最近计划抽时间写一个文档相关的翻译类项目,调研了几个主流的开源 PDF 转 Markdown 项目,从最终的效果来看,MinerU 的 Magic-PDF 当之无愧是当前最佳的选择,缺点就是速度慢。
项目:zerox
- 代码:https://github.com/getomni-ai/zerox
- 介绍:一种非常简单的PDF文档解析方法
- 逻辑:使用 PyMuPDF 将 pdf 文件中的每一页转换为图片,并将图片给 LLM ,让其转换为 markdown 格式
- 使用的prompt:
Convert the following PDF page to markdown. Return only the markdown with no explanation text. Do not exclude any content from the page.
- 优劣势
- 优点:在纯文字、表格等场景下,效果还不错
- 缺点 :在有配图的情况下,配图会被丢失掉,用
<img>之类的占位表示图片
项目:gptpdf
- 代码:https://github.com/CosmosShadow/gptpdf
- 介绍:使用视觉大语言模型(如 GPT-4o)将 PDF 解析为 markdown。方法非常简单(只有293行代码),但几乎可以完美地解析排版、数学公式、表格、图片、图表等。每页平均价格:0.013 美元
- 逻辑:
- 用PyMuPDF识别中其中的线条(page.get_drawings())、图片(page.get_image_info())、文本区域
- 用一些策略做一些合并,最终得到一个只有表格和图片的区域
- 将这些区域截图后存储在本地
- 在原图上用红色框和序号标注好,送给GPT识别,最终的结果是个markdown格式
- 使用的prompt
使用markdown语法,将图片中识别到的文字转换为markdown格式输出。你必须做到:
1. 输出和使用识别到的图片的相同的语言,例如,识别到英语的字段,输出的内容必须是英语。
2. 不要解释和输出无关的文字,直接输出图片中的内容。例如,严禁输出 “以下是我根据图片内容生成的markdown文本:”这样的例子,而是应该直接输出markdown。
3. 内容不要包含在```markdown ```中、段落公式使用 $$ $$ 的形式、行内公式使用 $ $ 的形式、忽略掉长直线、忽略掉页码。
4. 一定要保留原文的内容不变,如图中原文是 Figure 1,应该识别后输出的结果也应该为 Figure 1。
再次强调,不要解释和输出无关的文字,直接输出图片中的内容。
图片中用红色框和名称(%s)标注出了一些区域,使用 ![]() 的形式插入到输出内容中,作为该部分区域的文本结果,且要单独占一行。例如,红色框标注的文本为1_1.png,则输出的文本为:
- 优劣势:
- 优点:充分利用大模型的能力,整体看效果还不错
- 缺点:对模型能力要求较高,容易出现幻觉
- 一个例子(PDF的一页处理后送给LLM的图)

项目:omniparse
- 代码:https://github.com/adithya-s-k/omniparse
- Google Colab在线体验地址,运行后可以直接试用
- 介绍:OmniParse 是一个平台,可将任何非结构化数据摄取并解析为针对 GenAI 优化的结构化、可操作的数据(LLM )应用程序。无论您正在处理文档、表格、图像、视频、音频文件还是网页,OmniParse 都能让您的数据变得干净、结构化,并为 RAG、微调等 AI 应用程序做好准备
- 场景
- 优点:支持格式众多 ,如果适用于LLM的RAG场景OK
- 缺点:解析的精度不够,即准确性差了一些,比如pdf、图片、web等格式
- UI 界面
项目:MinerU
- 代码:https://github.com/opendatalab/MinerU
- 体验地址:https://opendatalab.com/OpenSourceTools/Extractor/PDF
- 介绍 :MinerU 是一款一站式、开源、高质量的数据提取工具,主要包含以下功能:Magic-PDF (PDF文档提取) 和 Magic-Doc (网页与电子书提取)。我们这里只关注与PDF转mardown。Magic-PDF 是一款将 PDF 转化为 markdown 格式的工具。支持转换本地文档或者位于支持S3协议对象存储上的文件。
- 支持多种前端模型输入
- 删除页眉、页脚、脚注、页码等元素
- 符合人类阅读顺序的排版格式
- 保留原文档的结构和格式,包括标题、段落、列表等
- 提取图像和表格并在markdown中展示
- 将公式转换成latex
- 乱码PDF自动识别并转换
- 支持cpu和gpu环境
- 支持windows/linux/mac平台
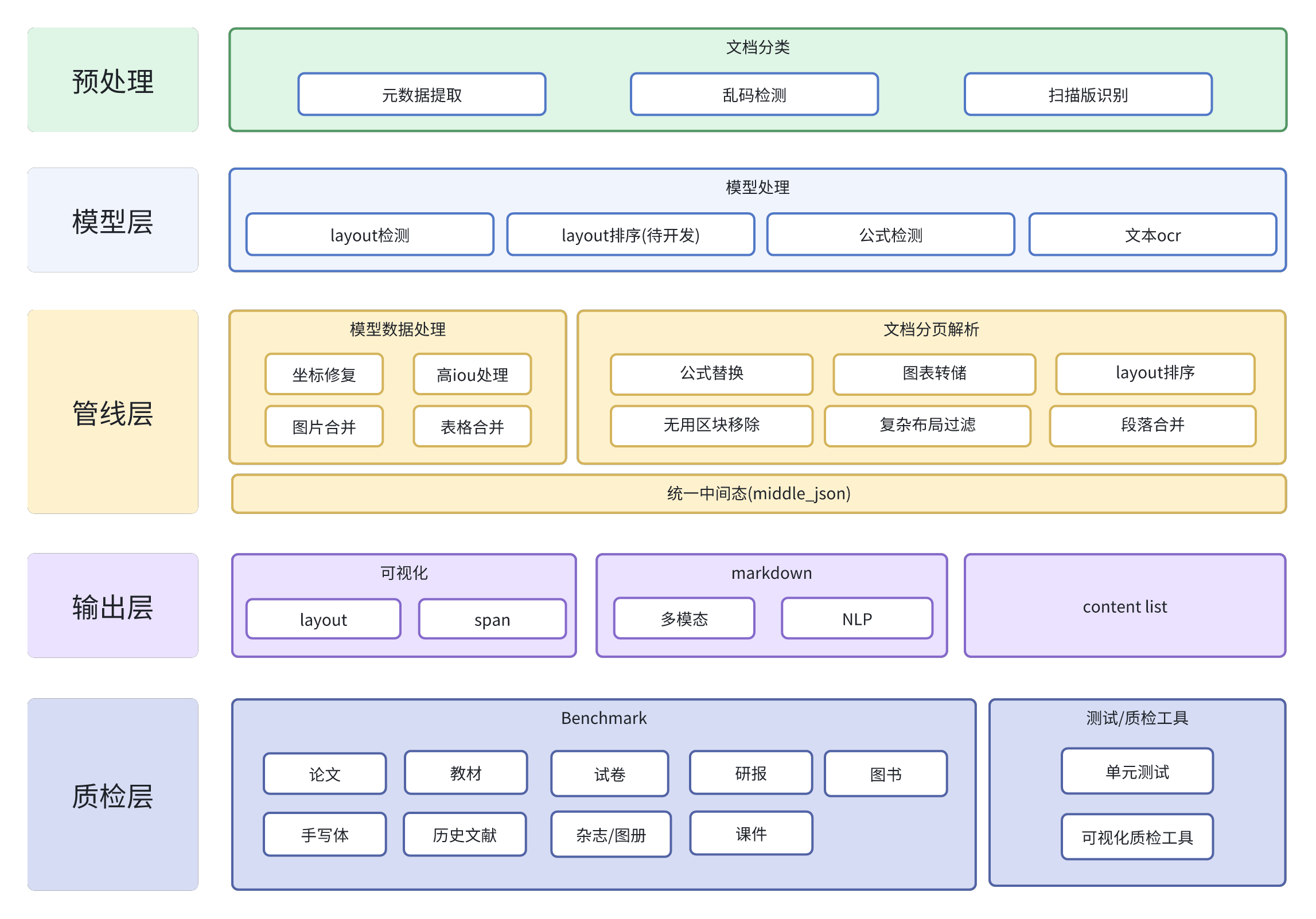
- 逻辑
- 底层使用PDF-Extract-Kit 解析PDF文档,输出json文件。其中PDF-Extract-Kit 包含的功能有
- 布局检测:使用LayoutLMv3模型进行区域检测,如图像,表格,标题,文本等;
- 公式检测:使用YOLOv8进行公式检测,包含行内公式和行间公式;
- 公式识别:使用UniMERNet进行公式识别;
- 表格识别:使用StructEqTable进行表格识别;
- 光学字符识别:使用PaddleOCR进行文本识别;
- 根据json文件输出markdown
- 底层使用PDF-Extract-Kit 解析PDF文档,输出json文件。其中PDF-Extract-Kit 包含的功能有
- 架构图
- 优劣势
- 优点:准确率上很高,包括布局、配图、文本、公式、表格等等,商用级别
- 缺点:速度比较慢