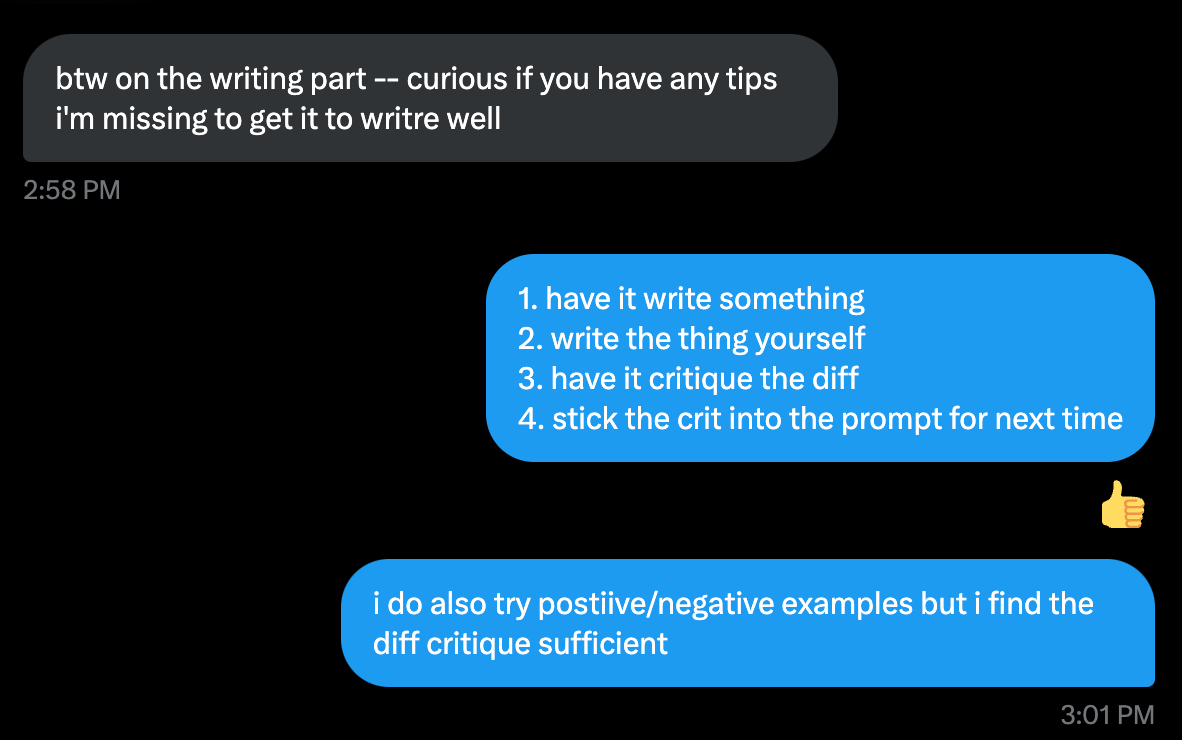
这要求你非常清楚自己想要什么 (而且你最好每次提示只要求一个明确的输出——它只在开始时进行推理!)。
这听起来容易,但做起来并不简单!我是希望 o1 在生产环境中实现特定的架构、创建一个最小的测试应用程序,还是只是探索各种方案并列出优缺点?这些都是完全不同的要求。
o1 通常默认使用报告式的语法来解释概念——包括带编号的标题和副标题。如果你想跳过解释,直接输出完整的文件,只需要明确地说明即可。
自从学会如何使用 o1 以来,我对其第一次就能生成正确答案的能力感到非常惊讶。它几乎在所有方面都表现得更好(除了成本和延迟之外)。以下是一些特别让我印象深刻的例子:
o1 的优点:
能够一次性生成完整或多个文件:这是 o1 最令人印象深刻的能力。我只需复制粘贴大量的代码,提供我正在构建的内容的背景信息,它就可以一次性生成整个文件(或多个文件!),通常没有任何错误,并且遵循我代码库中的现有模式。
更少地“胡编乱造”:总的来说,它似乎不太容易混淆。例如,o1 在处理定制查询语言 (如 ClickHouse 和 New Relic) 时非常出色,而 Claude 经常会混淆 Postgres 的语法。
医学诊断:我的女朋友是一名皮肤科医生,所以当任何朋友或家人遇到皮肤问题时,都会给她发照片!我出于好奇,开始并行地向 o1 提问。它给出的答案通常非常接近正确答案,大概有 3/5 的准确率。对于医疗专业人员来说,它几乎总是能给出非常准确的鉴别诊断,这更有价值。
解释概念:我发现 o1 非常擅长用例子来解释复杂的工程概念。它几乎可以生成一整篇文章。
当我在研究复杂的架构决策时,我经常会让 o1 生成多个方案,并列出每个方案的优缺点,甚至对这些方案进行比较。我会将回复复制粘贴为 PDF 文件,并进行比较,就像在考虑提案一样。
额外优点:模型评估。我一直对使用大语言模型 (LLM) 作为模型评估的评判者持怀疑态度,因为从根本上来说,评判模型通常会受到与生成输出的模型相同的失败模式的影响。然而,o1 在这方面展现出巨大的潜力。它通常能够在很少的上下文信息下判断生成结果是否正确。
o1 目前的不足之处:
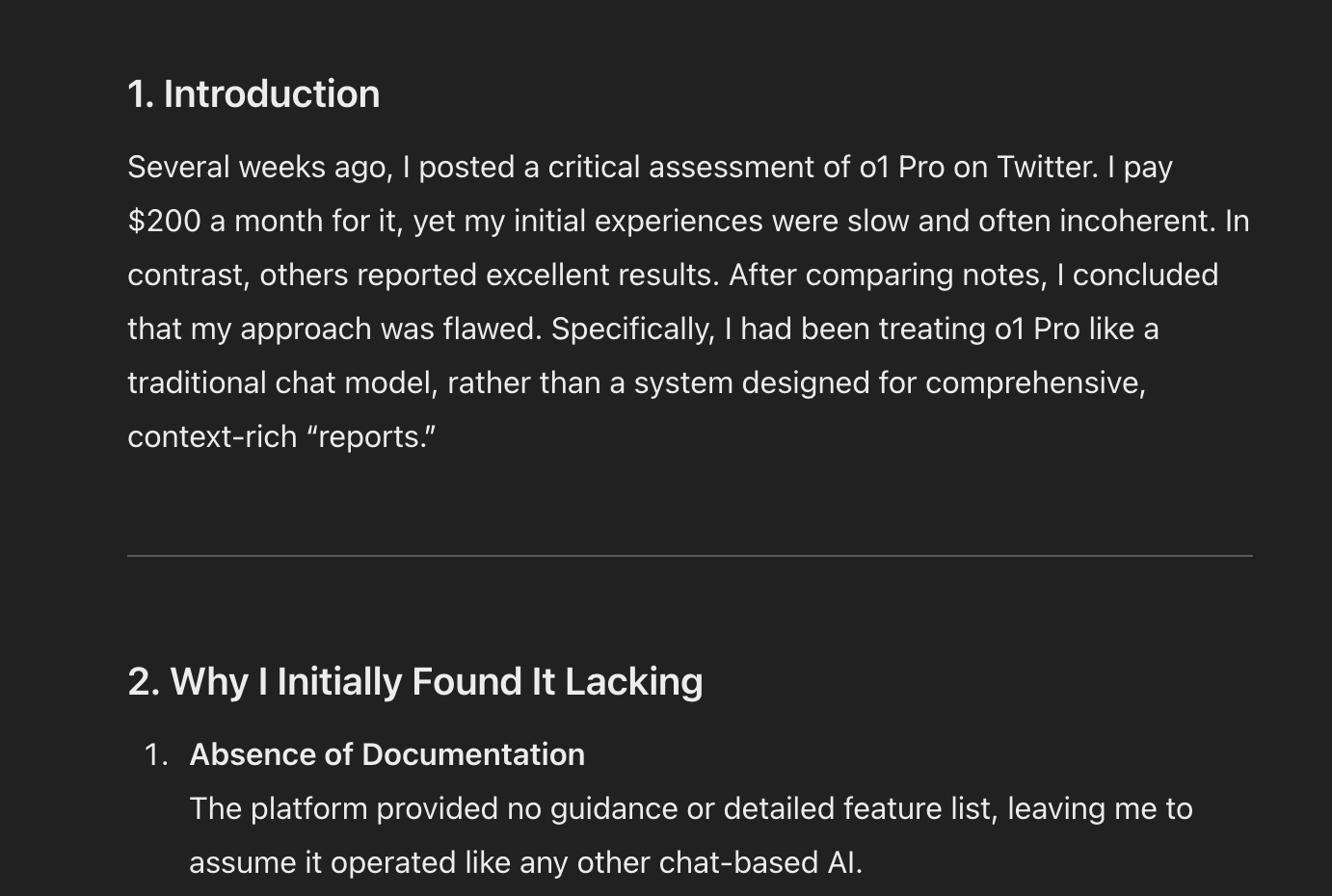
以特定的声音或风格写作:不,我没有使用 o1 来写这篇文章 :)
我发现 o1 非常不擅长写作,尤其是在特定的声音或风格方面。它倾向于使用非常学术化的报告风格。我认为可能是因为有太多的推理 Token 将语调向那个方向引导,导致很难摆脱这种风格。
这是一个我尝试让 o1 写这篇文章的例子,在经过多次来回沟通后,它仍然只想生成一份平淡无奇的学校报告。
构建完整的应用程序:o1 在一次性生成整个文件方面表现出色。尽管你可能在 Twitter 上看到一些过于乐观的演示,但 o1 并不能为你构建一个完整的软件即服务 (SaaS) 产品,至少在没有大量迭代的情况下是如此。但是,它可以一次性完成整个功能,特别是前端或简单的后端功能。
延迟从根本上改变了我们对产品的体验。
swyx:我们同意,正如现在常见的 人工智能 (AI) 推理的六个延迟级别。
想想邮件、电子邮件和短信之间的区别,它们的主要差异在于延迟。语音留言和电话之间的区别,也是延迟。视频和 Zoom 之间的区别,还是延迟。等等。
我把 o1 称为“报告生成器”,因为它显然不是聊天模型,更像是电子邮件。
这一点尚未在 o1 的产品设计中得到体现。我希望看到其设计能更真实地反映在用户界面 (UI) 上。
以下是针对任何基于 o1 构建产品的人提出的一些人工智能 (AI) 用户体验 (UX) 建议:
让用户更容易查看回复的层次结构(可以考虑使用迷你目录)。
同样,使层次结构更容易导航。由于每个请求的长度通常都超过窗口高度,我建议采用类似 Perplexity 的方法,将每个问题和答案放在单独的部分,而不是自由滚动。在答案中,可以使用粘性标题和可折叠标题等功能,这将非常有用。
让用户更容易管理和查看你提供给模型的上下文信息。(讽刺的是,Claude 的用户界面在这方面做得更好,当你粘贴长文本时,它会显示为一个小的附件)。我还发现 ChatGPT 项目的效果远不如 Claude,所以我经常需要复制和粘贴内容。
补充说明:
另外,在处理 o1 时,ChatGPT 真的有很多错误。它对推理的描述很可笑,经常完全无法生成内容,而且在移动应用程序上基本无法使用。
在...肯尼亚的美好一天?
我非常期待看到这些模型实际如何被应用。
我认为 o1 将首次使某些类型的产品成为可能,例如那些可以从高延迟、长时间运行的后台智能中获益的产品。
用户愿意等待 5 分钟来完成什么任务?一个小时?一天?3-5 个工作日?
我认为有很多,只要设计得当。
随着模型的成本越来越高,进行实验的成本也变得难以承受。现在,在几分钟内浪费数千美元比以往任何时候都更容易。
o1-preview 和 o1-mini 支持流式传输,但它们不支持结构化生成或系统级提示。o1 支持结构化生成和系统级提示,但尚不支持流式传输。
考虑到响应所需的时间,流式传输似乎是必不可少的功能。
我非常期待看到开发人员在 2025 年开始使用这个模型时会创造出什么。