本文由 OpenAI 发布于 2024 年 9 月 12 日。
OpenAI o1 系列模型是新一代通过强化学习训练的大型语言模型,专门用于处理复杂的推理任务。o1 模型在回答问题之前会进行思考,能够在回应用户之前生成一系列内部推理链。o1 模型在科学推理方面表现出色,在 Codeforces 编程竞赛中排名前 11%,并在美国数学奥林匹克竞赛 (AIME) 预选赛中跻身美国前 500 名选手,同时在物理、生物和化学问题的基准测试 (GPQA) 中超越了博士生水平的准确性。
API 中目前有两种推理模型:
o1-preview:o1 模型的早期预览版,擅长利用广泛的世界知识来解决复杂问题。o1-mini:o1 的更快且成本更低的版本,尤其适合处理不依赖广泛知识的编程、数学和科学任务。
虽然 o1 模型在推理能力上取得了重大进展,但并不打算在所有应用场景中取代 GPT-4o。
对于需要图像输入、函数调用或快速响应的应用,GPT-4o 和 GPT-4o mini 模型仍然是更合适的选择。不过,如果你正在开发的应用需要深度推理且可以接受较长的响应时间,那么 o1 模型可能是一个理想的选择。我们很期待看到你用这些模型创造出什么!
🧪 o1 模型目前处于测试阶段
目前,o1 模型正处于测试版阶段,功能有所限制。仅限五级开发者访问(在此处查看你的使用等级),并且速率限制较低(20 RPM)。我们正在努力增加更多功能、提高速率限制,并计划在未来几周内向更多开发者开放!
快速入门
o1-preview 和 o1-mini 模型可以通过聊天完成端点访问。
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="o1-preview",
messages=[
{
"role": "user",
"content": "Write a bash script that takes a matrix represented as a string with format '[1,2],[3,4],[5,6]' and prints the transpose in the same format."
}
]
)
print(response.choices[0].message.content)
根据模型解决问题所需的推理复杂度,响应时间可能从几秒到几分钟不等。
在测试阶段,部分聊天完成 API 参数尚不可用。特别是:
- 模态:仅支持文本输入,暂不支持图像。
- 消息类型:仅支持用户和助手消息,不支持系统消息。
- 流式传输:暂不支持。
- 工具:不支持工具、函数调用及响应格式设置。
- Logprobs:不支持。
- 其他:
temperature、top_p和n固定为1,presence_penalty和frequency_penalty固定为0。 - 助手和批量 API:这些模型暂不支持助手 API 或批量 API。
我们计划在测试版结束后逐步增加对这些参数的支持。未来的 o1 系列模型将支持多模态功能及工具调用。
推理工作原理
o1 模型引入了推理 Token的概念。这些模型通过生成推理 Token 来“思考”,分析提示并评估多种生成响应的方案。在生成推理 Token 后,模型会生成可见的完成 Token,并将推理 Token 从上下文中移除。
以下是用户和助手之间的一个多步对话示例。每个步骤的输入和输出 Token 会被保留,但推理 Token 会被丢弃。
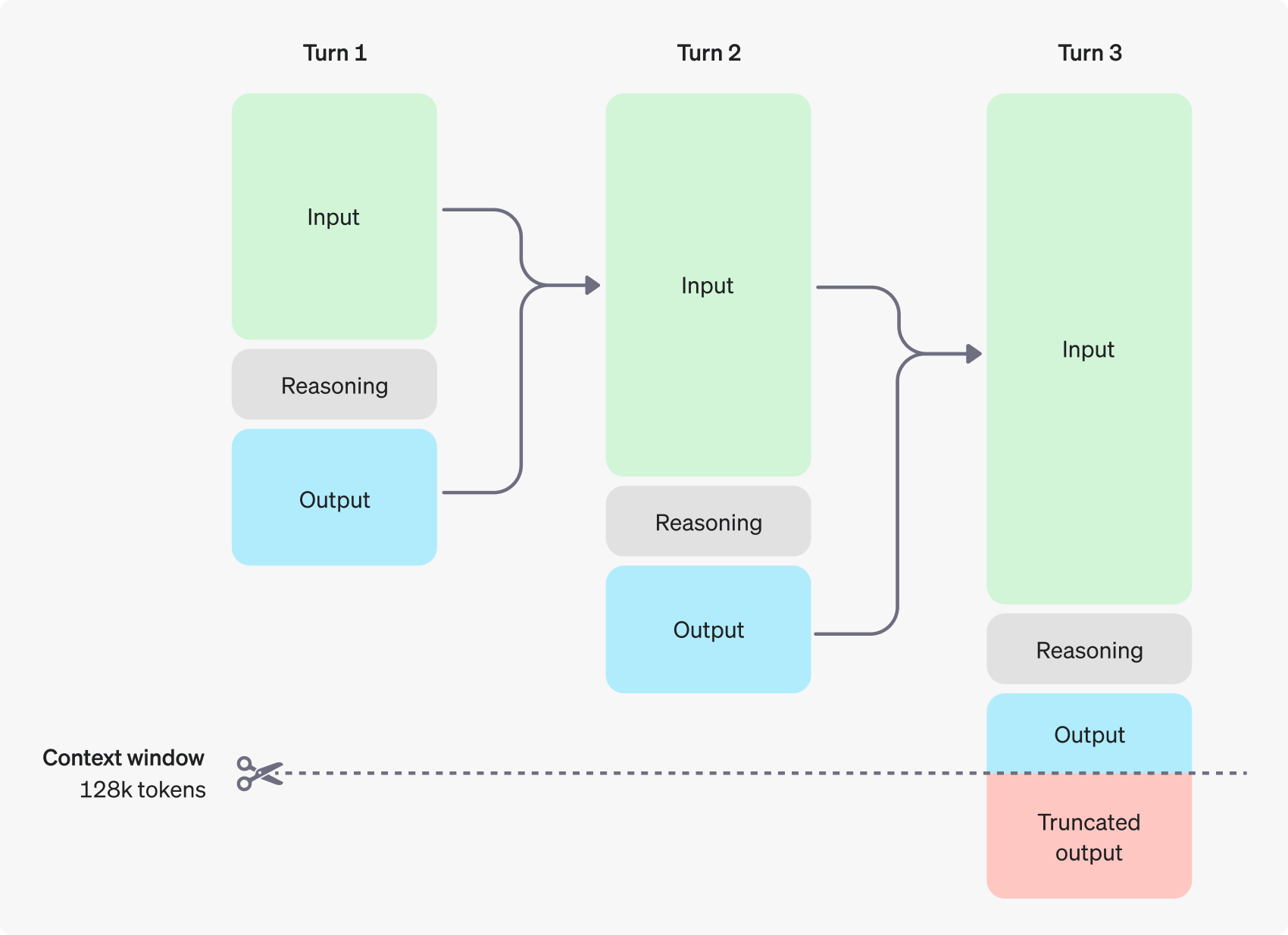
尽管推理 Token 不会在 API 输出中显示,但它们仍然占用上下文,并按输出 Token计费。
管理上下文
o1-preview 和 o1-mini 模型支持 128,000 个 Token 的上下文窗口。每次完成请求的最大输出 Token 数包括不可见的推理 Token 和可见的完成 Token。最大输出 Token 数限制如下:
- o1-preview:最多 32,768 个 Token
- o1-mini:最多 65,536 个 Token
创建完成请求时,请确保为推理 Token 保留足够的上下文空间。根据问题的复杂度,模型可能会生成从几百到数万个推理 Token。你可以在聊天完成响应对象的使用部分中查看具体使用了多少推理 Token。
usage: {
total_tokens: 1000,
prompt_tokens: 400,
completion_tokens: 600,
completion_tokens_details: {
reasoning_tokens: 500
}
}
要控制 o1 系列模型的使用成本,你可以通过max_completion_tokens参数限制模型生成的 Token 总数(包括推理和完成 Token)。
在早期模型中,max_tokens 参数同时控制生成和可见 Token 的数量,二者是相等的。然而在 o1 系列中,生成的 Token 总数可能会因为内部推理 Token 的存在而超过可见 Token 的数量。
由于某些应用可能依赖于 max_tokens 与收到的 Token 数量相匹配,o1 系列引入了max_completion_tokens 参数,明确控制生成的总 Token 数,包括推理和完成 Token。这一改变确保了现有应用不会因为使用新模型而出现问题。对于早期模型,max_tokens 参数依旧按照之前的方式工作。
为推理预留空间
如果生成的 Token 超过了上下文窗口的限制或你设置的 max_completion_tokens 值,系统将返回一个finish_reason 为 length 的完成响应。这种情况可能发生在生成任何可见完成 Token 之前,意味着你可能会为输入和推理 Token 付费,但未能获得可见的响应。
为避免这种情况,请确保预留足够的上下文空间,或者将max_completion_tokens设置为更大的值。OpenAI 建议在初次使用时,预留至少 25,000 个 Token 给推理和输出。随着你逐渐了解所需的推理 Token 数量,可以相应调整这个缓冲区。
提示技巧
这些模型在简单直接的提示下表现最佳。一些提示工程技术,如少样本提示或要求模型“逐步思考”,可能不会提升性能,甚至有时会削弱其效果。以下是一些提示使用的最佳实践:
- 保持提示简单明了:这些模型擅长处理简短、清晰的指令,无需过多的引导。
- 避免连贯思维提示:由于模型在内部完成推理,提示它“逐步思考”或“解释推理过程”是多余的。
- 使用分隔符增加清晰度:通过使用三引号、XML 标签或章节标题等分隔符来明确区分输入的不同部分,帮助模型正确理解每个部分。
- 限制检索增强生成 (RAG) 的额外上下文:在使用额外的上下文或文档时,只提供最相关的信息,以避免模型过度复杂化其响应。
提示示例
编码(重构)
OpenAI o1 系列模型能够实现复杂的算法并生成代码。以下是一个请求 o1 基于特定标准重构 React 组件的提示。
from openai import OpenAI
client = OpenAI()
prompt = """
Instructions:
- Given the React component below, change it so that nonfiction books have red
text.
- Return only the code in your reply
- Do not include any additional formatting, such as markdown code blocks
- For formatting, use four space tabs, and do not allow any lines of code to
exceed 80 columns
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
"""
response = client.chat.completions.create(
model="o1-mini",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
},
],
}
]
)
print(response.choices[0].message.content)
编码(planning)
OpenAI o1 系列模型也擅长创建多步计划。这个示例提示要求 o1 创建一个完整的解决方案的文件系统结构,以及实现目标用例的 Python 代码。
from openai import OpenAI
client = OpenAI()
prompt = """
I want to build a Python app that takes user questions and looks them up in a
database where they are mapped to answers. If there ia close match, it retrieves
the matched answer. If there isn't, it asks the user to provide an answer and
stores the question/answer pair in the database. Make a plan for the directory
structure you'll need, then return each file in full. Only supply your reasoning
at the beginning and end, not throughout the code.
"""
response = client.chat.completions.create(
model="o1-preview",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
},
],
}
]
)
print(response.choices[0].message.content)
STEM Reasearch
OpenAI o1 系列模型在 STEM(科学、技术、工程和数学)研究中表现优异。要求支持基础研究任务的需求应能表现出优异的结果。
from openai import OpenAI
client = OpenAI()
prompt = """
What are three compounds we should consider investigating to advance research
into new antibiotics? Why should we consider them?
"""
response = client.chat.completions.create(
model="o1-preview",
messages=[
{
"role": "user",
"content": prompt
}
]
)
print(response.choices[0].message.content)
使用案例示例
一些使用 o1 模型的实际案例可以在文档库中找到。