鉴于 Sora 的官方文献尚未发布,本文的目标是寻找 OpenAI 发布的 Sora 技术报告中的线索。原文来戳这里。
Sora 是什么
Sora 以其从自然语言提示中生成高清视频的能力,在生成式 AI 领域引起了巨大轰动。如果你还没见过相关示例,这儿有一个生成的视频供你欣赏——视频展示了一只海龟在珊瑚礁中游泳的场景。
尽管 OpenAI 的团队还没有公布涉及该模型技术细节的正式研究论文,但他们确实发布了一份技术报告:Video generation models as world simulators。这份报告概述了他们应用的一些高级技术和一些定性的研究成果。
Sora 架构概述
在读过下列论文之后,你会开始理解这里所述的架构。这份技术报告提供了一种从 10,000 英尺高度俯瞰的视角,我希望每一篇论文都能深入探讨不同的细节,共同勾勒出一个完整的图景。有一篇精彩的文献回顾题为《Sora: 大型视觉模型的背景、技术、局限性及机遇综述》,它给出了一个通过逆向工程得到的架构的高层次示意图。
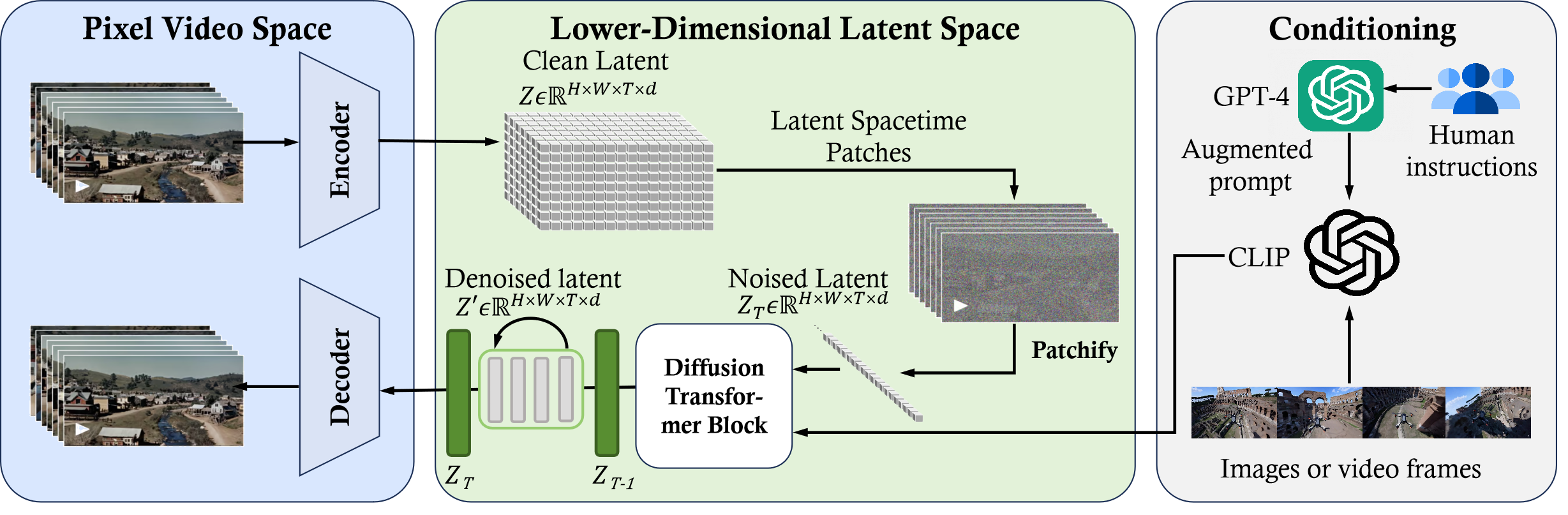 图 4:逆向工程:Sora 框架概述
图 4:逆向工程:Sora 框架概述
OpenAI 的团队把 Sora 描述为“扩散 Transformer”,这个概念融合了之前论文中提到的多种思想,但特别是用于处理视频中生成的潜在时空区块。
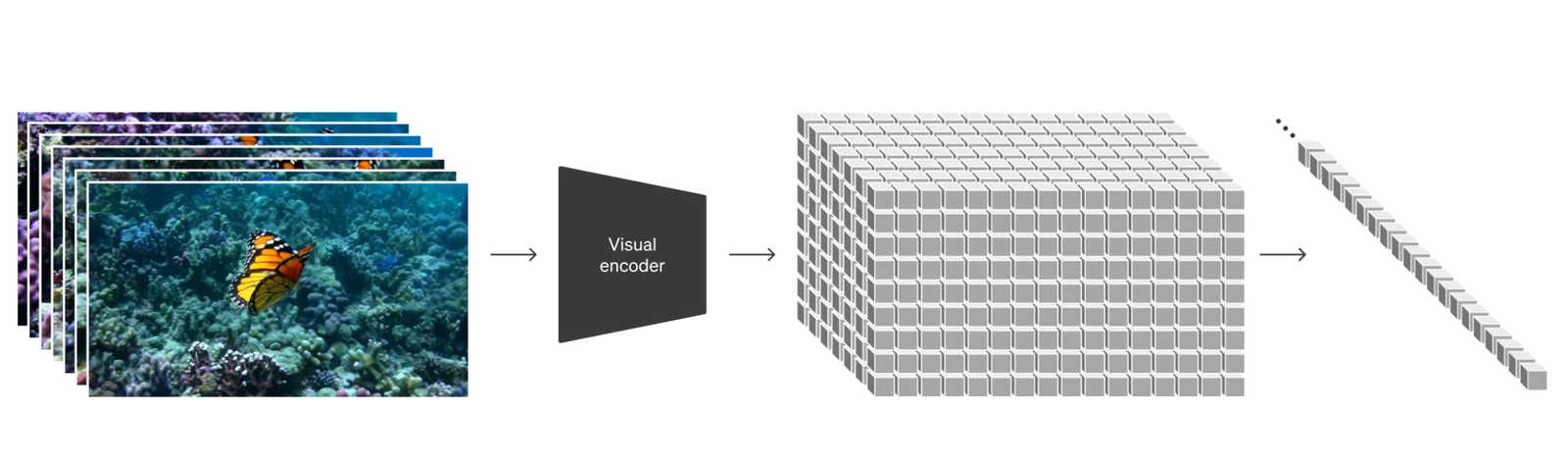
这种方法结合了 Vision Transformer (ViT) 论文中提到的补丁样式和 Latent Diffusion Paper 中相似的潜在空间概念,但采用了扩散 Transformer 的组合方式。这不仅包括图像的宽度和高度方向上的补丁,还拓展到了视频的时间维度。

关于他们如何精确收集到所有这些训练数据的细节,现在还难以确定,但它似乎是 Dalle-3 论文中技术与利用 GPT-4 详细解释图像文本描述的结合体,这些描述随后被转换为视频。训练数据可能是此处的核心秘密,因此技术报告中关于此的细节最为欠缺。
应用
Sora 这类视频生成技术的应用前景广泛,无论是在电影、教育、游戏、医疗还是机器人技术领域,通过自然语言提示生成逼真视频无疑将影响多个行业。
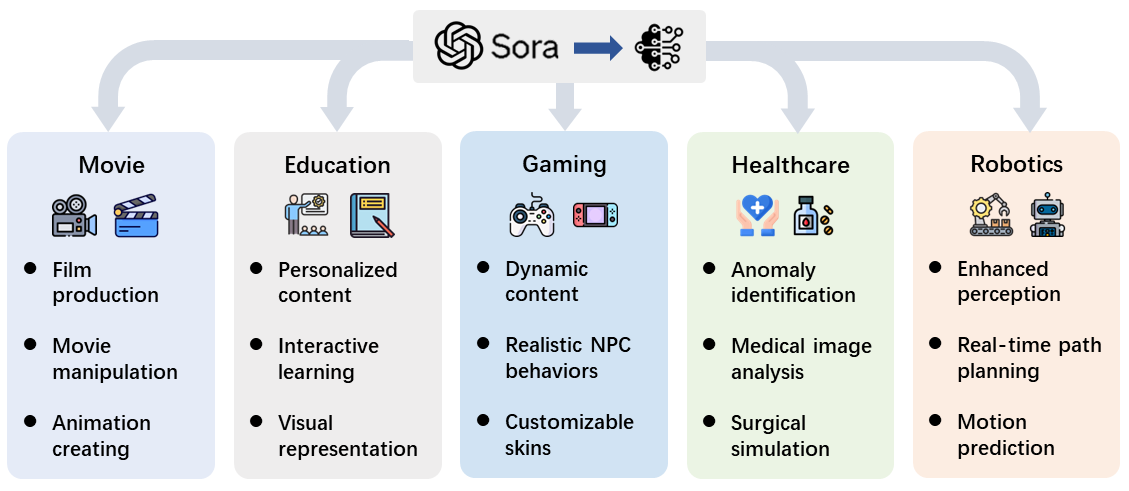 图 18:Sora 的应用
图 18:Sora 的应用
论文阅读清单
OpenAI 技术报告中的参考文献部分引用了众多论文,但确定哪些论文应该优先阅读或者对背景知识非常重要可能有些难度。我们已经仔细筛选并挑选出了我们认为最具影响力和最值得阅读的论文,并按类别进行了整理。
背景论文
从 2015 年开始,生成图像和视频的质量持续提升。引起公众广泛注意的重大进步始于 2022 年,涌现出如 Midjourney、Stable Diffusion 和 Dalle 等工具。本节包含了一些被反复引用的基础论文和模型架构。虽然这些论文不全部直接关联 Sora 架构,但它们为理解艺术和技术水平如何随时间演进提供了重要的背景。
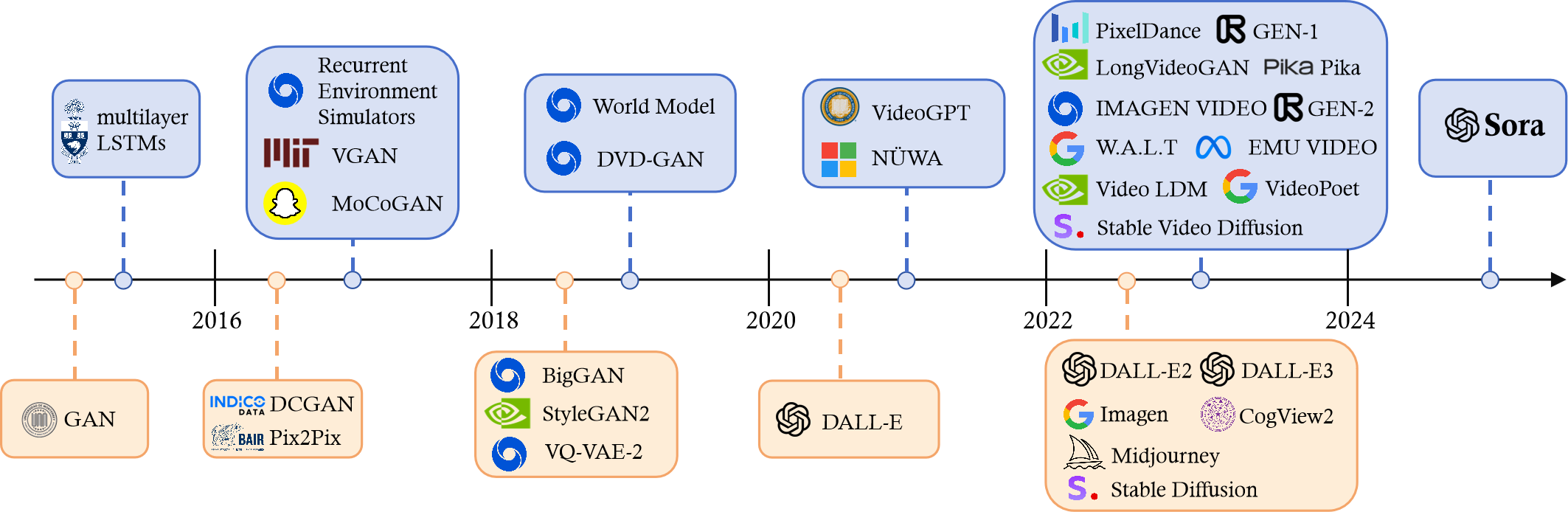 图 3: 视觉领域内生成式 AI 的发展历程。
图 3: 视觉领域内生成式 AI 的发展历程。
Source: https://fisherdaddy.com/posts/sora_ms
U-Net
《U-Net: 生物医学图像分割的卷积网络》是一个极好的例子,展示了最初用于生物医学成像领域任务的论文如何被应用到许多不同的场景中。其中最值得注意的是它成为了如 Stable Diffusion 这样的许多扩散模型的基础,助力于学习如何在每一步预测和减少噪声。虽然 U-Net 没有直接用于 Sora 架构,但它为了解先前的技术水平提供了重要的背景知识。
Source: https://arxiv.org/abs/1505.04597
Language Transformers
《Attention Is All You Need》是一篇在机器翻译任务上证明其价值的论文,但最终成为自然语言处理研究领域的一篇开创性论文。如今,Transformer 成为了许多大语言模型应用的核心,例如 ChatGPT。Transformer 被扩展应用到多种模式中,并作为 Sora 架构的一部分使用。
Source: https://fisherdaddy.com/posts/transformer
Vision Transformer (ViT)
《一张图像价值 16x16 词:大规模图像识别的 Transformer》是首批将 Transformer 应用于图像识别的论文之一,证明了如果在足够大的数据集上训练,它们能够胜过 ResNets 和其他卷积神经网络。这篇论文将《Attention Is All You Need》中的架构适配到计算机视觉任务中。与其使用文本 token 作为输入,ViT 采用 16x16 的图像补丁。
Source: https://arxiv.org/abs/2010.11929
Latent Diffusion Models
《高分辨率图像合成与潜在扩散模型》技术是 Stable Diffusion 等众多图像生成模型背后的科技核心。该技术通过将图像生成过程转化为一系列从潜在表征中进行去噪的自编码器,实现了图像的合成。其中,U-Net 架构被用作生成过程的骨架。这些模型能够基于任何文本输入,生成近乎真实的图像。
Source: https://arxiv.org/abs/2112.10752
CLIP
《通过自然语言监督学习可迁移的视觉模型》通常被称作对比语言-图像预训练(CLIP),这是一种能够将文本数据和图像数据嵌入至同一潜在空间的技术。这项技术通过确保文本与图像对之间的余弦相似度较高,来加强生成模型的语言理解与视觉理解之间的联系。
Source: https://arxiv.org/abs/2103.00020
VQ-VAE
技术报告指出,通过使用向量量化变分自编码器(VQ-VAE),他们减少了原始视频的维数。研究显示,变分自编码器是一种强大的无监督预训练方法,能有效学习潜在表征。
Source: https://arxiv.org/abs/1711.00937
Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
Sora 技术报告讲述了如何处理任意长宽比的视频,并因此能够使用更广泛的数据集进行训练。不需要对数据进行裁剪就能提供给模型的数据越多,获得的结果越好。这篇论文虽然聚焦于图像,但 Sora 将其方法扩展至视频处理。
Source: https://arxiv.org/abs/2307.06304
Diffusion Transformer (DiT)
OpenAI 的团队介绍了 Sora,称其为“扩散 Transformer”,结合了上述多篇论文中列出的多个概念。DiT 技术在潜在扩散模型中,用操作潜在补丁的 Transformer 替换了 U-Net 架构。通过使用比 U-Net 更高效的模型,这篇论文实现了生成高质量图像的最新技术,从而可以用更多的数据和计算资源来训练这些模型。
Source: https://arxiv.org/abs/2212.09748
视频生成论文
以下论文为 Sora 的视频生成灵感来源,它们将上述的生成模型技术提升到了新的层次,将其应用到视频生成中。
ViViT: A Video Vision Transformer
本文详细探讨了如何将视频切分为视频任务所需的“时空 tokens”。虽然论文主要关注视频分类,但其提出的 tokenization 方法同样适用于视频生成。
Source: https://arxiv.org/abs/2103.15691
Imagen Video: High Definition Video Generation with Diffusion Models
Imagen 采用了一种基于文本条件的视频生成系统,该系统基于一系列视频扩散模型。通过在时间方向上使用卷积和超分辨率技术,能从文本生成高质量视频。
Source: https://arxiv.org/abs/2210.02303
Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
该论文将图像生成中的潜在扩散模型引入时间维度,通过在时间维度上应用一些技巧来对齐潜在空间,尽管还未能完全达到 Sora 的时间连贯性。
Source: https://arxiv.org/abs/2304.08818
Photorealistic video generation with diffusion models
W.A.L.T 采用了基于 Transformer 的方法通过扩散模型生成逼真视频,这是参考列表中与 Sora 最接近的技术,由 Google、斯坦福大学和乔治亚理工学院的团队于 2023 年 12 月发布。
Source: https://arxiv.org/abs/2312.06662
Vision-Language Understanding
为了根据文本提示生成视频,他们需要收集大量视频数据集。人工标注这么多视频是不现实的,因此他们可能采用了 DALL·E 3 论文中描述的某些合成数据技术。
DALL·E 3
训练文本到视频生成系统需要大量带有文本说明的视频。他们将 DALL·E 3 中引入的重标注技术应用到视频上。与 DALL·E 3 类似,他们还利用 GPT 技术将用户简短的提示转换成更详细的说明,然后送往视频模型。
Source: https://openai.com/dall-e-3
Llava
为使模型能够遵循用户指令,他们可能进行了类似 Llava 论文中的指令细化调整。该论文还展示了一些创建大规模指令数据集的合成数据技巧,这在结合 Dalle 方法时可能尤其有用。
Source: https://arxiv.org/abs/2304.08485
Make-A-Video & Tune-A-Video
如 Make-A-Video 和 Tune-A-Video 所示,通过提示工程,利用模型的自然语言理解能力来解码复杂指令,并将其渲染成连贯、生动、高质量的视频叙述。例如,通过添加形容词和动词,将简单的用户提示扩展,以更全面地描述场景。
Source: https://arxiv.org/abs/2209.14792 https://arxiv.org/abs/2212.11565