SimpleQA 是一个新的基准测试,旨在评估语言模型在回答简短、事实性问题时的准确性。该基准测试的核心目标是减少模型产生“幻觉”(即无根据的错误答案)的现象,并提升模型的可信度。SimpleQA 专注于简短的事实查询,确保问题有单一、不可争议的答案,从而使得评估模型的事实性表现更加可行。通过该基准,研究人员可以更好地衡量语言模型的准确性、校准性及其在不同问题类别中的表现。
SimpleQA 的特点:
- 高正确性:所有问题的参考答案由两名独立的 AI 训练师提供,并且这些问题经过严格筛选,以确保答案易于评分。
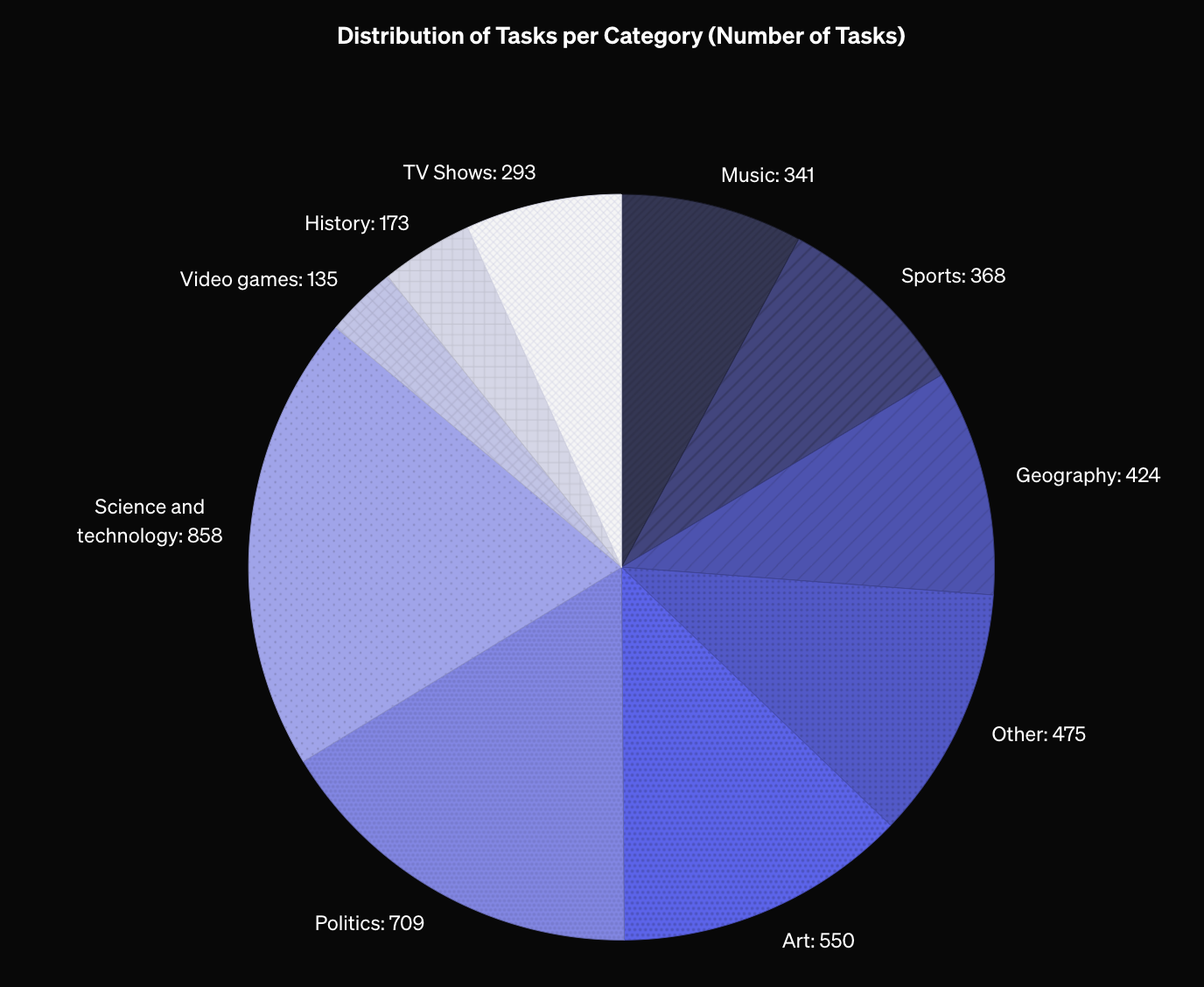
- 多样性:涵盖广泛主题,包括科学、技术、历史、音乐、视频游戏等多个领域。
- 挑战性:相比于老旧的基准(如 TriviaQA 和 NQ),SimpleQA 对前沿模型(如 GPT-4o)更具挑战性。
- 研究友好:由于问题简洁,SimpleQA 的运行速度快,评分效率高。
数据集构建:
- 问题由 AI 训练师从网上搜集,确保每个问题有单一、不可争议的答案。
- 为确保质量,问题经过三轮验证,最终的错误率约为 3%。
模型评估方法:
- 使用 ChatGPT 分类器对模型的答案进行评分,分为“正确”、“错误”和“未尝试”三类。
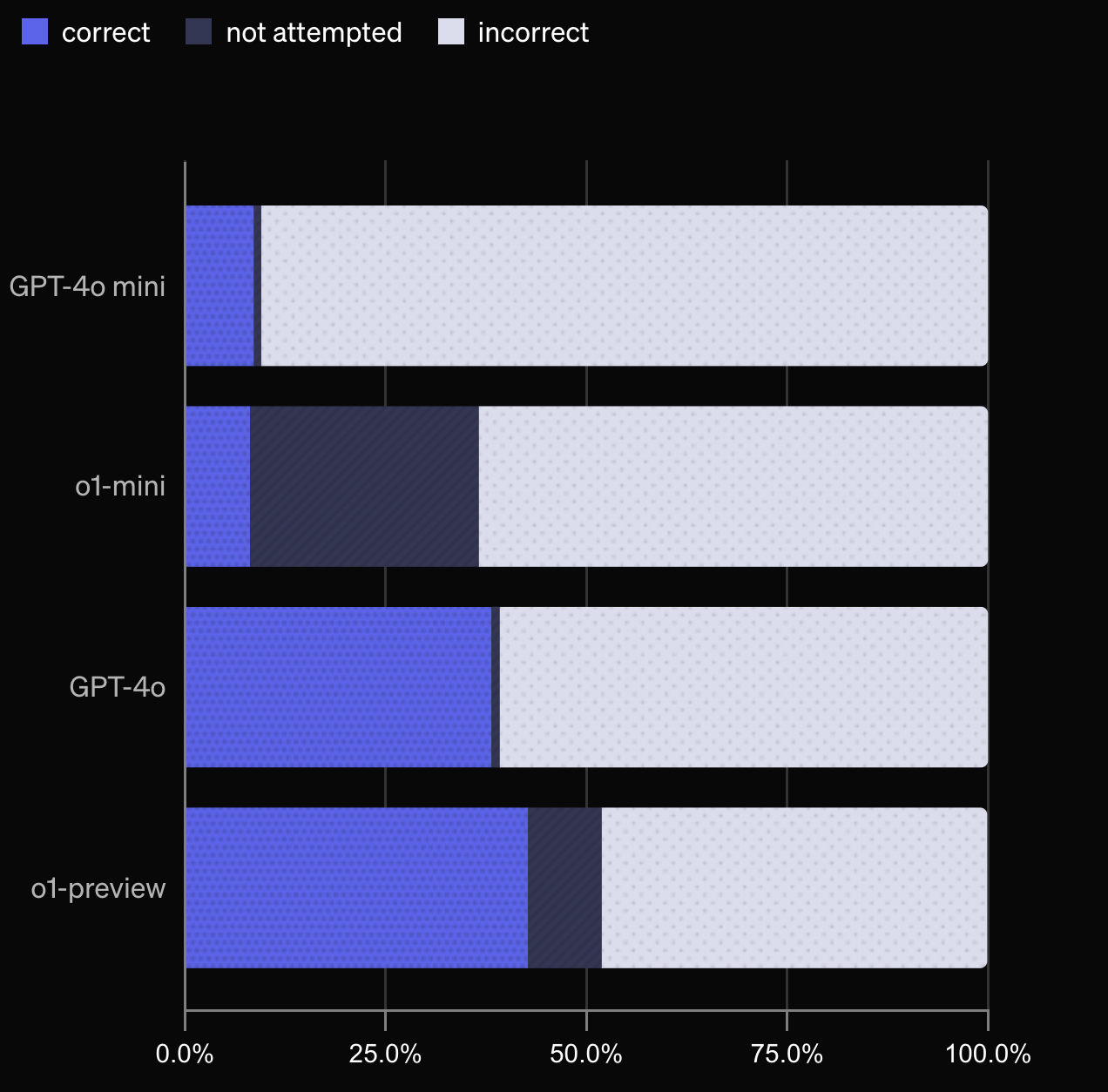
- 测试表明,较大的模型(如 GPT-4o 和 o1-preview)比较小的模型(如 GPT-4o-mini 和 o1-mini)表现更好,且后者更倾向于“未尝试”问题,表明它们可能更擅长判断何时不确定答案。
模型校准性:
- 校准性指模型对其回答的自信程度是否与实际准确性一致。SimpleQA 提供了两种方法来测量模型的校准性:一是通过模型自述的信心百分比,二是通过模型多次回答同一问题的频率。
- 结果显示,较大的模型(如 o1-preview 和 GPT-4o)在校准性上表现更好,但模型普遍倾向于过高估计其自信度。
结论与局限性:
- SimpleQA 是一个简洁但具有挑战性的基准,专注于短、事实性问题。然而,它的局限性在于仅测量简短回答的事实性,尚不清楚这是否与模型生成长篇、多事实回答的能力相关。
介绍一下 SimpleQA
2024 年 10 月 30 日
SimpleQA 是一个衡量语言模型回答简短、寻求事实的问题的能力的基准工具。
在人工智能领域中,一个未解决的问题是如何训练模型,使其生成的回答更加符合事实。当前的语言模型有时会产生错误的输出,或提供没有证据支撑的回答,这种现象被称为“幻觉”。生成更为准确、幻觉更少的语言模型可以增加可信度,并能够应用于更广泛的领域。为此,我们 开源了(新窗口打开)一个名为 SimpleQA 的新基准工具,以衡量语言模型的事实性。
关于 SimpleQA 基准
事实性是一个复杂的话题,因为其评估难度很大——评价任意声明的真实度颇具挑战性,而语言模型可能会生成包含大量事实性信息的长篇回答。在 SimpleQA 中,我们专注于简短的、寻求事实的查询,尽管这缩小了评估范围,但使得衡量事实性变得更为可行。
我们创建 SimpleQA 数据集的目标是实现以下特性:
高准确性。 所有问题的参考答案均有两位独立 AI 训练师提供支持,问题设计也便于答案的评分。
主题多样性。 SimpleQA 覆盖了广泛的主题,从科学与技术到影视节目和电子游戏。
对前沿模型具有挑战性。 与较早的基准如 TriviaQA(新窗口打开) (2017) 或 NQ(新窗口打开) (2019) 相比,这些基准已趋于饱和,而 SimpleQA 则旨在对前沿模型提出更大挑战(例如 GPT-4o 得分低于 40%)。
良好的用户体验。 SimpleQA 问题和答案简洁明了,便于快速运行和评分,支持通过 OpenAI API 或其他前沿模型 API 进行高效评估。此外,SimpleQA 包含 4,326 个问题,评估的稳定性较高。
我们雇佣了 AI 训练师浏览网络,设计简短的寻求事实的问题及答案。每个问题必须符合严格的标准:它必须有一个单一且不可争议的答案,以便评分;答案应该不会随时间而变化;大部分问题会引发 GPT-4o 或 GPT-3.5 出现幻觉。此外,另一位独立 AI 训练师在未见到原始答案的情况下回答每个问题,只有两位训练师的答案一致的问题才会被纳入数据集。
为进一步验证质量,我们要求第三位 AI 训练师对随机抽取的 1,000 个问题作答,结果发现与原答案的一致率达到了 94.4%,不一致率为 5.6%。我们随后手动检查这些不一致示例,发现其中 2.8% 是因评分误判或人为错误(如回答不完整或误解来源)造成的,剩下的 2.8% 则是由于问题本身存在模糊性或多个网站给出冲突信息引起。因此,我们估计该数据集的固有错误率约为 3%。
SimpleQA 中的问题多样性
下图的饼图展示了 SimpleQA 数据集中各主题的多样性。
使用 SimpleQA 比较语言模型
在问题评分时,我们使用一个经过提示的 ChatGPT 分类器来评估模型预测的答案。该分类器会同时查看预测答案与真实答案,并将预测答案分为“正确”、“错误”或“未尝试”。
下表中展示了每个评分的定义和示例。
| 评分 | 定义 | 问题 “2022 年荷兰 vs 阿根廷男足世界杯比赛中哪位荷兰球员打入运动战进球?” 的示例 (答案: Wout Weghorst) |
|---|---|---|
| “正确” | 预测答案包含真实答案且没有矛盾。 |
|
| “错误” | 预测答案在某方面与真实答案矛盾。 |
|
| “未尝试” | 答案未包含完整的真实目标,且无矛盾。 |
|
理想情况下,模型应尽可能多地正确回答问题,并尽量减少错误答案。
通过这种分类,我们可以测量多个 OpenAI 模型的表现,包括 gpt-4o-mini、o1-mini、gpt-4o 和 o1-preview。正如预期,gpt-4o-mini 和 o1-mini 的正确回答数量低于 gpt-4o 和 o1-preview,因为较小的模型通常掌握的知识较少。同时,o1-mini 和 o1-preview 更频繁选择“不尝试”而不是产生幻觉,这可能是因为它们可以利用推理能力来识别无法确定的答案。
使用 SimpleQA 测量大语言模型的校准性
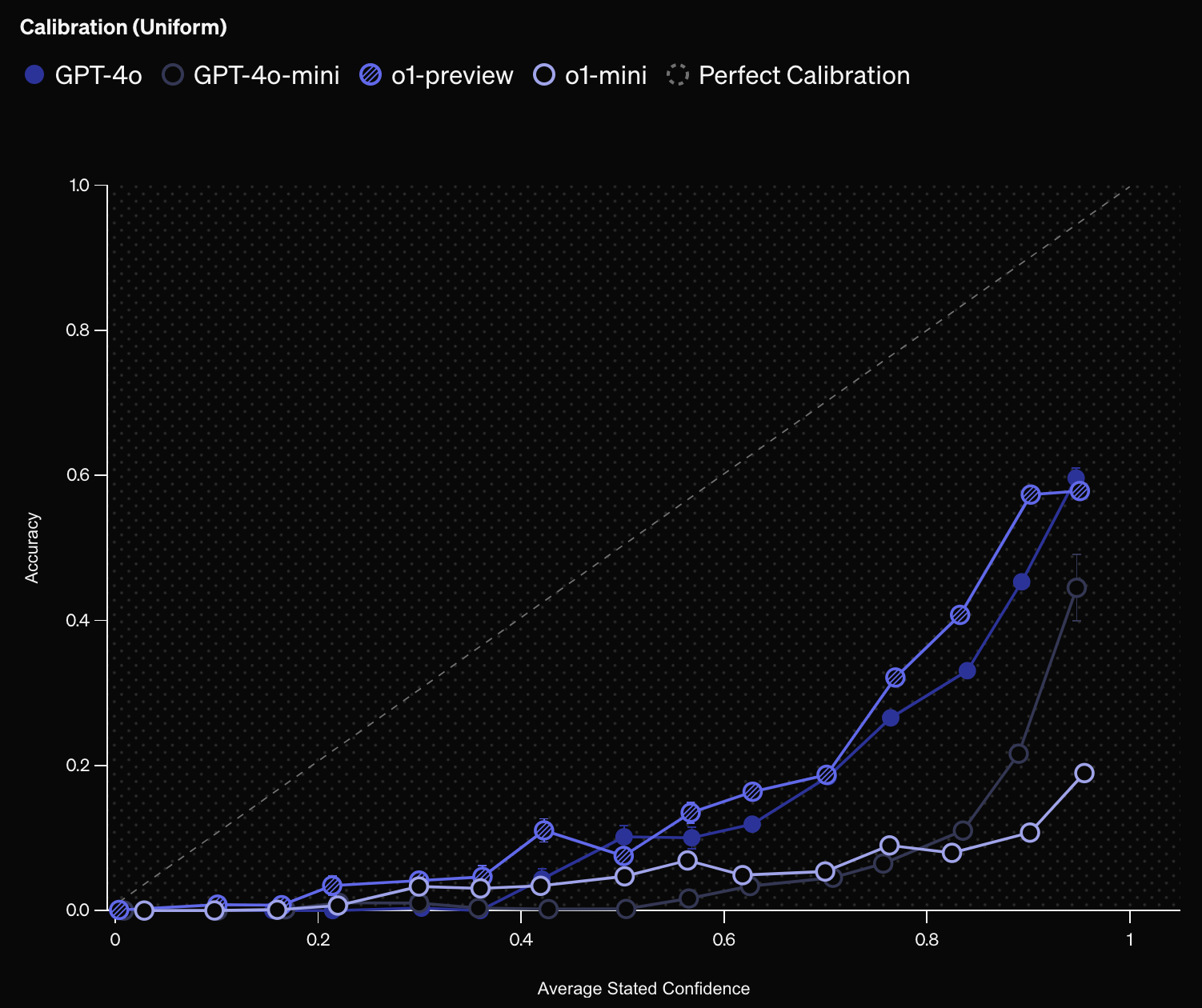
SimpleQA 这样的事实性基准也能帮助测量“校准性”,即语言模型是否“了解自己掌握的内容”。一种测量校准性的方法是直接要求模型表述对答案的信心,例如提示语:“请给出您的最佳猜测,并附上您对正确答案的置信度百分比。”然后绘制模型置信度和实际准确率的相关图。一个完全校准的模型应在所有声称置信度为 75% 的提示上达到 75% 的准确率。
结果显示在下图中。模型的置信度和准确率之间的正相关表明模型对自身信心的合理性。我们发现 o1-preview 的校准性优于 o1-mini,而 gpt4o 的校准性优于 gpt4o-mini,这与已有研究(新窗口打开)一致,表明较大的模型通常校准性更好。然而模型总体上倾向于高估置信度,因此在置信度校准性方面仍有改进空间。
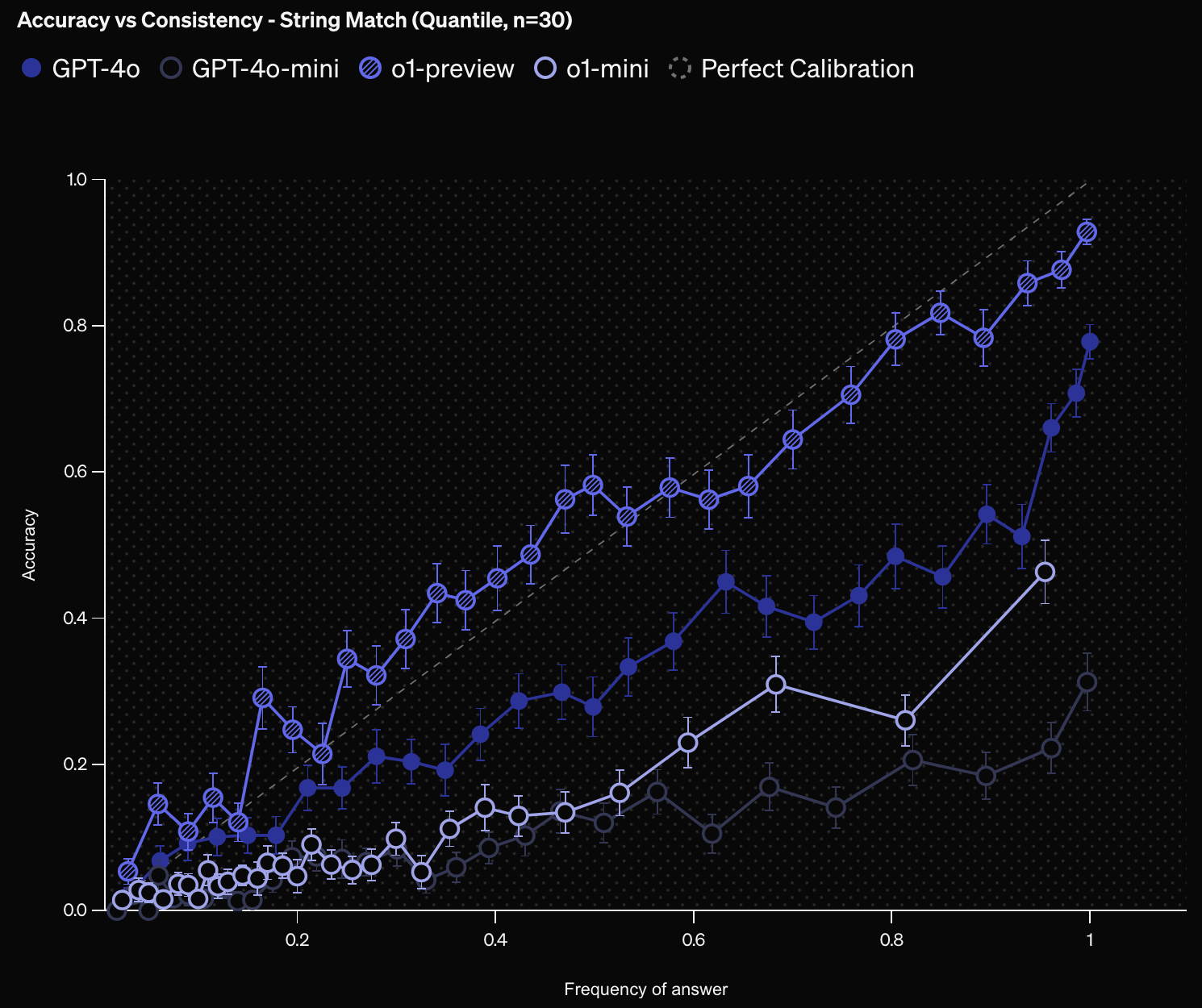
另一种衡量校准性的方法是对同一问题提问多次,评估答案的频率是否反映正确性。更高的频率表示模型对答案信心更高,因为多次给出相同答案。良好校准的模型应显示答案频率与正确性的一致性。
下图展示了基于答案频率的模型校准性评估结果。总体来看,准确率随频率增加而提升,且 o1-preview 的校准性最高,频率与准确率大致一致。与置信度校准图类似,o1-preview 的校准性优于 o1-mini,gpt4o 的校准性优于 gpt4o-mini。
结论
SimpleQA 是一个用于评估前沿模型事实性的问题集,具有简洁但富有挑战的特点。SimpleQA 的局限性在于其范围仅限于简短的单一可验证答案的问题,而是否能够提供事实性短答案与生成复杂长篇回答的能力相关,仍待研究。我们希望 SimpleQA 的开源能够推动更可信 AI 的研究,并欢迎研究人员使用 SimpleQA 评估语言模型的事实性,提供反馈意见。