字节今天发布了最新多模态模型:Seed1.5-VL 的技术报告,该模型是个闭源模型,对应火山引擎上的 模型ID 为:doubao-1-5-thinking-vision-pro-250428(默认开启思考模式,可以自定义是否开启思考模式,打开的参数为:“thinking”:{“type”:“enabled”},关闭的参数为:“thinking”:{“type”:“disabled”})。这个模型在五一假期前就在火山引擎上上线了,我第一时间做了一些评测,实际能力确实如报告里的指标数据展示的那样,可以和 o4-mini-high 和 gemini 2.5 pro 掰掰手腕,同时也支持了目标位置定位这种检测任务,据我了解在全球通用大模型里只有 gemini 和 doubao 这两家的视觉模型支持视觉定位,包括 gemini 2.5 pro、gemini 2.5 flash 以及 doubao-1.5-vision-pro、doubao-1.5-thinking-vision-pro。
先快速看下这个模型的亮点
- 5.32 亿参数的视觉编码器,20B 活跃参数的 MoE
- 在 60 个公开 VLM 基准测试中有 38 个取得了 SOTA 结果,已应用于教育、医疗、聊天机器人和可穿戴设备等。
- 在各种能力上表现出色,包括复杂推理(像 Rebus 这样的视觉谜题)、OCR、图表理解、视觉定位、三维空间理解以及视频理解。
- 在交互式智能体任务中展现出领先表现,尤其在 GUI 控制和游戏表现方面体现出强大能力。
一些细节
架构 (Architecture)
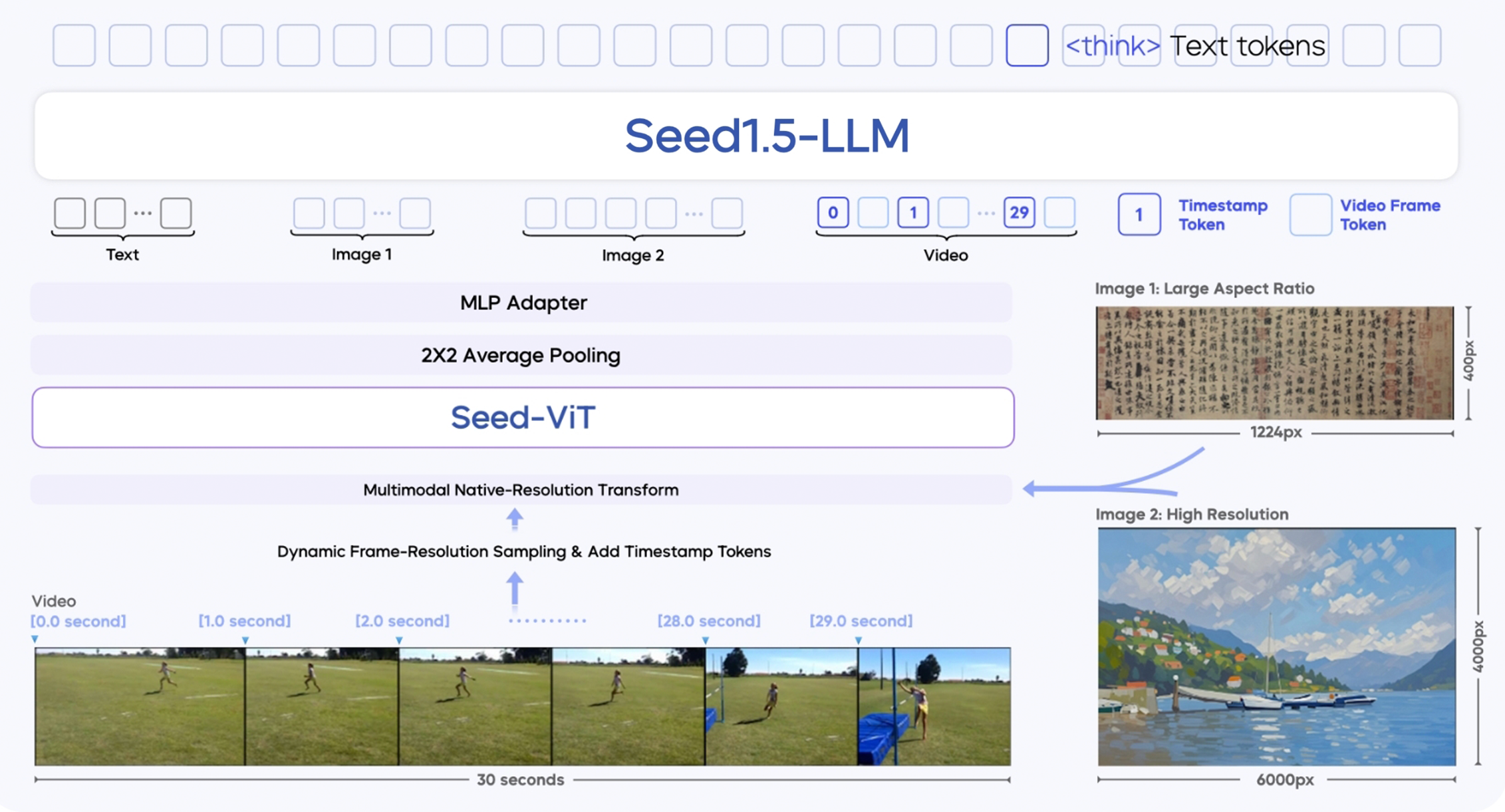
- 主要包含三个组件:
- SeedViT: 用于编码图像和视频的视觉编码器。这是一个基于 Vision Transformer (ViT) 架构的模型,拥有 5.32 亿参数。
- MLP Adapter: 将视觉特征投影到多模态 tokens。
- LLM: 用于处理多模态输入。
- 原生分辨率处理: Seed1.5-VL 设计用于处理各种分辨率的图像,通过原生分辨率转换来保留最大的图像细节。
- 视频处理: 采用动态帧分辨率采样策略,动态调整采样帧率和分辨率,并在每个帧前添加时间戳 token 以增强时间感知能力。每个视频的最大 token 预算为 81,920,提供六个预定义的分辨率级别 {640, 512, 384, 256, 160, 128} 来平衡时间和空间采样。
预训练 (Pre-training)
模型在 3 万亿多模态 token 上进行预训练,数据涵盖通用图像-文本对、知识数据、 OCR 数据(超过 10 亿样本)、视觉 Grounding 和 Counting 数据( 2 亿自动标注样本、 1.7 亿点数据指令、 800 万计数样本)、 3D 空间理解数据(相对深度、绝对深度、 3D Grounding )、视频数据、 STEM 数据(超过 100 万问题)和 GUI 数据。具体如下:
- 通用图像-文本对和知识数据: 用于基础的视觉-语言对齐。
- 光学字符识别 (OCR): 包含了大量文本图像对,旨在增强模型识别和理解图像中文本的能力。在训练中,OCR 和 GUI 相关数据使用了相对坐标和归一化处理,使其输出预测独立于输入图像分辨率。
- 视觉定位和计数: 通过边界框和点数据构建了约 800 万样本的数据集,以训练模型的定位和计数能力。
- 3D空间理解: 利用公开数据集训练模型的绝对深度估计和 3D 定位能力。绝对深度估计数据集包含 1800 万指令对,3D 定位数据集包含 77 万问答对。
- 视频数据: 用于训练模型的视频理解能力。
- 科学、技术、工程和数学 (STEM): 包含带有图像的 STEM 问题,特别是数学问题,用于提升模型在科学领域的推理能力。
- 图形用户界面 (GUI): 用于训练模型理解和与图形用户界面交互的能力。
预训练分为三个阶段:
- 阶段 1: 对齐视觉编码器与 LLM (仅训练 MLP 适配器)
- 阶段 2: 使所有参数可训练并积累知识( 3 万亿 token )
- 阶段 3: 平衡数据混合并增加新领域数据(如视频、 3D ),同时将序列长度扩展到 131,072
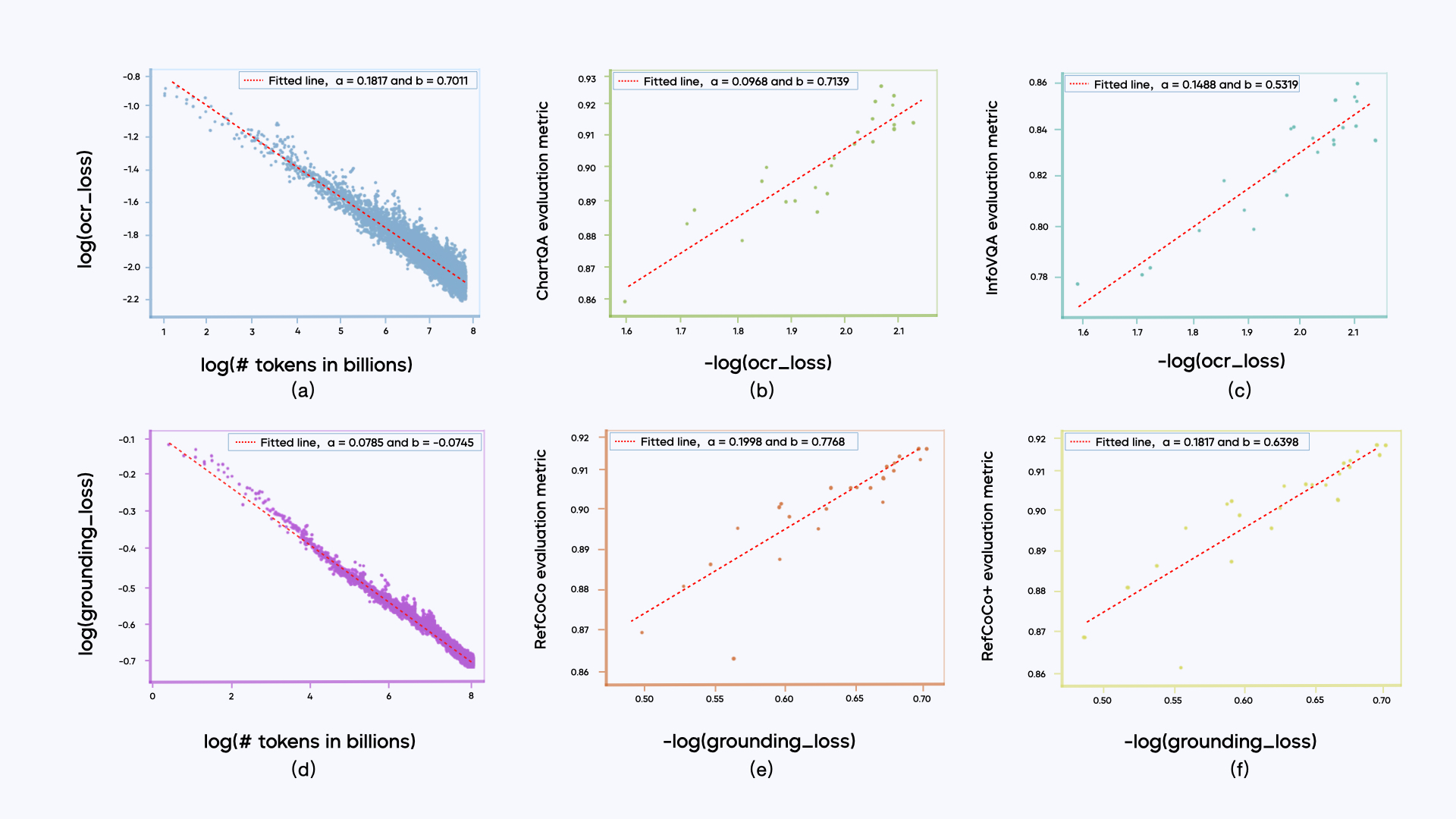
另外还有个发现:大多数子类别数据的训练损失与训练 token 的数量服从幂律关系,也就是所谓的 Scaling Laws 规律。子类别的训练损失与其对应的下游评估指标呈对数线性关系 (metric ∼ log(loss))。
后训练 (Post-training)
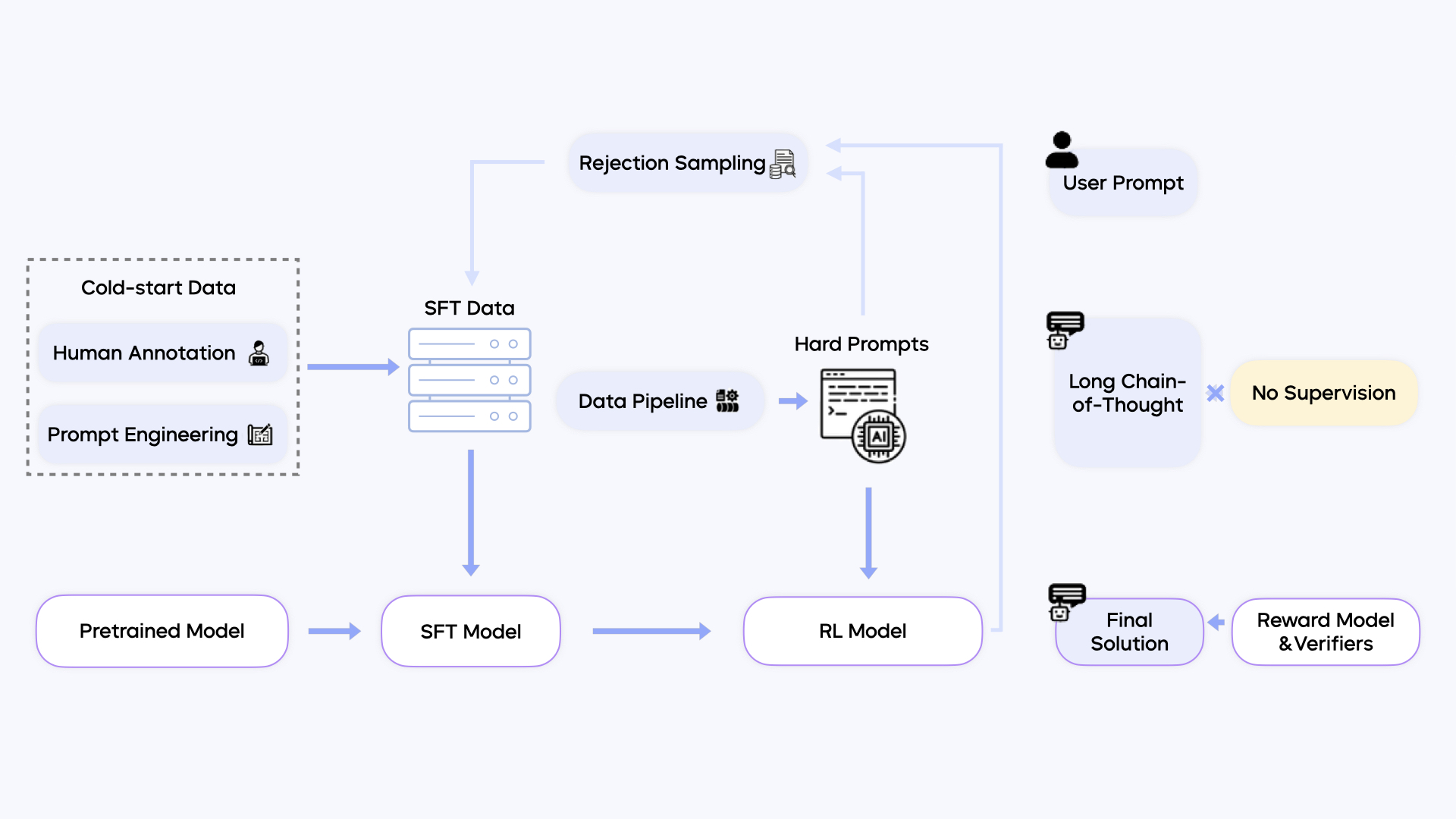
后训练阶段通过 Supervised Fine-tuning ( SFT ) 和 Reinforcement Learning ( RL ) 增强模型能力。
- SFT 使用约 5 万高质量多模态样本及 Long Chain-of-Thought ( LongCoT ) 数据。 RL 采用混合框架,结合人类反馈 ( RLHF ) 和可验证奖励 ( RLVR )。
- RLHF 使用生成式 Reward Model , RLVR 应用于 STEM 、视觉谜题等任务,通过规则或外部执行器验证结果。
- 训练基础设施支持大规模预训练(消耗 130 万 H800 GPU 小时)和后训练( RL 阶段 6 万 GPU 小时, RM 训练 2.4 万 GPU 小时),采用混合并行、工作负载平衡、并行感知数据加载和容错机制。
这里也说明一下大概的预训练和后训练的时间消耗(假设 GPU 利用率为 100%):
- 预训练 130 万 H800 GPU 小时:如果有 1000 块 H800,大概需要 54 天;如果有 10000 块 H800,大概需要 5.4 天;
- RL 阶段 6 万 GPU 小时:如果有 1000 块 H800,大概需要 2.5 天;
- RM 训练 2.4 万 GPU 小时:如果有 1000 块 H800,大概需要 1 天。
评估 (Evaluation)
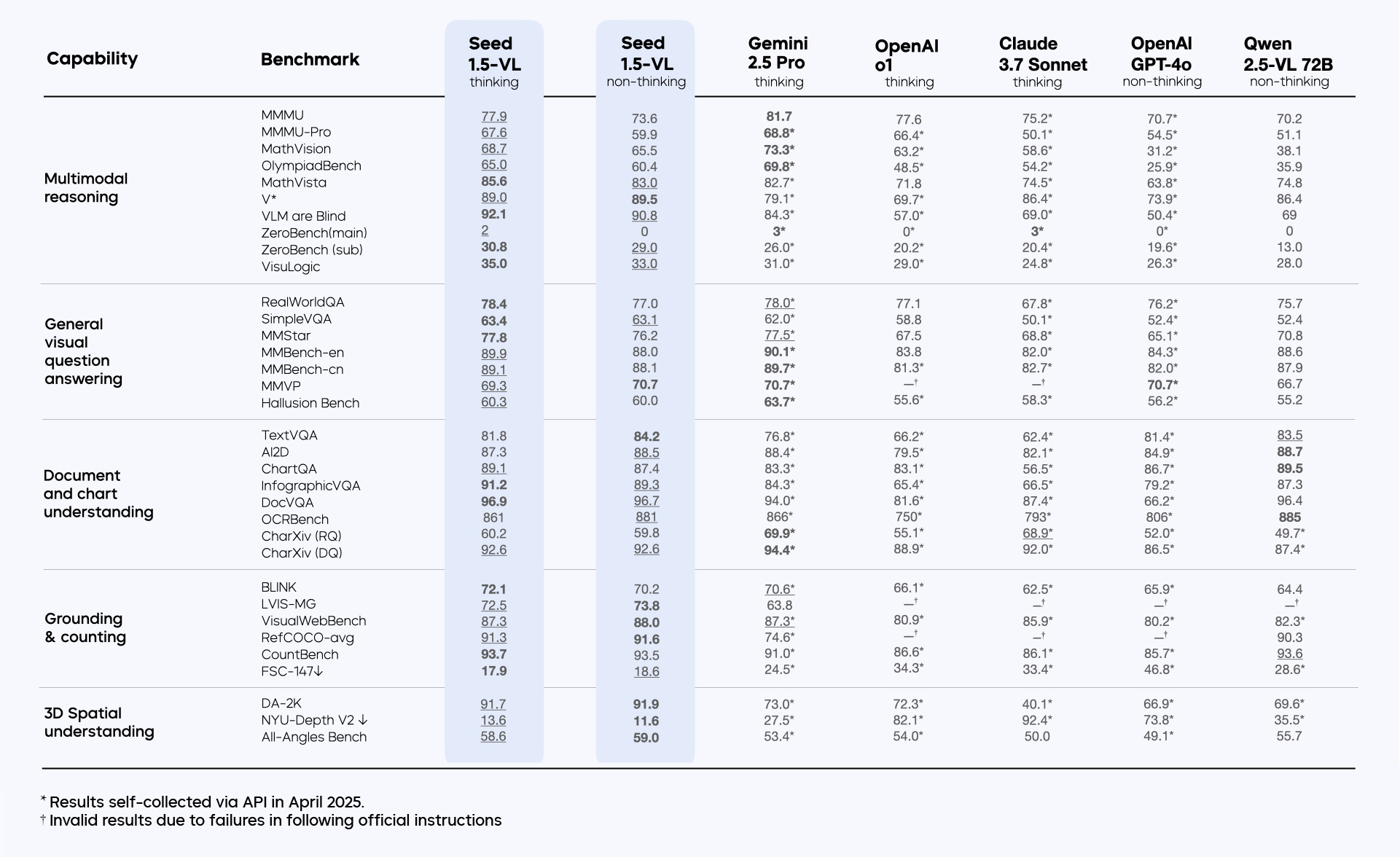
Seed1.5-VL 在多项公共基准上达到 SOTA ,包括 MathVista 、 VLM are Blind 、 TextVQA 、 DocVQA 、 InfographicVQA 、所有 Grounding 和 Counting 基准、 DA-2K 、 NYU-Depth V2 、所有 Streaming Video 基准等。
在 GUI Agent 任务中,其性能显著优于其他基础 VLM 。在 14 个 Poki 游戏中的表现也优于现有模型。
内部基准测试显示, Seed1.5-VL 在 OOD 、 Agent 、 Atomic Instruction Following 等类别中表现出色,整体排名第二。
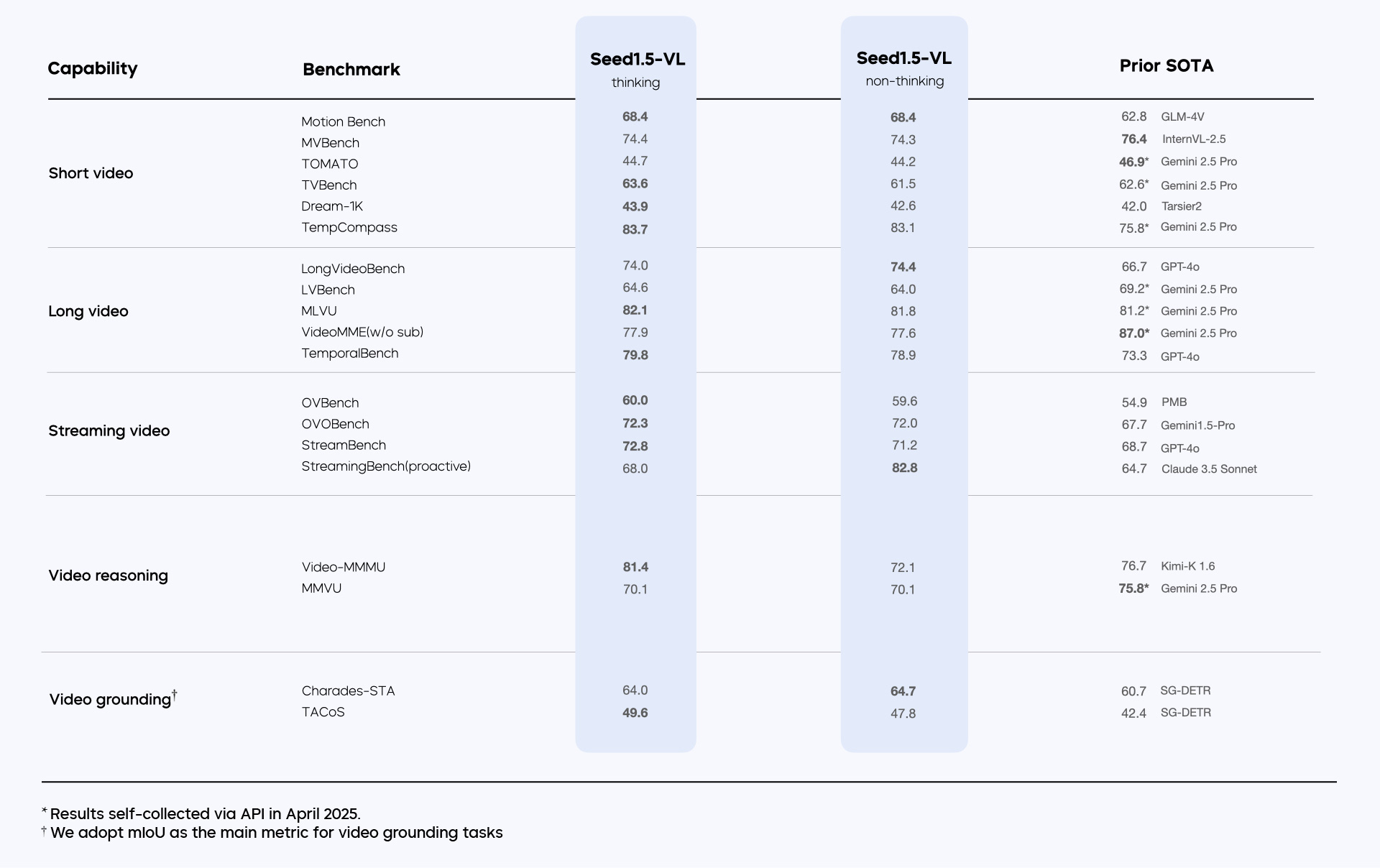
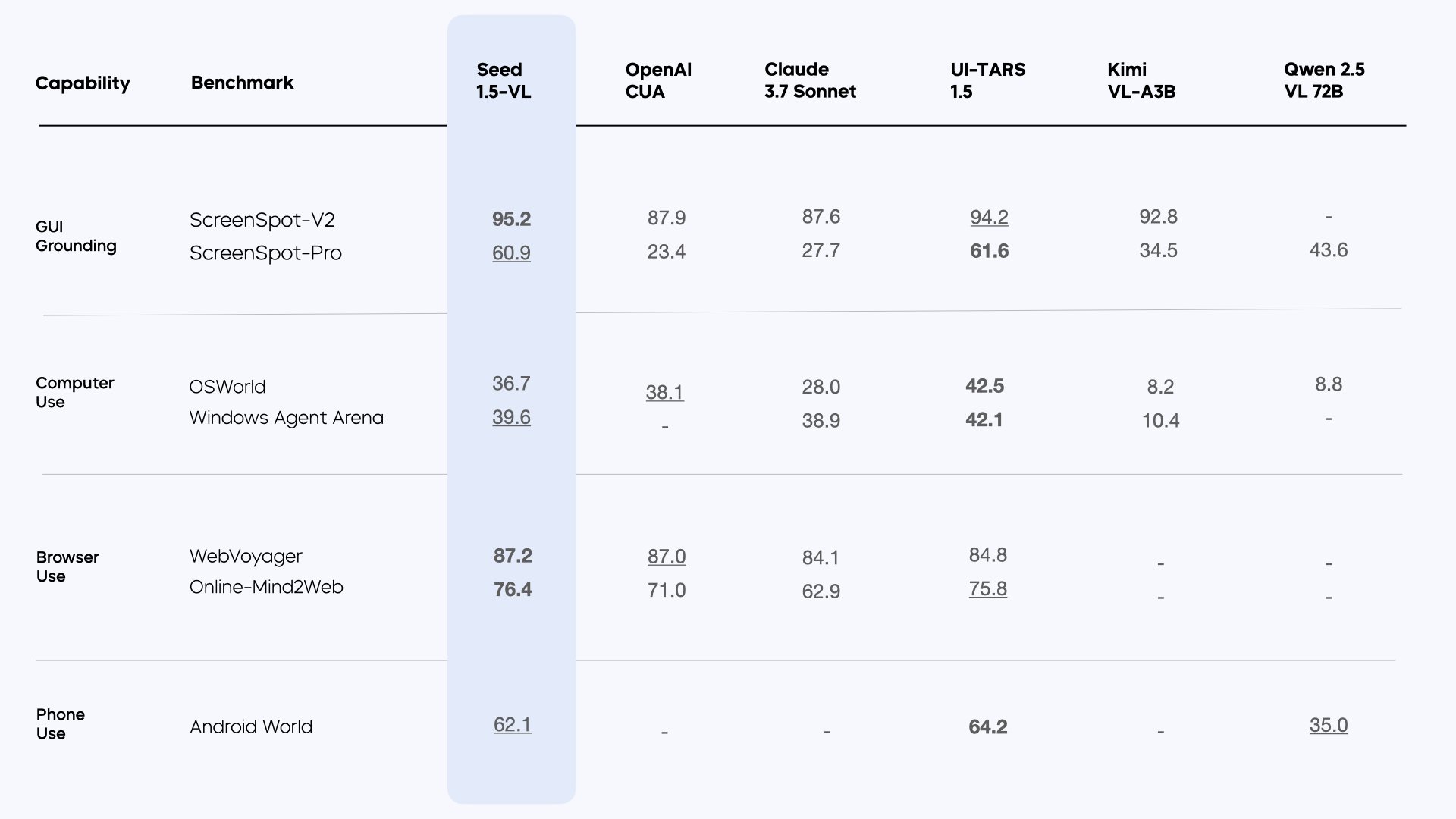
最后
报告的附录中提供了定性示例,展示了 Seed1.5-VL 在视觉推理、几何问题解决、复杂场景计数、深度排序、视频时间定位、OCR解析、多语言文档理解、图表代码生成、图像创意写作等方面的能力,感兴趣的话也可以去看看。
这个模型目前还存在一些局限性,包括在细粒度视觉感知(复杂场景计数、识别细微差异)、复杂推理(谜题、迷宫、组合搜索)、 3D 空间推理、时间推理、多图像推理以及幻觉(知识先验可能覆盖视觉信息)等方面。
另外,未来的工作上,会探索扩大模型规模、结合图像生成能力(实现视觉 Chain-of-Thought )和集成工具使用等方向,这是 OpenAI o3 和 o4-mini 都已经实现的能力,字节还得加油追赶啊,距离 OpenAI 的模型至少还有半年的差距。