本文翻译自 Llamaindex 官方发布的一篇文章:《Towards Long Context RAG》
Google 最近发布了 Gemini 1.5 Pro,带有 1M context window,仅向一小部分开发者和企业客户提供。它在由 Greg Kamradt 推广的“大海捞针”实验中实现了 99.7% 的召回率。这一成就引起了 Twitter 上的 AI 圈子的广泛关注。早期用户输入了大量研究论文和财务报告进行测试,并报告说其在整合海量信息方面表现出色。
这自然引发了一个问题:RAG 是否已经过时了?有人认为确实如此,而另一些人则持不同意见。认为 RAG 过时的一方提出了一些有力的论点,比如大多数小数据场景都可以适应 1 到 10M 的上下文窗口大小,而且随着时间的推移,处理 token 的成本和速度都会降低。通过注意力层直接在大语言模型(LLM)中融合检索和生成过程,与简单的 RAG 模型中单次检索相比,可以获得更高质量的响应。
我们有幸提前体验到 Gemini 1.5 Pro 的能力,并在此基础上发展了一套论点,关于 context-augmented LLM 应用的未来发展方向。本篇博客旨在明确我们作为数据框架的使命,以及我们对长上下文大语言模型架构未来形态的看法。我们认为,尽管长上下文的大语言模型会简化某些 RAG 处理流程(如数据分块),但为了应对新的使用场景,还需发展新的 RAG 架构。无论未来发展如何,LlamaIndex 的使命都是为构建未来的工具而努力。
我们的使命远不止于 RAG
LlamaIndex 的宗旨非常明确:赋能开发者在自己的数据上构建基于大语言模型的应用。这个目标远不止于 RAG。迄今为止,我们已经在推动现有大语言模型使用 RAG 技术方面投入了巨大的努力,这使得开发者能够开发出许多新的应用场景,例如在半结构化数据、复杂文档上进行问答(QA)以及在多文档环境中进行具有代理能力的推理。
对 Gemini Pro 的兴奋之情也同样激励着我们,未来我们将继续推动 LlamaIndex 作为一个面向长上下文大语言模型时代的数据框架向前发展。
**大语言模型框架本身极具价值。**作为一个开源的数据框架,LlamaIndex 为从原型到生产构建任何大语言模型应用场景提供了一条清晰的路径。与从头开始构建相比,使用框架能显著简化开发过程。我们使所有开发者都能够构建这些应用场景,无论是通过使用我们的核心抽象来搭建恰当的架构,还是利用我们生态系统中的众多集成。不论底层大语言模型技术如何进步,不论 RAG 是否继续以当前形式存在,我们会持续优化框架,确保其准备就绪,包括严密的抽象设计、一流的文档和一致性。
我们上周还推出了 LlamaCloud。LlamaCloud 的使命是构建数据基础设施,使任何企业能够让其庞大的非结构化、半结构化和结构化数据源为使用大语言模型做好准备。
Gemini 1.5 Pro 初步观察
在我们的初步测试中,我们尝试了一些 PDF 文件,如 SEC 10K 文件、ArXiv 论文、这个庞大的 Schematic Design Binder,等等。一旦 API 可用,我们将进行更深入的分析,但暂时,我们在下面分享了一些观察结果。
Gemini 的表现令人印象深刻,并且与技术报告及社交媒体上所见一致:
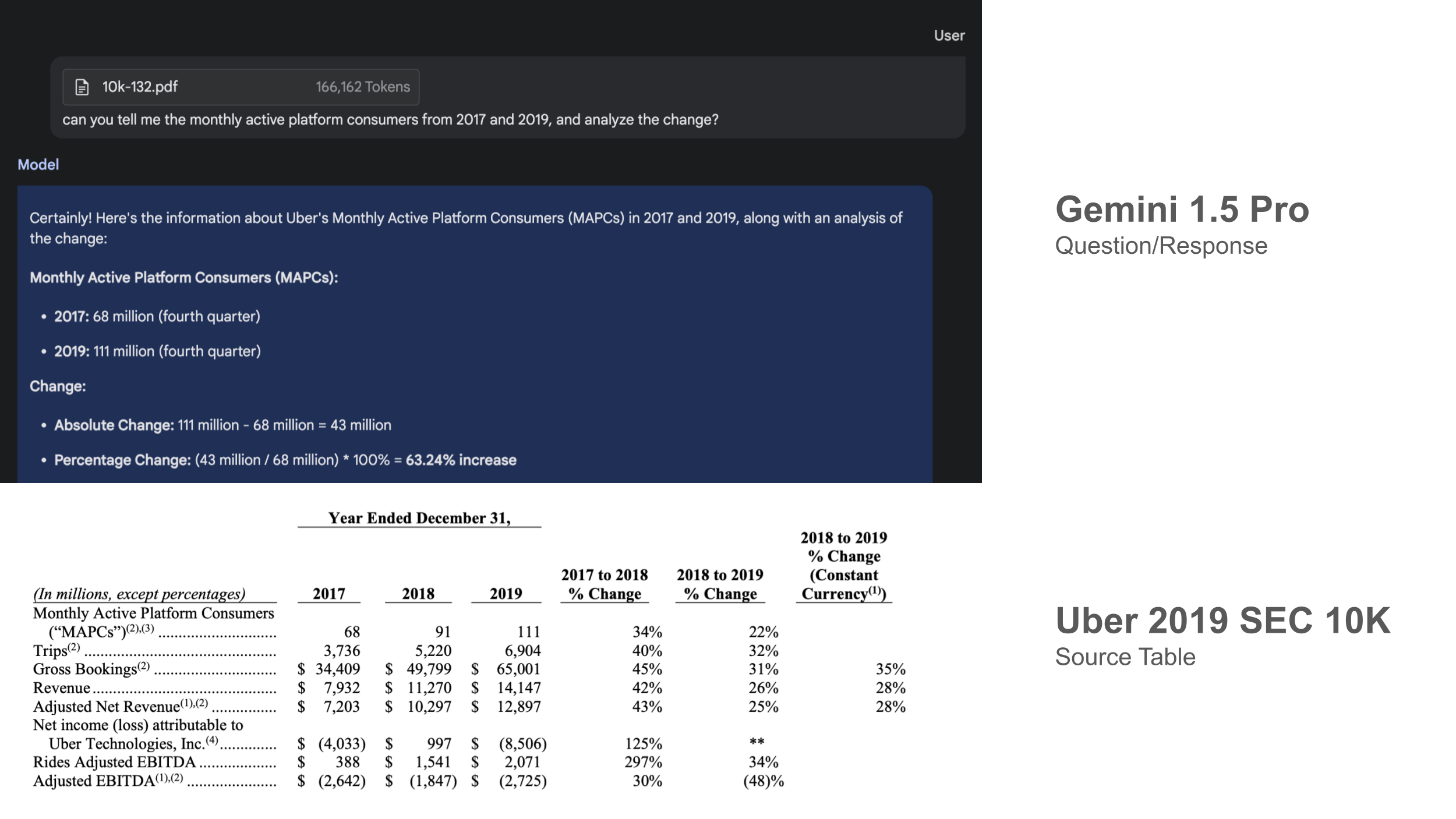
- Gemini 在回忆具体细节方面表现出色: 我们输入了 10万到100万 tokens 的上下文,对这些文档中非常具体的细节(无论是非结构化文本还是表格数据)提出了问题,在所有情况下 Gemini 都能准确回忆细节。如下图所示,对 2019 年 Uber 10K 报告的表格结果进行了比较。
- Gemini 在概括能力方面表现卓越。 模型能够分析多个文档中的大量信息,并综合出答案。
我们也注意到 Gemini 在某些方面存在挑战:
- Gemini 并不总能正确解读所有的表格和图表。 Gemini Pro 在读取图表和复杂表格方面仍然存在困难。
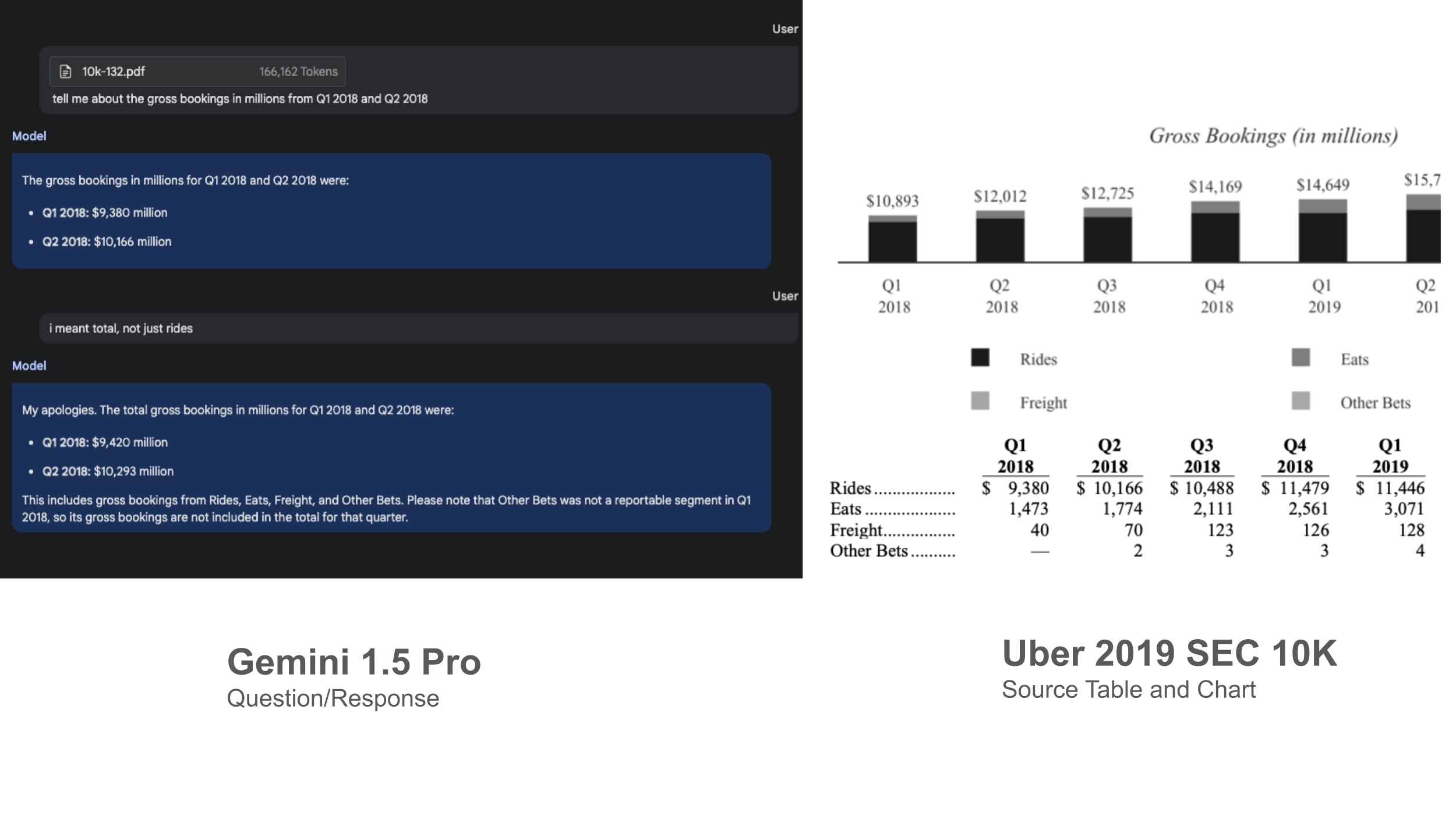
- Gemini 的响应时间可能较长。 对于 Uber 10K 文件(约160k tokens)的查询,返回答案需要约 20 秒。而对于 LHS Schematic Design Binder(约890k tokens)的查询,返回答案需要 60 秒以上。
- Gemini 有时会产生幻觉,如页码。 在被询问提供带页码引用的摘要时,Gemini 有时会错误地“幻觉”出来源。
从大方向来看,这是对未来的一个令人兴奋的预览,并引发了更广泛的讨论,即哪些 RAG 范式将逐渐消失以及将出现哪些新架构。详见下文!
长上下文解决了一些问题,但仍有挑战待解
Gemini 1.5 Pro 只是众多即将面世的长上下文大语言模型中的第一个,这无疑会改变用户构建 RAG 的方式。
我们相信长上下文大语言模型将解决一些现有 RAG 的痛点:
- 开发者不再需要过分关注如何精确调整分块算法。 我们认为这将极大地便利大语言模型的开发者。长上下文大语言模型允许更大的原生 chunk 大小。假设每个 token 的成本和响应时间也会降低,开发者就无需在如何通过调整分块分隔符、chunk 大小以及精心设计的元数据注入来分割它们的 chunks 上过度纠结。长上下文大语言模型允许处理整个文档或至少是几页文档的 chunks。
- 开发者将花费更少的时间调整单个文档的检索和思维过程。 对于小块 top-k RAG,虽然某些问题可以通过特定文档的特定片段得到回答,但其他问题需要在文档的不同部分之间或两个文档之间进行深入分析(例如比较查询)。对于这些场景,开发者不再需要依赖于思维过程代理来对弱检索器进行两次检索;相反,他们可以直接提示大语言模型来获得答案。
- 概括将变得更容易。 这与上述声明相关联。对大型文档进行概括的许多策略涉及到一些技巧,如序列细化或层次概括(参见我们的响应合成模块作为参考)。现在,这可以通过一次大语言模型调用来缓解。
- 构建个性化记忆将变得更简单且更有效: 构建对话助手时的一个关键挑战是如何将足够的对话上下文加载进提示窗口。对于非常基础的网络搜索代理,4k tokens 很容易就会超出这个窗口的容量 - 如果决定加载一个维基百科页面,那么文本将很容易就会超出上下文。1M-10M 的上下文窗口将使开发者更容易地实现对话记忆,减少压缩技巧(例如向量搜索或自动知识图谱构建)的需求。
尽管如此,仍有一些挑战待解:
- 10M tokens 对于大型文档库来说不够 - 千文档级的检索仍是一项挑战。 1M tokens 大约相当于7份 Uber SEC 10K 文件。10M tokens 大约相当于70份这样的文件。10M tokens 大约受到 40MB 数据量的限制。虽然这对许多“小”文档库来说足够了,但在企业中,许多知识库的数据量达到了GB甚至TB级别。为了在这些知识库上构建由大语言模型驱动的系统,开发者仍需找到某种方式来检索这些数据,以便与语言模型的上下文相结合。
- 嵌入模型在上下文长度方面落后。 到目前为止,我们看到的最大上下文窗口嵌入模型是 32k 来自 together.ai。这意味着,即使用于与长上下文大语言模型合成的 chunks 可以很大,任何用于检索的文本 chunks 仍需小得多。
- 成本和延迟。 的确,随着时间的推移,所有关于成本和延迟的问题都会逐渐缓解。然而,填充 1M 上下文窗口需要大约 60 秒,成本可能在 0.50 美元到 20 美元之间。Yao Fu 提出的一个解决方案是,通过一个 KV 缓存缓存文档激活,这样任何后续的生成都可以重用同一个缓存。这引出了我们接下来要讨论的一个点。
- 一个 KV 缓存占用大量 GPU 内存,并且有序依赖性。 我们与 Yao 讨论时,他提到,目前,缓存 1M tokens 的激活大约需要使用 100GB 的 GPU 内存,或者两个 H100 GPU。当底层语料库很大时,如何最佳地管理缓存也是一个有趣的挑战 - 由于每个激活都是之前所有 tokens 的函数,因此更换 KV 缓存中的任何文档都会影响该文档之后所有激活的计算。
迈向新 RAG 架构
长上下文大语言模型的正确利用将需要新的架构,以最大限度地发挥它们的潜力,同时解决它们所面临的挑战。以下是我们提出的一些建议:
1. 从小到大的文档检索
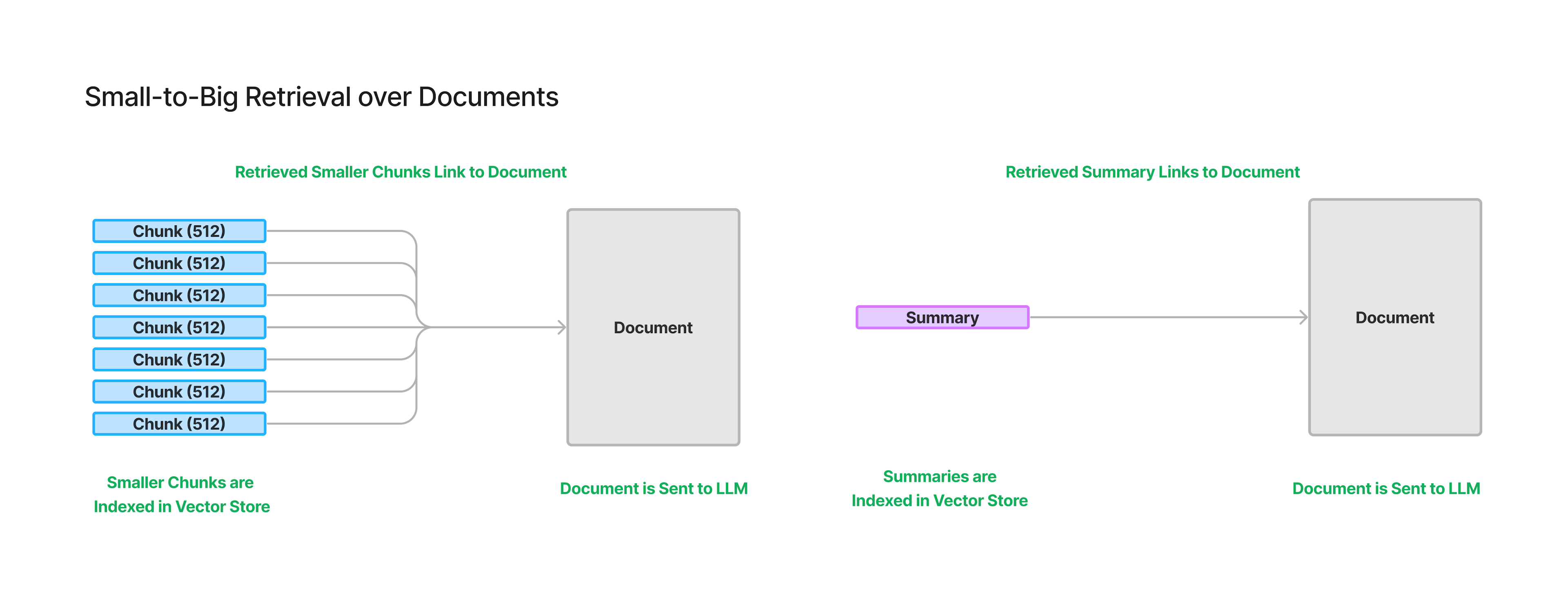
这种架构在 LlamaIndex 中已有不同形式的实现,如句子窗口检索器和递归检索器节点,但对于长上下文大语言模型,它可以进一步扩展——嵌入文档摘要并链接到完整文档。
我们希望嵌入并索引较小块的一个原因是当前的嵌入模型在上下文长度方面没有跟上大语言模型的进步。另一个原因是,相较于为整个文档生成单一嵌入,嵌入许多小块并将每个小块链接到一个大块,可以更有效地检索到相关信息。
上述图表展示了小到大检索的两种方式。一种是索引文档摘要并将其链接到文档,另一种是在文档内部索引更小的块并将它们链接到文档。当然,你也可以两者结合使用——提高检索效果的一个通用策略是同时尝试多种技术,并在后期将结果整合。
2. 针对延迟/成本权衡的智能路由
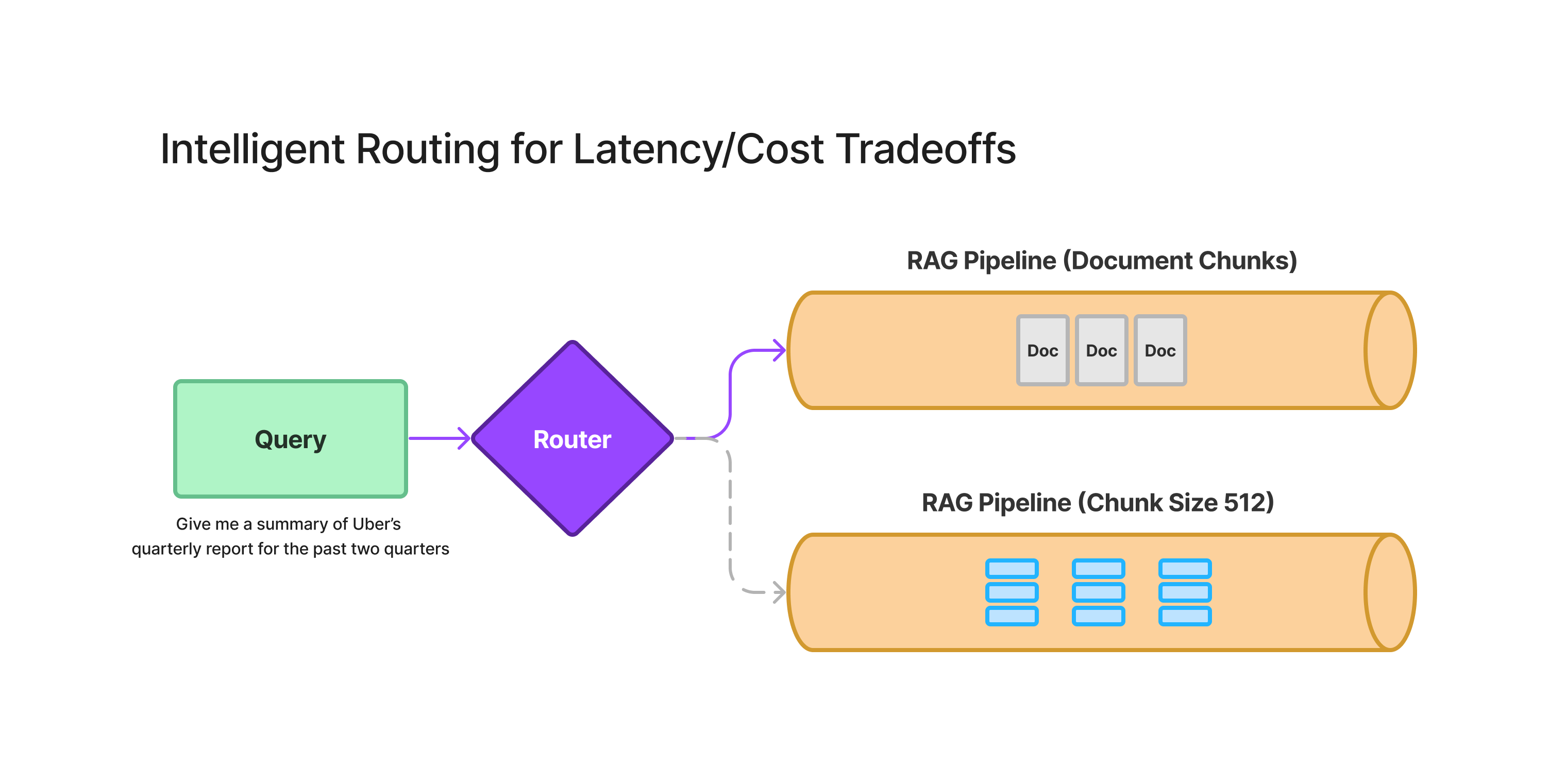
针对具体细节的查询非常适合使用现有的 RAG 技术进行 top-k 检索和合成。
更复杂的问题需要从不同文档的不同部分获取更多上下文,在这种情况下,正确回答这些问题的方法在于优化延迟和成本:
- 概要提取问题需要审查整个文档。
- 复杂问题可以通过执行思维链路和交错检索与推理来解决;它们也可以通过将所有上下文压入提示来解决。
我们设想了一个智能路由层,它可以基于多个 RAG 和大语言模型合成管道操作,根据知识库中的数据。给定一个问题,理想情况下,路由器能够选择最佳策略,从而在检索上下文以回答问题时优化成本和延迟。这确保了单一接口能够处理不同类型的问题,同时避免成本过高。
3. 检索增强的 KV 缓存
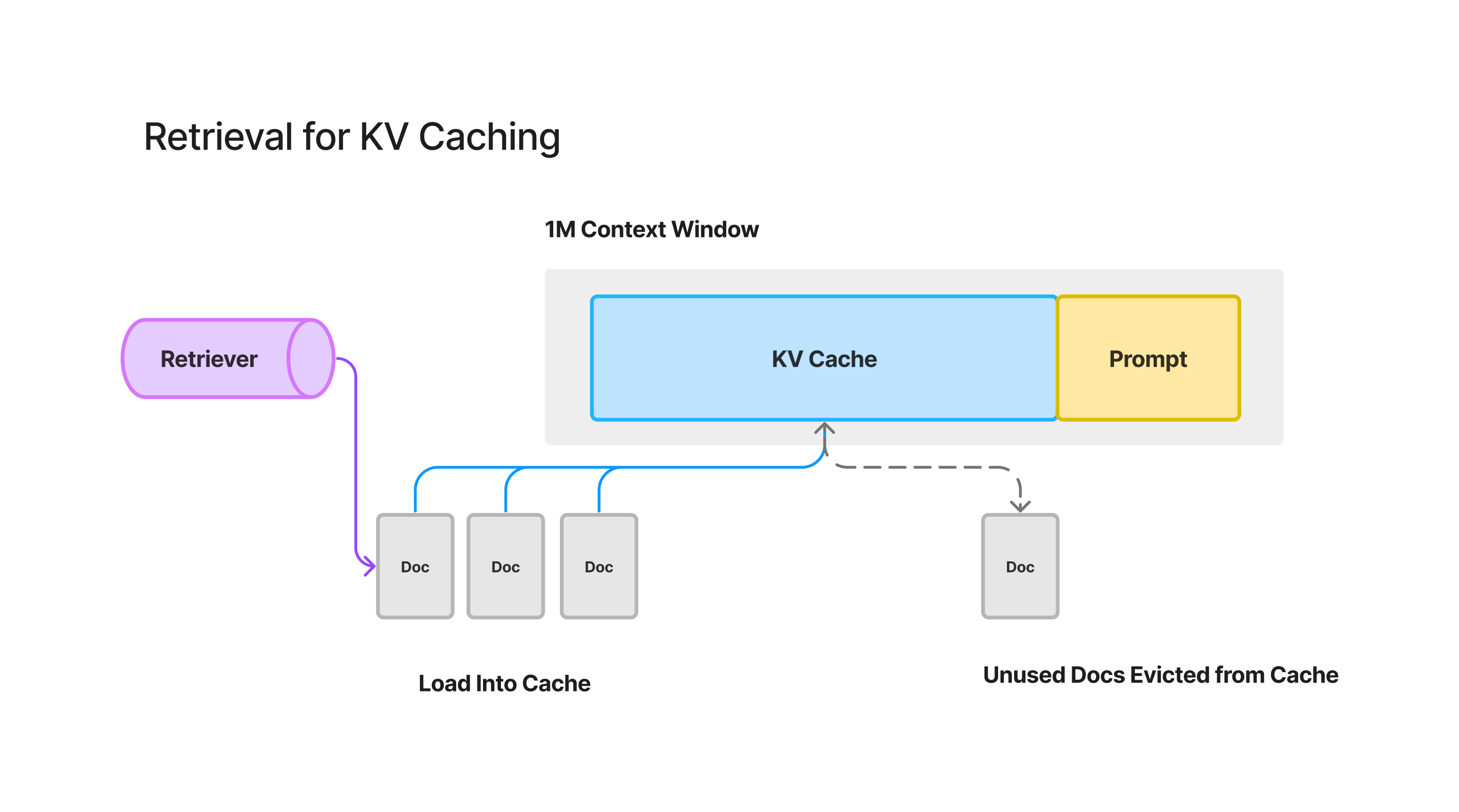
通过使用 KV 缓存来缓存上下文窗口中所有文档的 tokens,可以避免在后续对话中重新计算这些 tokens 的激活,从而大幅降低延迟和成本。
但这也引出了一些关于如何最佳利用缓存的有趣的检索策略,特别是对于超出上下文长度的知识库。我们设想了一种“检索增强缓存”的范式,旨在检索用户希望回答的最相关文档,预期他们将继续利用缓存中的文档。
这可能涉及将检索策略与传统缓存算法(如LRU缓存)结合。但与现有的 KV 缓存架构不同,位置是非常重要的,因为缓存的向量是基于所有前导 token 的,而不仅仅是文档本身的 token。这意味着,你不能简单地从 KV 缓存中移除一个块而不影响其后位置的所有缓存 token。
总的来说,如何使用 KV 缓存的 API 接口还在探索中。KV 缓存本身的性质是否会演化,或者算法将如何发展以最佳利用缓存,目前还不清楚。
接下来的展望
我们坚信大语言模型应用的未来非常光明,我们很高兴能够站在这个快速发展领域的前沿。我们邀请开发者和研究人员加入我们,一起探索长上下文大语言模型的潜力,并共同打造下一代智能应用。