本文介绍了 Unsloth 的一项新功能,该功能使用户能够在本地训练自己的 R1 推理模型。这项创新利用 Group Relative Policy Optimization (GRPO) 算法,显著降低了训练推理模型所需的 VRAM,使得在消费级 GPU 上,如仅需 7GB VRAM 的情况下,复现 DeepSeek R1-Zero 的 “顿悟时刻” 成为可能。Unsloth 旨在让更多开发者能够便捷地将标准模型转化为具备完整推理能力的模型,并应用于定制化奖励模型和自动生成推理过程等多种场景。此外,Unsloth 还集成了 vLLM,进一步提升了吞吐量并降低了 VRAM 消耗,为用户提供更高效的微调和推理体验。
- GRPO 算法引入 Unsloth: Unsloth 基于 DeepSeek R1 的研究,在自身平台中引入了 GRPO 算法,使用户能够训练模型自主学习分配更多思考时间,无需人工反馈。
- VRAM 效率提升: Unsloth 优化了 GRPO 流程,使其 VRAM 占用比 Hugging Face + FA2 减少 80%,仅需 7GB VRAM 即可在 Qwen2.5 (1.5B) 模型上复现 R1-Zero 的 “顿悟时刻”。
- 广泛的模型兼容性: Unsloth 支持将参数量高达 150 亿的模型(如 Llama 3.1 (8B), Phi-4 (14B), Mistral (7B), Qwen2.5 (7B))转化为推理模型。
- 突破性进展: 相较于 Tiny-Zero 团队使用 2 个 A100 GPU (160GB VRAM) 实现类似效果,Unsloth 仅需 7GB VRAM 即可达到相同的 “顿悟时刻”。此外,GRPO 在 Unsloth 中不仅支持全量微调,也支持 QLoRA 和 LoRA。
- GRPO 的应用场景: GRPO 技术可用于创建定制化奖励模型(如法律、医学领域),并能从输入输出数据中自动生成推理过程,无需预先准备推理链数据。
- “顿悟时刻” 原理: GRPO 算法通过强化学习,使模型在没有人工干预的情况下,学会延长思考时间并重新评估初始方法,从而实现自主推理能力的提升。
- Unsloth 中 GRPO 的实践建议: 使用 Unsloth 进行本地 GRPO 训练需安装
diffusers,并建议至少训练 300 步以上以观察奖励提升,使用最新版 vLLM。为获得良好效果,建议训练至少 12 小时。推荐使用参数量不小于 15 亿的模型,并为基础模型配置聊天模板。Unsloth 内置了训练损失跟踪功能。 - 其他强化学习方法支持: Unsloth 还支持 Online DPO, PPO 和 RLOO 等其他基于生成的强化学习方法。
- Unsloth 与 vLLM 集成优势: 集成 vLLM 后,吞吐量提升 20 倍,VRAM 节省 50%。在 1 个 A100 40GB GPU 上,使用 Unsloth 动态 4bit 量化的 Llama 3.2 3B Instruct 模型,预计可达 4000 tokens / s 的吞吐量。同时,Unsloth 优化了内存管理,减少了与 vLLM 共同加载时的双倍内存占用。
- vLLM 在 Unsloth 中的发现: vLLM 可以加载 Unsloth 动态 4-bit 量化模型,自动选择参数以优化 RAM、VRAM 效率和吞吐量,默认启用 -O3 优化和前缀缓存,并加速了 LoRA 加载过程。
原文
今天,我们很高兴地宣布 Unsloth 引入了推理功能!DeepSeek 的 R1 研究揭示了一个“顿悟时刻”,即 R1-Zero 通过群体相对策略优化 (Group Relative Policy Optimization, GRPO) 自主学习分配更多思考时间,而无需任何人工反馈。 我们优化了整个 GRPO 流程,相比 Hugging Face + FA2 减少了 80% 的显存 (VRAM) 使用。 这让您仅需 7GB 显存,就能使用 Qwen2.5 (1.5B) 复现 R1-Zero 的“顿悟时刻”。 试试我们的免费 GRPO notebook:在 Colab 上的 Llama 3.1 (8B) 示例 ❤️ 附:感谢大家上周对我们的 R1 Dynamic 1.58-bit GGUF 的喜爱,别忘了 ⭐给我们的项目点个 Star:github.com/unslothai/unsloth
想要体验包含 Phi-4 (14B) 等其他模型的 GRPO notebook,请访问我们的文档
💡 主要细节
- 只需 15GB 显存 (VRAM),Unsloth 就能将任何参数量高达 150 亿 (15B) 的模型(例如 Llama 3.1 (8B)、Phi-4 (14B)、Mistral (7B) 或 Qwen2.5 (7B))转化为推理模型。
- 最低要求:仅需 7GB 显存 (VRAM) 即可在本地训练您自己的推理模型。
- Tiny-Zero 团队证明,您可以使用 Qwen2.5 (1.5B) 实现自己的“顿悟”时刻,但这需要 2 块 A100 GPU(总计 160GB 显存)。现在,借助 Unsloth,您只需一块 7GB 显存的 GPU 就能实现同样的效果!
- 以前,GRPO 仅支持完全微调,但现在我们使其也能与 QLoRA 和 LoRA 协同工作。
- 请注意,这里说的不是微调 DeepSeek 的 R1 蒸馏模型,也不是使用 R1 的蒸馏数据进行调整(Unsloth 已经支持这些)。 我们指的是使用 GRPO 将一个普通模型转化为功能完备的推理模型。
- GRPO 的用例包括:如果您想创建一个具有特定奖励机制的定制模型(例如,用于法律或医学领域),GRPO 将会很有帮助。
如果您有输入和输出数据(例如问题和答案),但缺乏中间的思维链或推理过程,GRPO 能够神奇地为您补全推理过程! 还有更多应用等待探索。
🤔 GRPO + “顿悟”时刻
DeepSeek 的研究人员在使用纯强化学习 (Reinforcement Learning, RL) 训练 R1-Zero 时,观察到了“顿悟时刻”。模型学会了通过重新评估其初始方案来延长思考时间,而无需任何人为指导或预定义的指令。 在一个测试用例中,即使我们仅使用 GRPO 对 Phi-4 进行了 100 步的训练,结果也已经非常明显。 未使用 GRPO 训练的模型缺少“思考 Token”,而使用 GRPO 训练的模型则具备,并且答案也正确。 这种“魔法”可以通过 GRPO 实现。 GRPO 是一种强化学习算法,能够有效优化模型响应,且无需像近端策略优化 (Proximal Policy Optimization, PPO) 那样依赖价值函数 (Value Function)。 在我们的 notebook 中,我们使用 GRPO 训练模型,目标是使其自主发展自我验证和搜索能力,从而创造一个迷你“顿悟时刻”。
这种“魔法”可以通过 GRPO 实现。 GRPO 是一种强化学习算法,能够有效优化模型响应,且无需像近端策略优化 (Proximal Policy Optimization, PPO) 那样依赖价值函数 (Value Function)。 在我们的 notebook 中,我们使用 GRPO 训练模型,目标是使其自主发展自我验证和搜索能力,从而创造一个迷你“顿悟时刻”。
工作原理如下:
- 模型生成一组响应。
- 根据正确性或其他指标对每个响应进行评分,这些指标由设定的奖励函数 (而非大语言模型 (Large Language Model, LLM) 的奖励模型) 确定。
- 计算该组响应的平均分。
- 将每个响应的得分与该组的平均分进行比较。
- 模型受到强化,从而倾向于选择得分更高的响应。
举例来说,假设我们希望模型解决以下问题: 最初,人们需要收集大量数据来填充计算过程/思维链。 但 GRPO(DeepSeek 使用的算法)或其他强化学习算法可以引导模型自动展现推理能力并生成推理轨迹。 相应地,我们需要设计出色的奖励函数或验证器。 例如,如果答案正确,则给予 1 分;如果出现拼写错误,则扣除 0.1 分。 我们可以提供许多这样的函数来指导模型的学习过程。
1+1 等于多少? >> 思维链/计算过程 >> 答案是 2。
2+2 等于多少? >> 思维链/计算过程 >> 答案是 4。
🦥 Unsloth 中的 GRPO
如果在本地将 GRPO 与 Unsloth 结合使用,请先运行 “pip install diffusers”,因为这是一个依赖项。 至少等待 300 步,奖励才会开始增加。 此外,请使用最新版本的 vLLM (一种用于加速 LLM 推理的库)。 请记住,我们在 Colab 上的示例仅训练了一个小时,因此结果可能不太理想。 为了获得更好的结果,您需要训练至少 12 小时(这是 GRPO 的工作方式),但这并非强制性的,您可以随时停止训练。 建议将 GRPO 应用于参数量至少为 15 亿 (1.5B) 的模型,以确保正确生成思考 Token (用于引导模型进行推理的特殊 Token),因为较小的模型可能无法做到这一点。 如果您使用的是基础模型,请确保您已准备好聊天模板。 用于 GRPO 的训练损失跟踪功能现在已直接集成到 Unsloth 中,无需 wandb 等外部工具。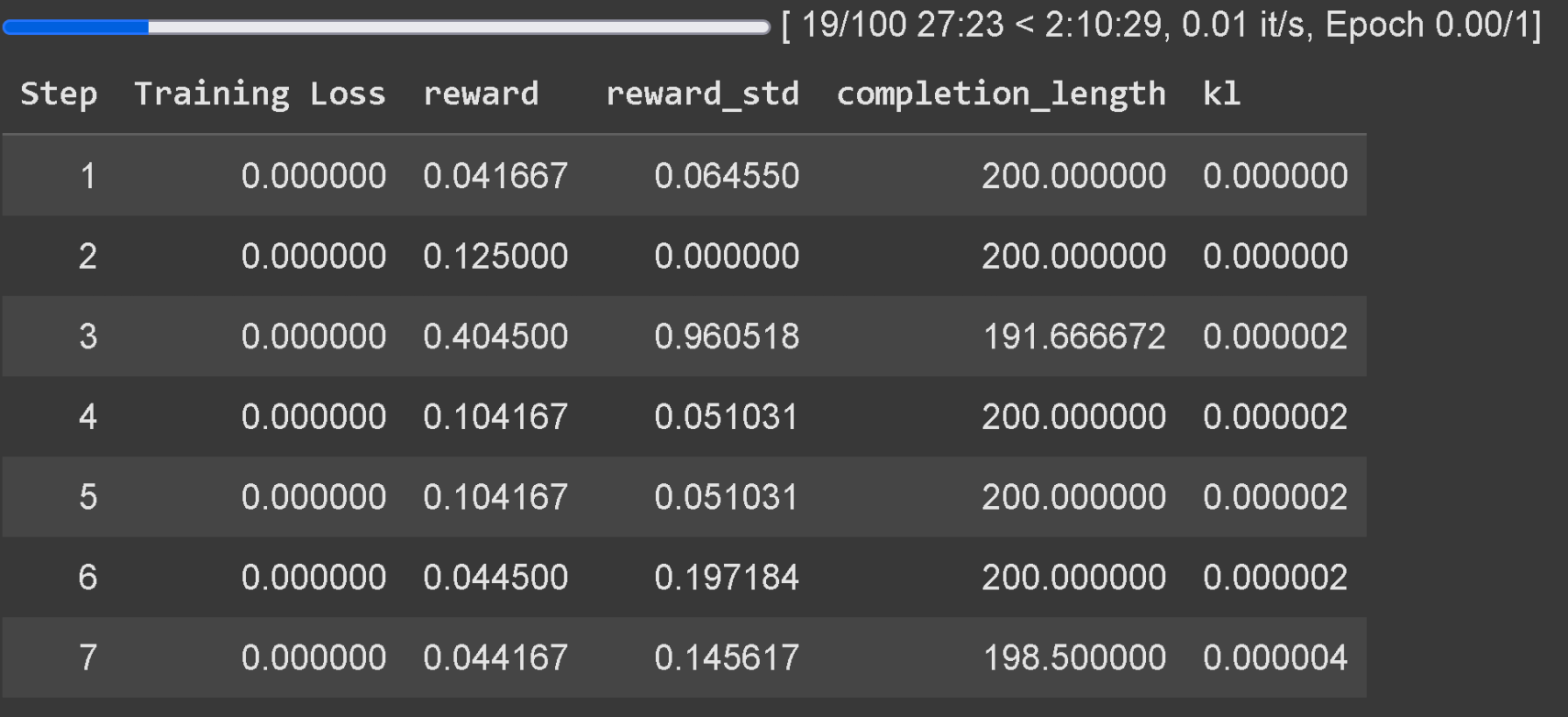 除了 GRPO 支持外,我们还增加了对 Online DPO、PPO 和 RLOO 的支持! 更多详细信息请参阅 Keith 的博文和 博客,其中包含关于他如何实现 Online DPO 的 Github 分支。 您可以在 Joey 的推文中找到 GRPO 在 Google Colab 上的初始修改草案! 他们的贡献使我们能够支持其他基于生成的强化学习方法。 下图比较了 Unsloth 的 Online DPO 显存 (VRAM) 消耗与标准 Hugging Face + FA2 的消耗。
除了 GRPO 支持外,我们还增加了对 Online DPO、PPO 和 RLOO 的支持! 更多详细信息请参阅 Keith 的博文和 博客,其中包含关于他如何实现 Online DPO 的 Github 分支。 您可以在 Joey 的推文中找到 GRPO 在 Google Colab 上的初始修改草案! 他们的贡献使我们能够支持其他基于生成的强化学习方法。 下图比较了 Unsloth 的 Online DPO 显存 (VRAM) 消耗与标准 Hugging Face + FA2 的消耗。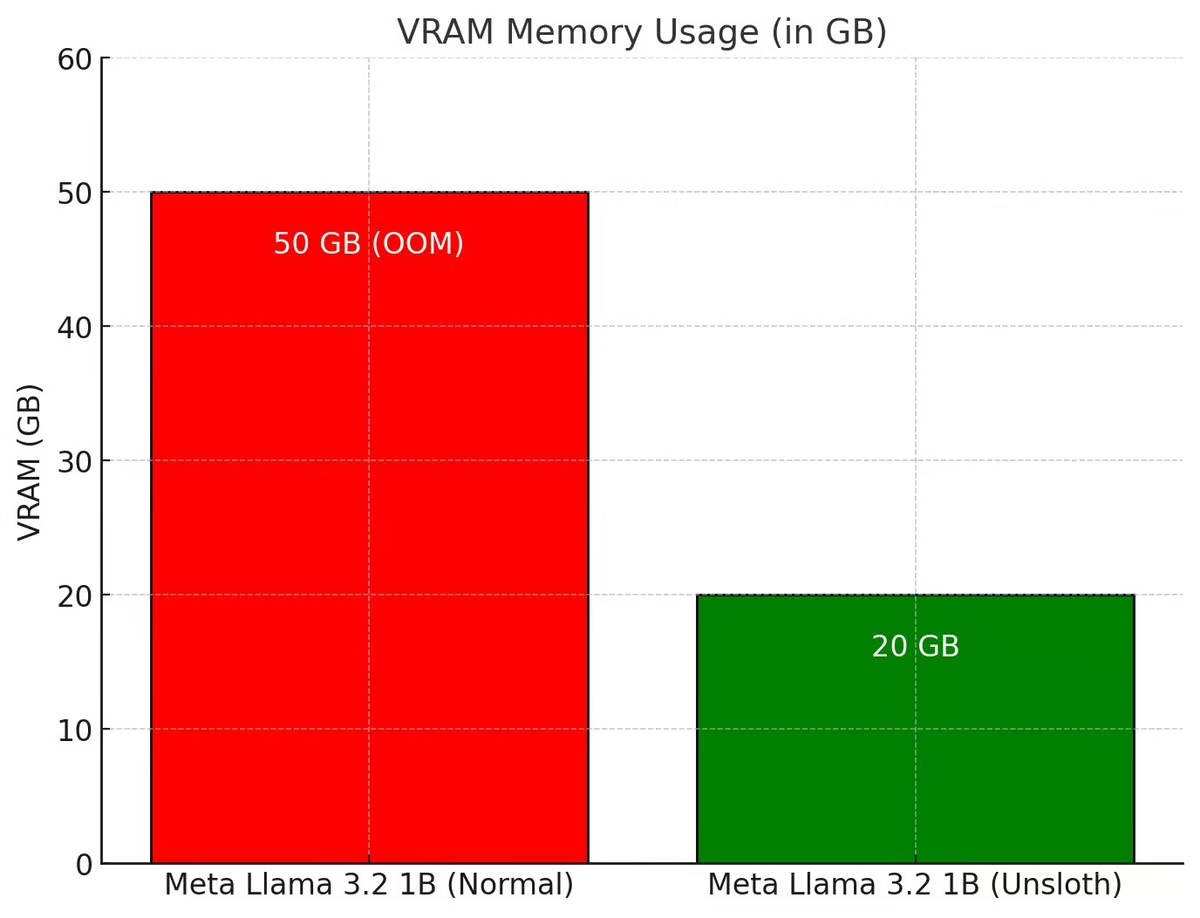
✨ Unsloth x vLLM
吞吐量提高 20 倍,显存 (VRAM) 节省 50%:
您现在可以直接在微调流程中使用 vLLM (一种用于加速 LLM 推理的库),从而实现更高的吞吐量,并允许您同时对模型进行微调和推理! 在单张 A100 40GB 显卡的配置下,使用 Unsloth 的 Llama 3.2 3B Instruct 模型的动态 4bit 量化,预计可达到 4000 Token/秒 的处理速度。 在 16GB Tesla T4 显卡(免费 Colab GPU)上,您可以获得 300 Token/秒的速度。 我们还巧妙地避免了同时加载 vLLM 和 Unsloth 时的双重内存占用,从而为 Llama 3.1 8B 模型节省了约 5GB 显存,为 Llama 3.2 3B 模型节省了 3GB 显存(感谢 Boris 提供的灵感)。 最初,Unsloth 可以在单张 48GB 显卡的 GPU 上微调 Llama 3.3 70B Instruct 模型,其中 Llama 3.3 70B 模型的权重就占用了 40GB 显存。 如果我们不消除双重内存占用问题,那么同时加载 Unsloth 和 vLLM 将需要 80GB 以上的显存。 但有了 Unsloth,您仍然可以在不到 48GB 显存的情况下进行微调,并享受快速推理带来的好处! 要使用快速推理功能,请先安装 vllm,然后使用 fast_inference 标志实例化 Unsloth:
pip install unsloth vllm
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Llama-3.2-3B-Instruct",
fast_inference = True,
)
model.fast_generate(["Hello!"])
Unsloth 中 vLLM 的新发现
- vLLM 现在可以加载 Unsloth 动态 4-bit 量化模型。 就像我们的 1.58bit Dynamic R1 GGUF 模型一样,我们发现将某些层动态量化为 4-bit,而将另一些层量化为 16-bit 可以显著提高准确性,同时保持模型体积较小。
- 我们会自动选择多个参数,以兼顾内存 (RAM)、显存 (VRAM) 效率和最大吞吐量(例如,分块预填充 Token 的数量、最大序列数等)。 我们默认在 vLLM 中启用 -O3 优化并启用前缀缓存。 我们发现,在较旧的 GPU 上,Flashinfer 实际上会降低 10% 的速度。 FP8 KV 缓存会使速度降低 10%,但会使吞吐量潜力翻倍。
- 我们允许通过解析状态字典 (state dict) 而非从磁盘加载的方式,在 vLLM 中加载 LoRA 模型 —— 这可以使您的 GRPO 训练速度提高 1.5 倍。 目前一个活跃的研究领域是如何以某种方式直接编辑 vLLM 中的 LoRA 适配器(我还不确定具体方法)。 这可以显著提高速度,因为我们目前执行了不必要的 GPU 数据移动。
- vLLM 偶尔会出现随机的显存 (VRAM) 峰值,尤其是在批量生成期间。 我们添加了一个批量生成函数来减少内存峰值。
💕 感谢!
衷心感谢 Keith、Edd、Datta、MrDragonFox 和 Joey 在本项目中提供的宝贵帮助。 当然,还要感谢 Hugging Face 的出色团队(特别是 TRL 团队)、vLLM 团队以及开源社区,感谢他们为实现这一目标做出的贡献。 与往常一样,非常感谢大家使用和分享 Unsloth。 🙏欢迎加入我们的 Reddit 社区和 Discord 服务器,获取帮助或表达您的支持! 您还可以关注我们的 Twitter 和 新闻邮件。
感谢阅读!
Daniel & Michael Han 🦥
2025 年 2 月 6 日