本文由 OpenAI 官方文档 翻译而来,介绍了推理模型 (reasoning models) 和 GPT 模型 (GPT models) 的区别,以及何时使用推理模型 (reasoning models)。
OpenAI 提供两种类型的模型:推理模型 (reasoning models),例如 o1 和 o3-mini,以及 GPT 模型 (GPT models),例如 GPT-4o。这两类模型的行为特性有所不同。
本指南将介绍:
- OpenAI 的推理型模型和非推理型 GPT 模型之间的差异
- 何时应该使用推理模型 (reasoning models)
- 如何有效地提示推理模型 (reasoning models)
推理模型与 GPT 模型对比
与 GPT 模型 (GPT models) 相比,OpenAI 的 o 系列模型在不同任务上各有优势,并且需要的提示方式也不同。 它们之间不存在绝对的优劣之分,只是擅长的领域不同。
OpenAI 训练 o 系列模型(可以称它们为“规划者”)能够花费更多时间和精力思考复杂的任务,使它们在以下方面表现出色:制定战略、规划复杂问题的解决方案、以及基于大量模糊信息做出决策。 这些模型还能以极高的精度和准确性执行任务,非常适合那些通常需要人类专家才能胜任的领域,例如数学、科学、工程、金融和法律服务。
另一方面,低延迟、高性价比的 GPT 模型 (GPT models)(可以称它们为“主力”)则专为直接执行任务而设计。 在实际应用中,可以利用 o 系列模型来规划解决问题的总体策略,然后使用 GPT 模型 (GPT models) 执行具体任务,尤其是在对速度和成本的考量高于对完美准确性的追求时。
如何选择
对于你的应用场景,什么才是最重要的?
- 速度和成本 → GPT 模型 (GPT models) 速度更快,成本通常也更低。
- 执行定义明确的任务 → GPT 模型 (GPT models) 擅长处理清晰定义的任务。
- 准确性和可靠性 → o 系列模型是值得信赖的决策者。
- 复杂问题解决 → o 系列模型能够应对模糊性和复杂性。
如果在完成任务时,速度和成本是最关键的因素,*并且* 你的用例由简单、定义明确的任务组成,那么 GPT 模型 (GPT models) 将会是最佳选择。 但是,如果准确性和可靠性至关重要,*并且* 你需要解决非常复杂的多步骤问题,那么 o 系列模型可能更适合。
在大多数 人工智能 (AI) 工作流程中,通常会结合使用这两种模型:o 系列模型用于智能规划和决策,而 GPT 系列模型用于执行任务。
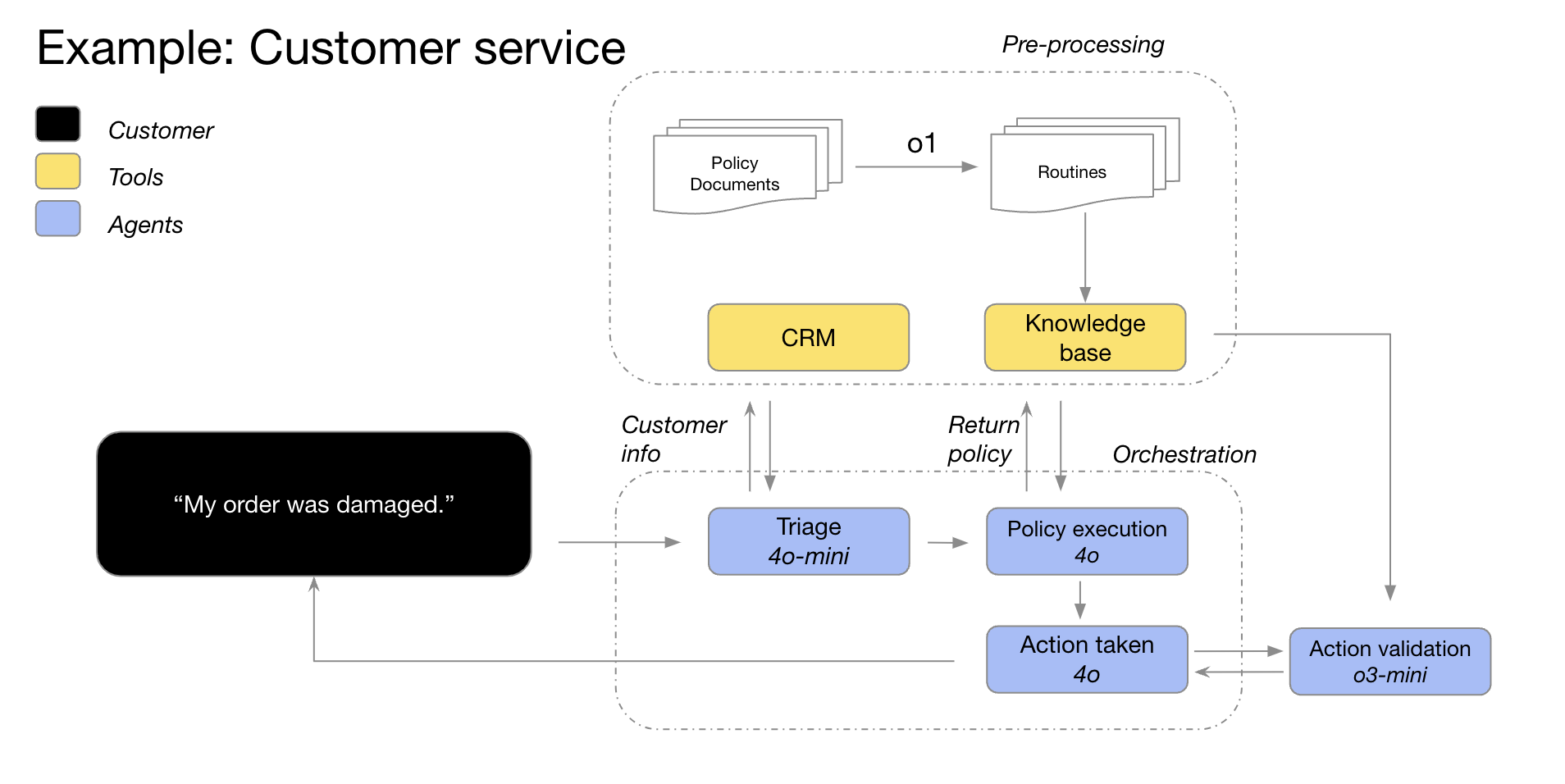
例如,OpenAI 的 GPT-4o 和 GPT-4o mini 模型可以利用客户信息对订单细节进行分类,识别订单中的问题和退货政策,然后将所有这些信息提供给 o3-mini,以便根据政策最终决定是否允许退货。
这个架构图画的很好,这里我来详细说明一下,方便大家理解。一个完整的客户服务流程通常需要多个系统和资源协同工作:CRM 提供客户和订单信息,知识库和政策文档提供业务规则与解决方案,Routine 是在实际业务中需要执行的一些预定义步骤或脚本,比如常见的合规检查、退款流程、打折/补偿流程等。Policy Documents 会作为输入并通过 o1 模型进行更新和维护 Routines。
1. Triage(分类)阶段通常用于识别客户问题的类型和优先级,判断是要进入什么具体流程,比如:退货/换货流程、维修/技术支持流程、进一步人工介入等
2. Policy execution (策略执行)阶段会根据知识库中的具体政策(以及Triage给出的分类信息)执行相应的业务策略。如计算需要退款或补寄物品等。
4. Action taken 阶段真正去执行操作或记录操作后果,比如生成换货订单、启动赔付流程等。
5. Action validation 阶段通验证上一步的操作是否符合流程与预期,比如:检查是否按照退货政策在正确的额度范围内完成退款;检查换货流程是否成功触发;确保没有超出授权范围或者系统冲突等。
何时使用推理模型 (reasoning models)
以下是 OpenAI 从客户和内部观察到的一些成功的使用案例。 这不是对所有可能用例的全面回顾,而是为测试 OpenAI 的 o 系列模型提供一些实用的指导。
1. 处理模糊不清的任务
推理模型 (reasoning models) 尤其擅长处理信息有限或信息分散的情况,它们可以通过简单的提示理解用户的意图,并弥补指令中的任何信息缺口。 实际上,推理模型 (reasoning models) 通常会在做出没有根据的猜测或试图填补信息空白之前,先提出一些澄清问题。
“o1 的推理能力使我们的多智能体平台 Matrix 能够在处理复杂文档时生成详尽、格式良好且详细的响应。 例如,o1 使 Matrix 能够通过基本提示轻松识别信用协议中受限支付能力下可用的购物篮。 之前的模型都没有如此出色的性能。 与其他模型相比,o1 在对密集信用协议进行的 52% 的复杂提示中产生了更出色的结果。”
—Hebbia, 面向法律和金融的 人工智能 (AI) 知识平台公司
2. 在海量信息中寻找关键线索
当需要处理大量的非结构化信息时,推理模型 (reasoning models) 能够出色地理解并提取最相关的信息来回答问题。
“为了分析公司的收购情况,o1 审查了数十份公司文件(例如合同和租赁协议),以查找可能影响交易的任何复杂条件。 该模型的任务是标记关键条款,并且在执行此操作时,在脚注中找到了一个关键的“控制权变更”条款:如果公司被出售,则必须立即偿还 7500 万美元的贷款。 o1 对细节的极度关注使我们的人工智能 (AI) 智能体能够通过识别关键任务信息来为金融专业人士提供支持。”
—Endex, 人工智能 (AI) 金融情报平台
3. 在大型数据集中发现关联与微妙之处
OpenAI 发现,推理模型 (reasoning models) 尤其擅长分析复杂的文档,这些文档包含数百页密集且非结构化的信息,例如法律合同、财务报表和保险索赔。 这些模型尤其擅长在文档之间建立联系,并根据数据中隐含的潜在信息做出决策。
“税务研究需要整合多个文档才能得出最终的、令人信服的答案。 我们用 o1 替换了 GPT-4o,发现 o1 在推理文档之间的相互作用方面表现得更好,从而得出了在任何单个文档中都不明显的逻辑结论。 因此,通过切换到 o1,我们看到端到端性能提高了 4 倍,这令人难以置信。”
—Blue J,用于税务研究的 人工智能 (AI) 平台
推理模型 (reasoning models) 还擅长推理细致的政策和规则,并将其应用于当前的任务,从而得出合理的结论。
“在财务分析中,分析师经常需要处理围绕股东权益的复杂情况,并且需要理解相关的法律复杂性。 我们使用一个具有挑战性但常见的问题测试了来自不同提供商的大约 10 个模型:融资如何影响现有股东,特别是当他们行使反稀释权时? 这需要推导融资前和融资后的估值,并处理循环稀释问题,即使是顶级的财务分析师也需要花费 20-30 分钟才能解决。 我们发现 o1 和 o3-mini 可以完美地完成这项任务! 这些模型甚至生成了一个清晰的计算表格,显示了对 10 万美元股东的影响。”
–BlueFlame AI,用于投资管理的人工智能 (AI) 平台
4. 多步骤的智能体规划
推理模型 (reasoning models) 对于智能体规划和策略制定至关重要。 OpenAI 发现,当推理模型 (reasoning models) 被用作“规划者”时,它们可以成功地为问题制定详细的多步骤解决方案,然后根据高智能或低延迟是否最为重要,为每个步骤选择和分配合适的 GPT 模型 (GPT models)(“执行者”)。
“我们在我们的智能体基础设施中使用 o1 作为规划者,让它协调工作流程中的其他模型,从而完成多步骤的任务。 我们发现 o1 非常擅长选择数据类型并将大问题分解为更小的块,从而使其他模型能够专注于执行。”
—Argon AI,面向制药行业的人工智能 (AI) 知识平台
“在 Lindy(我们的工作 人工智能 (AI) 助手)中,o1 为我们的许多智能体工作流程提供支持。 该模型使用函数调用从你的日历或电子邮件中提取信息,然后可以自动帮助你安排会议、发送电子邮件和管理日常任务的其他部分。 我们将所有过去导致问题的智能体步骤都切换到 o1,并观察到我们的智能体几乎在一夜之间变得完美无缺!”
—Lindy.AI,用于工作的人工智能 (AI) 助手
5. 视觉推理
截至今日,o1 是唯一支持视觉功能的推理模型 (reasoning models)。 它与 GPT-4o 的区别在于,即使是结构不清晰的图表和表格,或者图像质量较差的照片,o1 也能轻松理解。
“我们为数百万在线产品(包括奢侈珠宝仿制品、濒危物种和受控物质)自动执行风险和合规性审查。 在我们最困难的图像分类任务中,GPT-4o 的准确率达到了 50%。 在不修改我们流程的情况下,o1 实现了令人惊叹的 88% 的准确率。”
—Safetykit, 人工智能 (AI) 商家监控平台
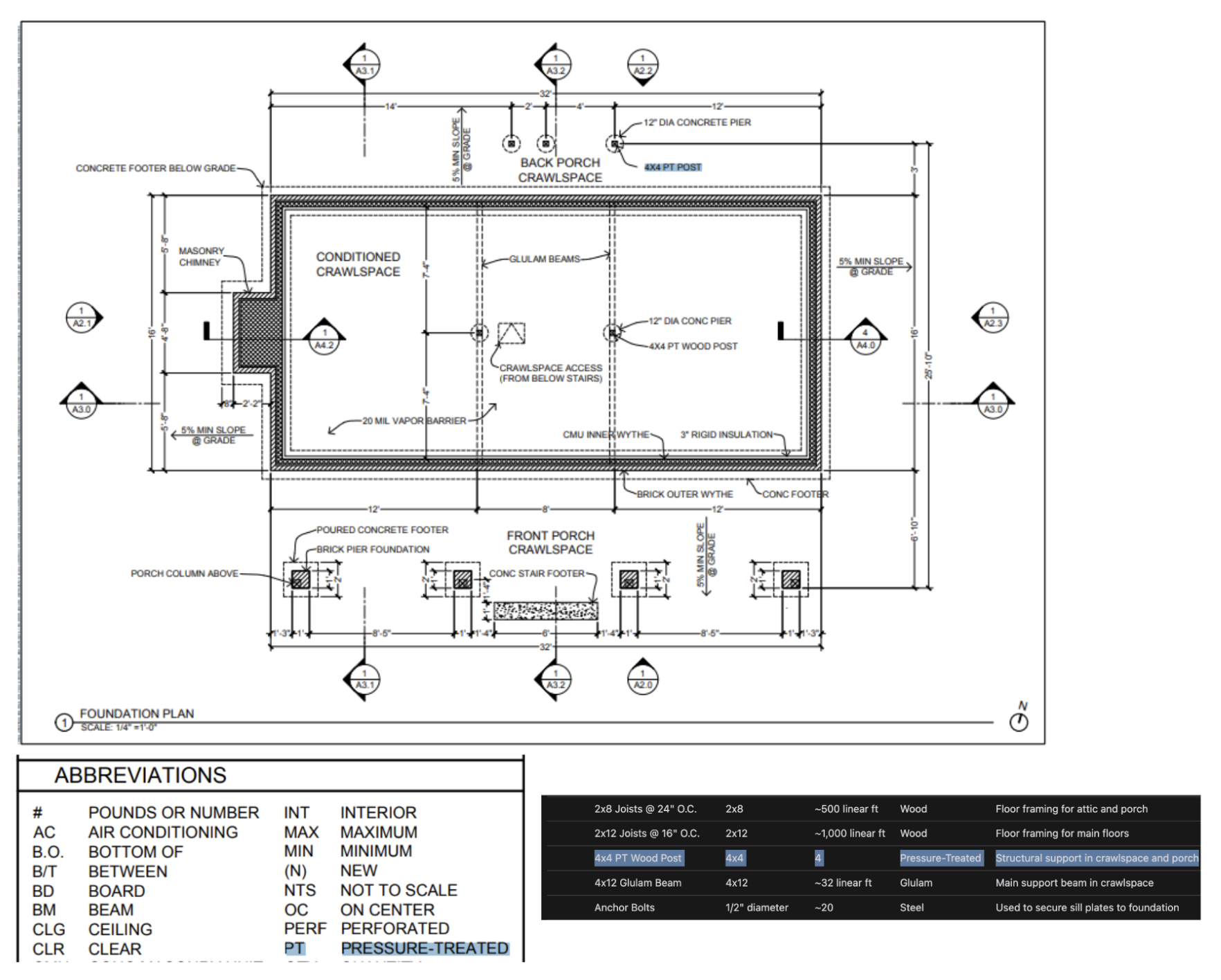
根据 OpenAI 自己的内部测试,我们发现 o1 可以从高度详细的建筑图纸中识别固定装置和材料,从而生成完整的材料清单。 我们观察到的最令人惊讶的事情之一是,o1 能够通过获取建筑图纸一页上的图例,并将其正确地应用到另一页上,从而在不同的图像之间建立联系,而无需明确的指示。 在下面你可以看到,对于 4x4 PT 木柱,o1 能够根据图例识别出“PT”代表经过压力处理。
6. 审查、调试和提高代码质量
推理模型 (reasoning models) 在审查和改进大量代码方面非常有效,考虑到这些模型具有较高的延迟,通常会在后台运行代码审查。
“我们在 GitHub 和 GitLab 等平台上提供自动 人工智能 (AI) 代码审查。 虽然代码审查过程本质上对延迟并不敏感,但它确实需要理解跨多个文件的代码差异。 这正是 o1 真正擅长的地方,它能够可靠地检测代码库中的微小更改,而这些更改可能会被人工审查员忽略。 在切换到 o 系列模型后,我们能够将产品转化率提高 3 倍。”
—CodeRabbit, 人工智能 (AI) 代码审查初创公司
虽然 GPT-4o 和 GPT-4o mini 可能更适合以较低的延迟编写代码,但我们也观察到 o3-mini 在对延迟不太敏感的用例中,代码生成能力也显著提高。
“o3-mini 始终如一地生成高质量、结论性的代码,并且即使对于非常具有挑战性的编码任务,当问题定义明确时,它也经常能够得出正确的解决方案。 虽然其他模型可能只适用于小规模、快速的代码迭代,但 o3-mini 擅长规划和执行复杂的软件设计系统。”
—Codeium, 人工智能 (AI) 驱动的代码扩展初创公司
7. 评估其他模型的响应并进行基准测试
OpenAI 还发现,推理模型 (reasoning models) 在基准测试和评估其他模型响应方面表现良好。 数据验证对于确保数据集的质量和可靠性至关重要,尤其是在医疗保健等敏感领域。 传统的验证方法使用预定义的规则和模式,但像 o1 和 o3-mini 这样的高级模型可以理解上下文并推断数据,从而实现更灵活和智能的验证方法。
“许多客户使用 大语言模型 (LLM) 作为评估依据,将其作为他们在 Braintrust 中评估过程的一部分。 例如,一家医疗保健公司可能会使用像 gpt-4o 这样的主力模型来总结患者的问题,然后使用 o1 来评估摘要的质量。 一位 Braintrust 客户发现,评估者的 F1 分数从使用 4o 时的 0.12 提高到了使用 o1 时的 0.74! 在这些用例中,他们发现 o1 的推理能力在发现结果中细微的差异方面发挥了关键作用,尤其是在最困难和最复杂的评分任务中。”
—Braintrust, 人工智能 (AI) 评估平台
如何有效地提示推理模型 (reasoning models)
这些模型在简单的提示下表现最佳。 某些提示工程技巧(例如指示模型“逐步思考”)可能不会提高性能,有时反而会适得其反。 请参阅下面的最佳实践,或从提示示例开始。
- 开发者消息(developer messages)是新的系统消息(system messages):从
o1-2024-12-17开始,推理模型 (reasoning models) 支持开发者消息而不是系统消息,以符合 模型规范 中描述的指挥链行为。 - 保持提示简单直接:这些模型擅长理解和响应简短、清晰的指令。
- 避免链式思考提示:由于这些模型在内部执行推理,因此提示它们"逐步思考"或"解释你的推理"是不必要的。
- 使用分隔符以提高清晰度:使用分隔符(例如 Markdown、XML 标签和节标题)来清晰地指示输入的不同部分,从而帮助模型适当地解释不同的部分。
- 首先尝试 零样本 (Zero-shot) 方式,如果需要,再尝试 少样本 (Few-shot) 方式:推理模型 (reasoning models) 通常不需要少样本示例即可生成良好的结果,因此请尝试首先编写没有示例的提示。 如果你对所需的输出有更复杂的要求,那么在提示中包含一些输入和所需输出的示例可能会有所帮助。 只要确保示例与你的提示指令非常吻合,因为两者之间的差异可能会导致不良结果。
- 提供具体指南:如果有一些你明确希望约束模型响应的方式(例如"提出预算低于 500 美元的解决方案"),请在提示中明确概述这些约束。
- 非常具体地说明你的最终目标:在你的指令中,尝试为成功的响应提供非常具体的参数,并鼓励模型不断推理和迭代,直到它符合你的成功标准。
- Markdown 格式:从
o1-2024-12-17开始,应用程序编程接口 (API) 中的推理模型 (reasoning models) 将避免生成带有 Markdown 格式的响应。 要向模型发出信号,表明你确实希望响应中包含 Markdown 格式,请在你的开发者消息的第一行包含字符串Formatting re-enabled。
其他资源
要获得更多灵感,请访问 OpenAI Cookbook,其中包含示例代码和指向第三方资源的链接。你也可以了解更多关于 OpenAI 的模型和推理能力的信息: