学习如何为您的应用程序定制模型。
介绍
微调可以通过以下方式让您更好地利用 API 提供的模型:
- 比直接使用提示获得更高质量的结果
- 可以训练比提示中更多的示例
- 由于提示更简短,节省 Token
- 请求延迟更低
OpenAI 的文本生成模型已经在大量文本数据上进行了预训练。为了有效使用这些模型,我们通常在提示中包含说明和几个示例。这种通过示例展示任务的方法称为“少样本学习”。
微调通过在提示中包含更多示例来改进少样本学习,从而在许多任务上获得更好的结果。一旦模型经过微调,您不需要在提示中提供那么多示例。 这样可以节省成本并降低请求延迟。
微调一般包括以下步骤:
- 准备并上传训练数据
- 训练一个新的微调模型
- 评估结果,如有需要返回第一步
- 使用您的微调模型
访问我们的定价页面,了解微调模型训练和使用的费用。
哪些模型可以微调?
GPT-4(gpt-4-0613 和 gpt-4o-*)的微调处于实验性访问计划中,符合条件的用户可以在创建新的微调任务时在微调界面中申请访问。
目前以下模型可以进行微调:gpt-3.5-turbo-0125(推荐),gpt-3.5-turbo-1106,gpt-3.5-turbo-0613,babbage-002,davinci-002,gpt-4-0613(实验性),以及 gpt-4o-2024-05-13。
如果您获得了更多数据且不想重复之前的训练步骤,还可以对一个已经微调的模型进行再次微调。
我们认为gpt-3.5-turbo在结果和易用性方面对于大多数用户来说是最佳选择。
何时使用微调
微调 OpenAI 的文本生成模型可以让它们更适合特定应用,但这需要大量的时间和精力投入。我们建议首先尝试通过提示工程、提示链(将复杂任务分解为多个提示)和函数调用来获得良好结果,主要原因包括:
- 我们的模型在许多任务上的初始表现可能不佳,但通过正确的提示可以改善结果,因此可能不需要微调
- 提示迭代和其他策略的反馈循环比微调更快,而微调需要创建数据集并运行训练任务
- 在需要微调的情况下,初始的提示工程工作不会浪费 - 通常我们会在微调数据中使用良好的提示(或结合提示链和工具使用与微调)时获得最佳效果
我们的提示工程指南提供了不进行微调而提高性能的一些最有效策略和技巧。您可以在我们的playground中快速迭代提示。
常见用例
以下是一些微调可以改善结果的常见用例:
- 设置风格、语气、格式或其他定性方面
- 提高生成所需输出的可靠性
- 纠正未能遵循复杂提示的错误
- 特定方式处理许多边缘情况
- 执行在提示中难以表达的新技能或任务
一个高层次的思路是,当“展示”比“说明”更容易时。在接下来的部分中,我们将探讨如何设置微调数据以及微调在基线模型上提升性能的各种示例。
另一个微调的有效场景是通过替换 GPT-4 或使用较短的提示来减少成本和/或延迟,而不牺牲质量。如果您能用 GPT-4 获得良好结果,通常可以通过在 GPT-4 结果上微调gpt-3.5-turbo模型并缩短指令提示,达到类似的质量。
准备您的数据集
一旦您确定微调是正确的解决方案(即您已经优化了提示并发现模型仍有问题),您就需要准备训练模型的数据。您应创建一组多样化的示范对话,这些对话与您在生产中要求模型响应的对话类似。
数据集中的每个示例都应该是与我们的聊天完成 API相同格式的对话,具体来说是一系列消息,每条消息都有一个角色、内容和可选名称。至少一些训练示例应直接针对模型在提示中表现不佳的情况,并且数据中提供的助手消息应是您希望模型给出的理想响应。
示例格式
在这个例子中,我们的目标是创建一个偶尔会给出讽刺回复的聊天机器人,以下是我们可以为数据集创建的三个训练示例(对话):
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?"}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters."}]}
微调 GPT-3.5-turbo 需要使用对话聊天格式。对于 babbage-002 和 davinci-002,您可以按照下面所示的提示-完成对的格式进行微调。
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
多轮对话示例
在聊天格式的示例中,可以有多条助手角色的消息。微调时的默认行为是训练每个示例中的所有助手消息。如果想跳过对某些助手消息的微调,可以添加weight键来禁用这些消息的微调,从而控制哪些助手消息会被模型学习。目前,weight的值可以是0或1。下面是一些使用weight的聊天格式示例。
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
设计提示词
我们通常建议将您在微调前发现对模型最有效的一组指令和提示词包含在每个训练示例中。这样可以帮助您获得最佳和最普遍的结果,特别是当您的训练示例相对较少(例如少于一百个)时。
如果您想缩短每个示例中重复的指令或提示词以节省成本,请记住模型可能会依然按照这些指令行动,并且在推理时可能很难让模型忽略这些“内置”的指令。
由于模型必须完全通过演示学习,而没有指导性的指令,可能需要更多的训练示例才能获得良好的结果。
示例数量建议
要微调模型,您至少需要提供10个示例。我们通常发现对gpt-3.5-turbo进行50到100个训练示例的微调可以带来明显的改进,但具体数量会因具体用例而异。
我们建议从50个精心设计的示例开始,看看模型在微调后是否有改进迹象。在某些情况下,这可能就足够了,但即使模型尚未达到生产质量,明显的改进也是提供更多数据将继续改进模型的好兆头。如果没有改进,可能需要重新考虑如何设置任务或在扩大示例集之前重构数据。
训练和测试数据分割
在收集初始数据集后,我们建议将其分为训练集和测试集。在提交包含训练和测试文件的微调任务时,我们将在训练过程中提供两者的统计数据。这些统计数据将是模型改进程度的初步信号。此外,尽早构建一个测试集将有助于确保您能够在训练后评估模型,通过在测试集上生成样本进行评估。
Token 限制
Token 限制取决于您选择的模型。对于gpt-3.5-turbo-0125,最大上下文长度为16,385,因此每个训练示例也限制为16,385个 Token。对于gpt-3.5-turbo-0613,每个训练示例限制为4,096个 Token。超过默认值的示例将被截断到最大上下文长度,这会从训练示例的末尾删除 Token。为了确保您的整个训练示例适合上下文,请考虑检查消息内容中的总 Token 数是否在限制范围内。
您可以使用 OpenAI Cookbook 中的Token 计数笔记本来计算 Token 数。
估算成本
有关训练成本以及部署微调模型的输入和输出成本的详细定价,请访问我们的定价页面。请注意,我们不对用于训练验证的 Token 收费。要估算特定微调训练任务的成本,请使用以下公式:
(每百万输入 Token 的基础训练成本 ÷ 1M) × 输入文件中的 Token 数量 × 训练的 Epoch 数
例如,对于一个包含100,000个 Token 的训练文件,训练3个 Epoch,预期成本约为2.40美元,使用gpt-3.5-turbo-0125。
检查数据格式
在编译数据集并创建微调任务之前,检查数据格式非常重要。为此,我们创建了一个简单的 Python 脚本,您可以用来发现潜在错误、检查 Token 计数并估算微调任务的成本。
微调数据格式验证
了解微调数据格式
上传训练文件
一旦验证了数据,您需要使用Files API上传文件,以便在微调任务中使用:
from openai import OpenAI
client = OpenAI()
client.files.create(
file=open("mydata.jsonl", "rb"),
purpose="fine-tune"
)
文件上传后,可能需要一些时间来处理。在文件处理期间,您仍然可以创建微调任务,但任务要等到文件处理完成后才会开始。
最大文件上传大小为1 GB,但我们不建议使用这么大的数据量进行微调,因为您可能不需要这么多数据就能看到改进效果。
创建微调模型
在确保数据集的数量和结构正确并上传文件后,下一步就是创建微调任务。我们支持通过微调 UI或编程方式来创建微调任务。
使用 OpenAI SDK 启动微调任务:
from openai import OpenAI
client = OpenAI()
client.fine_tuning.jobs.create(
training_file="file-abc123",
model="gpt-3.5-turbo"
)
在这个示例中,model是您要微调的模型名称(如gpt-3.5-turbo、babbage-002、davinci-002或已有的微调模型),training_file是上传到 OpenAI API 后返回的文件 ID。您可以使用suffix 参数来自定义微调模型的名称。
如需设置其他微调参数,例如validation_file或超参数,请参阅微调 API 规范。
启动微调任务后,可能需要一些时间才能完成。您的任务可能会排在系统中的其他任务之后,训练一个模型可能需要几分钟到几小时,具体取决于模型和数据集的大小。模型训练完成后,创建微调任务的用户将收到确认电子邮件。
除了创建微调任务,您还可以列出现有任务、查询任务状态或取消任务。
from openai import OpenAI
client = OpenAI()
# List 10 fine-tuning jobs
client.fine_tuning.jobs.list(limit=10)
# Retrieve the state of a fine-tune
client.fine_tuning.jobs.retrieve("ftjob-abc123")
# Cancel a job
client.fine_tuning.jobs.cancel("ftjob-abc123")
# List up to 10 events from a fine-tuning job
client.fine_tuning.jobs.list_events(fine_tuning_job_id="ftjob-abc123", limit=10)
# Delete a fine-tuned model (must be an owner of the org the model was created in)
client.models.delete("ft:gpt-3.5-turbo:acemeco:suffix:abc123")
使用微调模型
当任务成功完成后,在检索任务详情时,您会看到fine_tuned_model字段中显示了模型名称。现在,您可以将这个模型作为参数,使用Chat Completions(用于gpt-3.5-turbo)或旧版 Completions API(用于babbage-002和davinci-002),并通过Playground向其发送请求。
任务完成后,模型应立即可用于推理。在某些情况下,模型可能需要几分钟才能准备好处理请求。如果请求超时或找不到模型名称,可能是模型仍在加载中。这种情况发生时,请稍等几分钟再试。
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="ft:gpt-3.5-turbo:my-org:custom_suffix:id",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message)
您可以按照上面的方法,通过传递模型名称开始发送请求,并参考我们的GPT 指南。
使用检查点模型
除了在每个微调任务结束时创建最终的微调模型外,OpenAI 还会在每个训练周期结束时创建一个完整的模型检查点。这些检查点本身就是可以在我们的 completions 和 chat-completions 端点中使用的完整模型。检查点的价值在于它们可能提供了模型在过拟合之前的版本。
要访问这些检查点:
对于每个检查点,您会看到fine_tuned_model_checkpoint字段中显示了模型检查点的名称。您现在可以像使用最终微调模型一样使用这个检查点模型。
{
"object": "fine_tuning.job.checkpoint",
"id": "ftckpt_zc4Q7MP6XxulcVzj4MZdwsAB",
"created_at": 1519129973,
"fine_tuned_model_checkpoint": "ft:gpt-3.5-turbo-0125:my-org:custom-suffix:96olL566:ckpt-step-2000",
"metrics": {
"full_valid_loss": 0.134,
"full_valid_mean_token_accuracy": 0.874
},
"fine_tuning_job_id": "ftjob-abc123",
"step_number": 2000
}
step_number:检查点创建时的步骤数(每个 epoch 是训练集中步骤数与批量大小的商)metrics:一个包含检查点创建时微调任务各项指标的对象。
目前,仅保存并提供任务最后 3 个 epoch 的检查点。我们计划在不久的将来推出更复杂和灵活的检查点策略。
分析您的微调模型
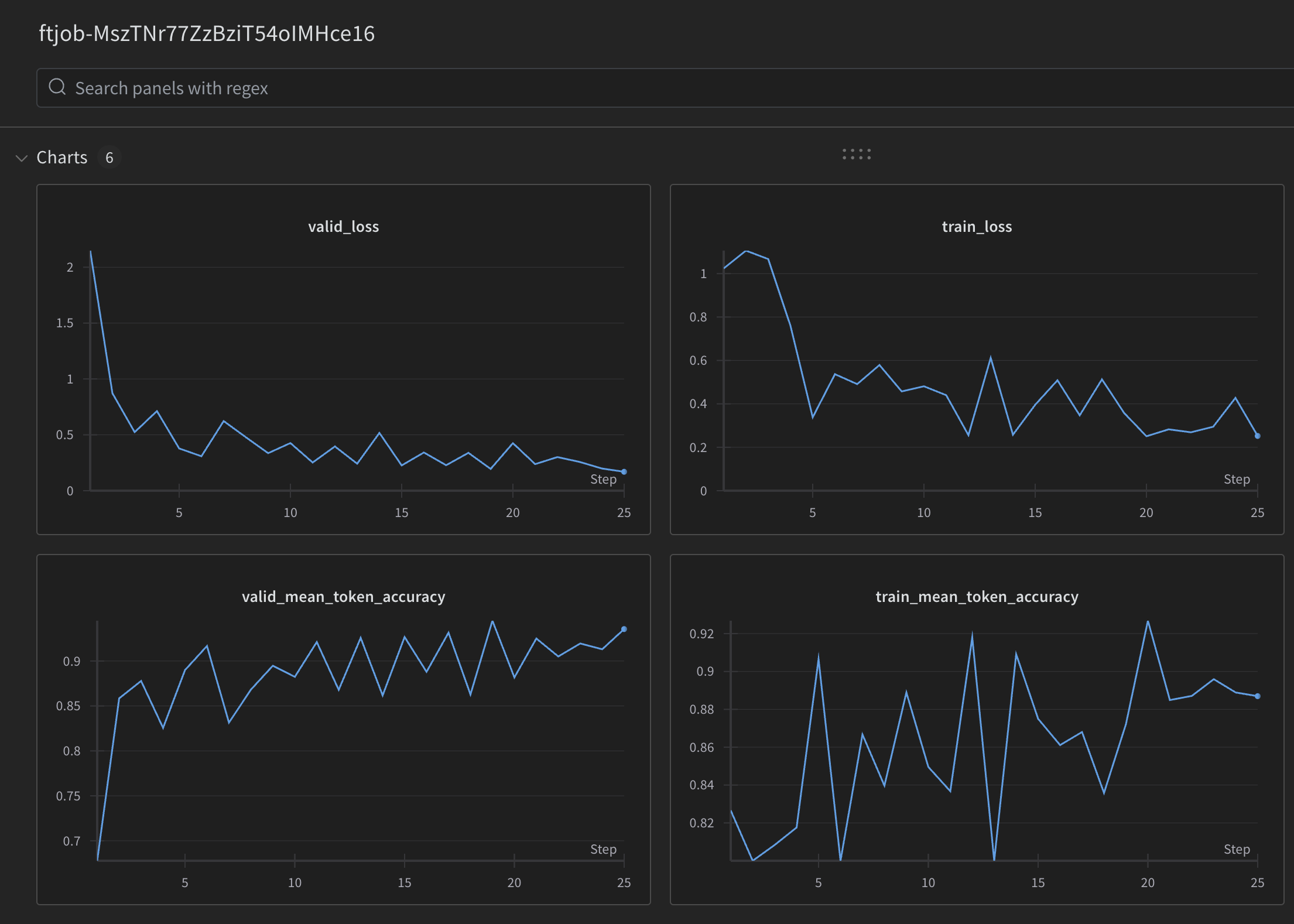
我们在训练过程中提供以下训练指标:
- 训练损失
- 训练 Token 准确率
- 验证损失
- 验证 Token 准确率
验证损失和验证 Token 准确率有两种计算方式:在每一步的小批数据上计算,以及在每个 epoch 结束时的完整验证集上计算。完整验证损失和完整验证 Token 准确率是最准确的模型整体性能跟踪指标。这些统计数据旨在提供一个合理性检查,以确保训练顺利进行(损失应该减少,Token 准确率应该提高)。在微调任务运行时,您可以查看一个事件对象,其中包含一些有用的指标:
{
"object": "fine_tuning.job.event",
"id": "ftevent-abc-123",
"created_at": 1693582679,
"level": "info",
"message": "Step 300/300: training loss=0.15, validation loss=0.27, full validation loss=0.40",
"data": {
"step": 300,
"train_loss": 0.14991648495197296,
"valid_loss": 0.26569826706596045,
"total_steps": 300,
"full_valid_loss": 0.4032616495084362,
"train_mean_token_accuracy": 0.9444444179534912,
"valid_mean_token_accuracy": 0.9565217391304348,
"full_valid_mean_token_accuracy": 0.9089635854341737
},
"type": "metrics"
}
在微调任务完成后,您可以通过 查询微调任务,从 result_files 中提取文件 ID,然后 获取文件内容,来查看训练过程中的指标。每个结果 CSV 文件包含以下列:step(步骤)、train_loss(训练损失)、train_accuracy(训练准确率)、valid_loss(验证损失)和 valid_mean_token_accuracy(验证平均 Token 准确率)。
step,train_loss,train_accuracy,valid_loss,valid_mean_token_accuracy
1,1.52347,0.0,,
2,0.57719,0.0,,
3,3.63525,0.0,,
4,1.72257,0.0,,
5,1.52379,0.0,,
虽然指标很有帮助,但评估微调模型生成的样本能更好地体现模型质量。我们建议在测试集上同时生成基线模型和微调模型的样本,并进行对比。理想情况下,测试集应包含所有可能在实际使用中输入给模型的内容。如果手动评估过于耗时,可以考虑使用我们的Evals 库来自动化未来的评估。
迭代数据质量
如果微调结果不如预期,可以考虑通过以下方法调整训练数据集:
- 收集新的示例以解决剩余问题
- 如果模型在某些方面仍有不足,增加展示正确做法的训练示例
- 仔细检查现有示例是否存在问题
- 如果模型在语法、逻辑或风格上存在问题,检查您的数据是否有类似问题。例如,如果模型不应该说“我将为您安排会议”,但它却这么说了,看看是否有示例教它说它能做一些实际上不能做的事情
- 考虑数据的平衡和多样性
- 如果训练数据中 60% 的助手回答是“我不能回答这个问题”,但实际应用中只有 5% 的回答应该这样说,那么模型可能会产生过多的拒绝回答
- 确保训练示例包含生成正确响应所需的所有信息
- 例如,如果希望模型根据用户的个人特点给予称赞,而训练示例中包含了对未在对话中提到的特征的称赞,模型可能会学会编造信息
- 检查训练示例的一致性
- 如果训练数据由多个人创建,模型性能可能会受到人员一致性水平的限制。例如,在文本抽取任务中,如果人员只在 70% 的抽取片段上达成一致,模型可能无法表现得更好
- 确保所有训练示例的格式一致,符合推理的预期
迭代数据量
在对数据质量和分布感到满意后,您可以考虑增加训练示例的数量。这通常有助于模型更好地学习任务,特别是处理可能的“边缘情况”。我们预计每次将训练示例数量翻倍时,都会看到类似的改进。您可以通过以下方式粗略估计增加训练数据量带来的质量提升:
- 在当前数据集上进行微调
- 在当前数据集的一半上进行微调
- 观察两者之间的质量差距
一般来说,如果必须在数量和质量之间进行权衡,少量高质量的数据通常比大量低质量的数据更有效。
迭代超参数
我们允许您指定以下超参数:
- 训练轮数(epochs)
- 学习率乘数
- 批处理大小
我们建议最初训练时不指定任何这些参数,让我们根据数据集大小为您选择默认值,然后在观察到以下情况时进行调整:
- 如果模型没有按照预期遵循训练数据,增加 1 或 2 个训练轮数
- 这在只有单一理想完成(或一组相似的理想完成)的任务中更常见。例如分类、实体抽取或结构化解析等任务,这些任务通常可以根据参考答案计算最终准确率。
- 如果模型的多样性低于预期,减少 1 或 2 个训练轮数
- 这在有多种可能的好完成的任务中更常见
- 如果模型看起来没有收敛,增加学习率乘数
您可以如下设置超参数:
from openai import OpenAI
client = OpenAI()
client.fine_tuning.jobs.create(
training_file="file-abc123",
model="gpt-3.5-turbo",
hyperparameters={
"n_epochs":2
}
)
微调示例
现在我们已经了解了微调 API 的基础知识,让我们看看如何在不同的用例中进行微调的全生命周期操作。
风格和语气
在这个示例中,我们将探讨如何构建一个微调模型,使其遵循特定的风格和语气指导,这是单靠提示无法实现的。
首先,我们创建一个消息示例集,展示模型应如何在特定情况下拼写错误的单词。
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?"}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters."}]}
如果您想跟随示例自己创建一个微调模型,您需要至少 10 个示例。
在获得可能改进模型的数据后,下一步是检查数据是否符合所有格式要求。
现在我们已经对数据进行了格式化和验证,最后一步是启动任务以创建微调模型。您可以通过 OpenAI CLI 或我们的 SDK 来完成,具体如下所示:
from openai import OpenAI
client = OpenAI()
file = client.files.create(
file=open("marv.jsonl", "rb"),
purpose="fine-tune"
)
client.fine_tuning.jobs.create(
training_file=file.id,
model="gpt-3.5-turbo"
)
训练任务完成后,您就可以使用您的微调模型了。
结构化输出
另一种非常适合微调的用例是让模型提供结构化信息,例如关于体育新闻标题的信息:
{"messages": [{"role": "system", "content": "Given a sports headline, provide the following fields in a JSON dict, where applicable: \"player\" (full name), \"team\", \"sport\", and \"gender\"."}, {"role": "user", "content": "Sources: Colts grant RB Taylor OK to seek trade"}, {"role": "assistant", "content": "{\"player\": \"Jonathan Taylor\", \"team\": \"Colts\", \"sport\": \"football\", \"gender\": \"male\" }"}]}
{"messages": [{"role": "system", "content": "Given a sports headline, provide the following fields in a JSON dict, where applicable: \"player\" (full name), \"team\", \"sport\", and \"gender\"."}, {"role": "user", "content": "OSU 'split down middle' on starting QB battle"}, {"role": "assistant", "content": "{\"player\": null, \"team\": \"OSU\", \"sport\": \"football\", \"gender\": null }"}]}
如果您想跟随示例自己创建一个微调模型,您需要至少 10 个示例。
在获得可能改进模型的数据后,下一步是检查这些数据是否符合所有格式要求。
现在我们已经对数据进行了格式化和验证,最后一步是启动任务以创建微调模型。您可以通过 OpenAI CLI 或我们的 SDK 来完成,具体如下所示:
from openai import OpenAI
client = OpenAI()
file = client.files.create(
file=open("sports-context.jsonl", "rb"),
purpose="fine-tune"
)
client.fine_tuning.jobs.create(
training_file=file.id,
model="gpt-3.5-turbo"
)
训练任务完成后,您就可以使用您的微调模型并发送如下请求:
completion = client.chat.completions.create(
model="ft:gpt-3.5-turbo:my-org:custom_suffix:id",
messages=[
{"role": "system", "content": "Given a sports headline, provide the following fields in a JSON dict, where applicable: player (full name), team, sport, and gender"},
{"role": "user", "content": "Richardson wins 100m at worlds to cap comeback"}
]
)
print(completion.choices[0].message)
根据格式化的训练数据,响应应该如下所示:
{
"player": "Sha'Carri Richardson",
"team": null,
"sport": "track and field",
"gender": "female"
}
Tool calling
聊天完成 API 支持工具调用。在完成 API 中包含长列表工具会消耗大量的提示 tokens,有时模型会产生幻觉或不提供有效的 JSON 输出。
通过包含工具调用示例进行微调,可以使模型:
- 即使没有完整的工具定义,也能生成格式一致的响应
- 输出更准确和一致
请按照如下格式准备您的示例,每行包含一个“消息”列表和一个可选的“工具”列表:
{
"messages": [
{ "role": "user", "content": "What is the weather in San Francisco?" },
{
"role": "assistant",
"tool_calls": [
{
"id": "call_id",
"type": "function",
"function": {
"name": "get_current_weather",
"arguments": "{\"location\": \"San Francisco, USA\", \"format\": \"celsius\"}"
}
}
]
}
],
"tools": [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and country, eg. San Francisco, USA"
},
"format": { "type": "string", "enum": ["celsius", "fahrenheit"] }
},
"required": ["location", "format"]
}
}
}
]
}
{
"messages": [
{"role": "user", "content": "What is the weather in San Francisco?"},
{"role": "assistant", "tool_calls": [{"id": "call_id", "type": "function", "function": {"name": "get_current_weather", "arguments": "{\"location\": \"San Francisco, USA\", \"format\": \"celsius\"}"}}]}
{"role": "tool", "tool_call_id": "call_id", "content": "21.0"},
{"role": "assistant", "content": "It is 21 degrees celsius in San Francisco, CA"}
],
"tools": [...] // same as before
}
并行函数调用默认启用,可以在训练示例中使用parallel_tool_calls: false来禁用。
Funcation calling
function_call和functions参数已被弃用,建议使用tools参数替代。
聊天完成 API 支持函数调用。在完成 API 中包含长列表函数会消耗大量提示 tokens,有时模型会产生幻觉或不提供有效的 JSON 输出。
通过包含函数调用示例进行微调,可以让模型:
- 即使没有完整的函数定义,也能生成格式一致的响应
- 输出更准确和一致
请按照如下格式准备您的示例,每行包括一个“消息”列表和一个可选的“函数”列表:
{
"messages": [
{ "role": "user", "content": "What is the weather in San Francisco?" },
{
"role": "assistant",
"function_call": {
"name": "get_current_weather",
"arguments": "{\"location\": \"San Francisco, USA\", \"format\": \"celsius\"}"
}
}
],
"functions": [
{
"name": "get_current_weather",
"description": "Get the current weather",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and country, eg. San Francisco, USA"
},
"format": { "type": "string", "enum": ["celsius", "fahrenheit"] }
},
"required": ["location", "format"]
}
}
]
}
如果您想跟随示例自己创建一个微调模型,您需要至少 10 个示例。
如果您的目标是减少 token 的使用量,可以使用以下技巧:
- 省略函数和参数描述:移除函数和参数中的描述字段
- 省略参数:移除参数对象中的整个 properties 字段
- 完全省略函数:从 functions 数组中移除整个函数对象
如果您的目标是最大化函数调用输出的准确性,我们建议在训练和查询微调模型时使用相同的函数定义。
通过函数调用进行微调还可以定制模型对函数输出的响应。为此,您可以包括一个函数响应消息和一个解释该响应的助手消息:
{
"messages": [
{"role": "user", "content": "What is the weather in San Francisco?"},
{"role": "assistant", "function_call": {"name": "get_current_weather", "arguments": "{\"location\": \"San Francisco, USA\", \"format\": \"celsius\"}"}}
{"role": "function", "name": "get_current_weather", "content": "21.0"},
{"role": "assistant", "content": "It is 21 degrees celsius in San Francisco, CA"}
],
"functions": [...] // same as before
}
微调集成
OpenAI 提供了通过集成框架将微调任务与第三方系统进行集成的功能。集成通常允许您在第三方系统中跟踪任务状态、指标、超参数和其他任务相关信息。您还可以使用集成在任务状态变化时在第三方系统中触发操作。目前,唯一支持的集成是与Weights and Biases(W&B)的集成,但更多集成即将推出。
Weights and Biases 集成
Weights and Biases (W&B) 是一个流行的机器学习实验跟踪工具。您可以使用 OpenAI 与 W&B 的集成在 W&B 中跟踪您的微调任务。此集成会自动将指标、超参数和其他任务相关信息记录到您指定的 W&B 项目中。
要将您的微调任务与 W&B 集成,您需要:
- 向 OpenAI 提供您的 Weights and Biases 账户的认证凭证
- 在创建新微调任务时配置 W&B 集成
认证您的 Weights and Biases 账户与 OpenAI
认证通过向 OpenAI 提交有效的 W&B API 密钥来完成。目前,这只能通过账户仪表板完成,并且只能由账户管理员完成。您的 W&B API 密钥将在 OpenAI 内部加密存储,并允许 OpenAI 在您的微调任务运行时代表您向 W&B 发布指标和元数据。如果在没有首先认证您的 OpenAI 组织与 W&B 的情况下尝试在微调任务上启用 W&B 集成,将导致错误。
启用 Weights and Biases 集成
在创建新的微调任务时,您可以通过在任务创建请求中的integrations字段下包含一个新的"wandb"集成来启用 W&B 集成。此集成允许您指定希望新创建的 W&B 任务显示在哪个 W&B 项目下。
以下是创建新微调任务时启用 W&B 集成的示例:
curl -X POST \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-3.5-turbo-0125",
"training_file": "file-ABC123",
"validation_file": "file-DEF456",
"integrations": [
{
"type": "wandb",
"wandb": {
"project": "custom-wandb-project",
"tags": ["project:tag", "lineage"]
}
}
]
}' https://api.openai.com/v1/fine_tuning/jobs
默认情况下,运行 ID 和显示名称是您的微调任务的 ID(例如ftjob-abc123)。您可以通过在wandb对象中包含"name"字段来自定义运行的显示名称。您还可以在wandb对象中包含"tags"字段,以添加标签到 W&B 运行(标签必须少于等于 64 个字符,最多 50 个标签)。
有时显式设置与运行关联的W&B 实体是很方便的。您可以通过在wandb对象中包含"entity"字段来完成此操作。如果不包含"entity"字段,W&B 实体将默认为您之前注册的 API 密钥关联的默认 W&B 实体。
集成的完整规范可以在我们的微调任务创建文档中找到。
在 Weights and Biases 中查看您的微调任务
启用 W&B 集成后创建微调任务后,您可以通过导航到任务创建请求中指定的 W&B 项目来在 W&B 中查看任务。您的任务应位于 URL:https://wandb.ai/<WANDB-ENTITY>/<WANDB-PROJECT>/runs/ftjob-ABCDEF。
您应会看到一个带有您在任务创建请求中指定的名称和标签的新任务。任务配置将包含相关的任务元数据,例如:
model:您正在微调的模型training_file:训练文件的 IDvalidation_file:验证文件的 IDhyperparameters:任务使用的超参数(例如n_epochs、learning_rate、batch_size)seed:任务使用的随机种子
同样,OpenAI 将在任务上设置一些默认标签,以便您更轻松地搜索和过滤。这些标签将以"openai/"为前缀,并包括:
openai/fine-tuning:标识这是一个微调任务的标签openai/ft-abc123:微调任务的 IDopenai/gpt-3.5-turbo-0125:您正在微调的模型
以下是从 OpenAI 微调任务生成的 W&B 运行示例:
每个微调任务步骤的指标将记录到 W&B 任务中。这些指标与微调任务事件对象中提供的指标相同,也是您可以通过OpenAI 微调仪表板查看的指标。您可以使用 W&B 的可视化工具来跟踪微调任务的进展,并将其与您运行的其他微调任务进行比较。
以下是记录到 W&B 任务的指标示例:
常见问题
我应该何时使用微调与嵌入/检索增强生成?
嵌入检索最适合在您需要拥有大量相关背景和信息的文档数据库时使用。
默认情况下,OpenAI 的模型被训练为通用助手。微调可以使模型专注于特定领域,展现特定的行为模式。检索策略可以在生成响应之前通过提供相关背景使模型能够访问新信息。检索策略不是微调的替代方案,实际上它们可以相辅相成。
您可以在我们的开发者日演讲中进一步探索这些选项之间的区别:
我可以微调 GPT-4o、GPT-4 Turbo 或 GPT-4 吗?
GPT-4 微调处于实验性访问阶段,符合条件的开发者可以通过微调 UI申请访问。GPT-4 微调适用于gpt-4-0613和gpt-4o-2024-05-13模型(不适用于任何gpt-4-turbo模型)。
gpt-3.5-turbo-1106和gpt-3.5-turbo-0125支持最多 16K 上下文示例。
我如何知道我的微调模型是否真的比基础模型更好?
我们建议在测试集上同时生成基线模型和微调模型的样本,并进行对比。对于更全面的评估,考虑使用OpenAI 评估框架创建特定于您的用例的评估。
我可以继续微调已经微调过的模型吗?
可以,您可以在创建微调任务时将微调模型的名称传递给model参数。这将使用微调模型作为起点开始一个新的微调任务。
我如何估算微调模型的成本?
请参阅上面的成本估算部分。
我可以同时运行多少个微调任务?
请参阅我们的速率限制页面以获取最新的限制信息。
微调模型的速率限制如何工作?
微调模型与其基础模型共享相同的速率限制。例如,如果您在给定时间段内使用标准gpt-3.5-turbo模型消耗了一半的 TPM 速率限制,您从gpt-3.5-turbo微调的任何模型将只能访问剩余的一半 TPM 速率限制,因为同类型模型共享相同的容量。
换句话说,从总吞吐量的角度来看,拥有微调模型不会为您提供更多的模型使用容量。
我可以使用 /v1/fine-tunes 端点吗?
/v1/fine-tunes端点已被弃用,取而代之的是/v1/fine_tuning/jobs端点。
对于从/v1/fine-tunes迁移到更新的/v1/fine_tuning/jobs API 和更新模型的用户,您可以期待的主要区别是更新的 API。旧的提示-完成对数据格式已被保留用于更新的babbage-002和davinci-002模型,以确保平稳过渡。新模型将支持具有 4k token 上下文的微调,并具有截至 2021 年 9 月的知识截断。
对于大多数任务,您应该期望gpt-3.5-turbo比 GPT 基础模型表现更好。